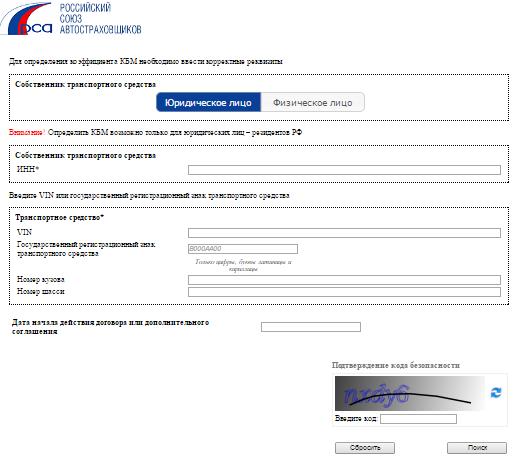
СОГАЗ: клиент — это не человек – отзыв о страховой компании СОГАЗ
05.02.2020 обратился на сайт страховой копании СОГАЗ для продления полиса ОСАГО. В личный кабинет сайт не позволил войти в течении полутора часа. В этот же день обратился в поддержку, на сайте компании указав причину. Ответ пришел на телефон в виде СМС только через сутки!!!06.02.2020 в личном кабинете данного сайта заполнив требующие данные стал пытаться отправлять данные через сайт. Не все так просто, на сайте надо в вести секретные символы… Секретные символы, не читаемые человеческим глазом, сайт принимает с 10 – 15 раза отвечая, что “неверные символы”. Умудрившись все таки впихнуть чудо символы в коробку, через 5 минут приходит ответ, «ответ от РСА не получен» и так пять — восемь раз . Сначала шаманские действия с секретным кодом, потом отказ.
Через некое время, около двадцати минут после последней подачи, приходит ответ, что данные прикрепленные не точные, водитель, тот на кого ранее оформлялась страховка нет в РСА, отредактируйте, пришлите снова.
Продолжаем снова подгружать те документы, которые были загружены ранее, дополнять старую информацию, начинаем снова танцы с бубнами перед секретными символами и снова отправляем, теперь ответ придет через 15 -20 минут. И снова ответ, «ответ от РСА не получен». И так далее и все по той же схеме.
В результате танца с бубнами через пять часов приходит финишное заявление: “Уважаемый клиент! В соответствии с Указанием Банка России № 4190-У процедура заключения договора ОСАГО не может быть продолжена в связи с тем, что электронные копии документов, необходимые для заключения договора ОСАГО, предоставленные Вами по истечению 3 часов с момента направления Вам уведомления о непрохождении проверки в АИС ОСАГО и необходимости предоставить электронные копии документов.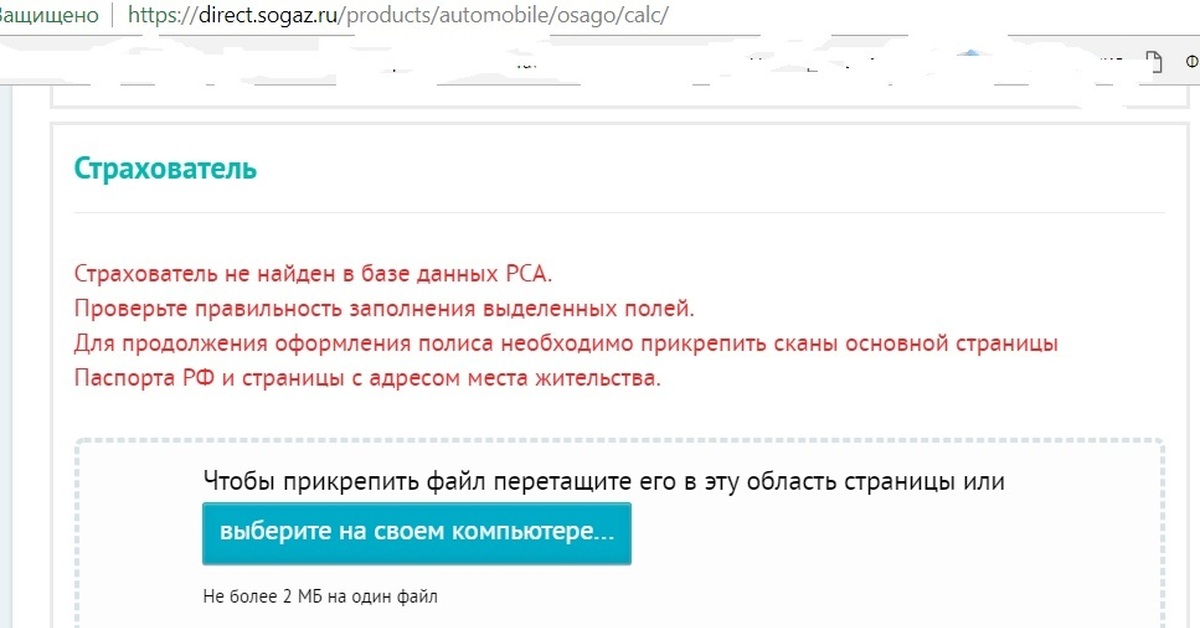 ”
”
Не уж то страховым компания все по одному месту или у нас совсем не работают, без действуют контролирующих органы Банка РФ, ФАС, РСА, Роспотребнадзор, Прокуратуры? Попытка еще раз на следующий день, не к чему не привела, все то же самое. Обращение в тех поддержку тоже безрезультатно, прошло четверо суток, ответа нет!
Вопрос-ответ — СК «Надежда»
Вопрос
19.01.2017
При регистрации в личном кабинете или при заполнении паспортных данных собственника транспортного средства получил уведомление о недействительности паспорта. Что делать в этом случае?
Развернуть ответ
Сообщение о недействительности паспорта сформировалось после проверки данных по базе МВД России. Обратитесь в территориальное отделение Управления по вопросам миграции МВД России для изменения данных о статусе паспорта, в случае если данные МВД России некорректны.

Вопрос
18.01.2017
Почему действие е-ОСАГО начинается только на следующий день за днем заключения договора?
Развернуть ответ
Это предусмотрено действующим законодательством.
Вопрос
Что делать, если меня остановит ГИБДД?
Развернуть ответ
Распечатайте заранее файл электронного полиса на принтере и возите с собой.
Ездить с распечатанным полисом законно! ГИБДД проверяет действительность вашего полиса по базе РСА. Вы сами можете проверить действительность своего полиса на сайте РСА, воспользовавшись специальным сервисом.
Вместе с полисом на электронную почту мы присылаем памятку ваших действий в случае ДТП.
Вопрос
18.01.2017
Нужно ли заверять печатью электронный полис? Зачем нужна электронная подпись?
Развернуть ответ
Электронное ОСАГО — это оригинал вашего полиса.
1. Распечатайте файл электронного полиса на принтере и возите с собой в машине.
2. Распечатанный полис НЕ нужно заверять печатью или подписью в офисе!
3. Его не обязательно нужно обменивать на бумажный полис в офисе.
Вместо печати и подписи электронное ОСАГО заверяет электронная подпись, код подтверждения приходит на ваш телефон.
Вопрос
18.01.2017
Как оформить е-ОСАГО, если транспортное средство зарегистрировано за рубежом?
Развернуть ответ
Оформить онлайн ОСАГО на транспортное средство, зарегистрированное не в РФ, в электронном виде невозможно. Пожалуйста, обратитесь в офис страховой компании.
Вопрос
18.01.2017
Как происходит покупка ОСАГО онлайн?
Развернуть ответ
1. Регистрируетесь в личном кабинете.
2. Заполняете все данные для расчета в онлайн-калькуляторе:
на транспортное средство,
на собственника ТС,
на лиц, допущенных к управлению
3. Подтверждаете проект договора простой электронной подписью (вводите код, отправленный с сайта на ваш номер сотового телефона).
Подтверждаете проект договора простой электронной подписью (вводите код, отправленный с сайта на ваш номер сотового телефона).
4. Оплачиваете покупку банковской картой.
5. Получаете полис и сопроводительные документы на email.
18.01.2017
Период действия страхового полиса заканчивается через месяц. Оформлял на 3 месяца в печатном виде. Могу ли я продлить этот страховой полис онлайн?
Развернуть ответ
Нет, продлить период использования можно только в случае, если полис ОСАГО выписан онлайн, и только в той компании, в которой его оформляли.
Для продления бумажного полиса необходимо обратиться в офис Вашей страховой компании.
Вопрос
18.01.2017
Я все забиваю правильно, почему возникают ошибки?
Что делать?
Развернуть ответ
Ошибки возникают по причине несовпадения данных пользователя в калькуляторе и в данных, которые находятся в АИС РСА.
Если вы впервые оформляете полис, вам необходимо также отправить фотографии машины (при наличии), и сканированные изображения СТС, ДК, на указанный адрес. Оператор проверит данные, скорректирует информацию в базе данных, и вы сможете оформить договор на сайте.
Вопрос
18.01.2017
Ошибки, не пускает далее, что делать?
Развернуть ответ
Главное правило: введенные вами данные о водителях, автомобиле, собственнике должны полностью совпадать с данными, которые содержатся в системе РСА.
1. Убедитесь, что вы правильно заполнили все данные заявления на страхование (проверьте опечатки, даты, адреса).
2. Если все необходимые условия оформления страховки выполняются, но вы все равно видите ошибку, РЕКОМЕНДУЕМ отправить на почту [email protected] скан-копии документов, подтверждающие введенную вами информацию, и скриншот с экрана монитора. Данные будут проверены сотрудником техподдержки, и вы сможете оформить договор на сайте.
Вопрос
18.01.2017
Что нужно, чтобы оформить е-полис?
Развернуть ответ
Для оформления электронного полиса ОСАГО Вам понадобится:
• Паспорт собственника транспортного средства
• Паспорт страхователя
• Сканированные изображения или фотографии документов (в том случае, если представленные страхователем сведения не соответствуют информации, содержащейся в АИС РСА или отсутствуют в ней)
• Фотографии транспортного средства (при наличии)
• Банковская карта на имя страхователя
ВНИМАНИЕ! САО «Надежда» вправе взыскать со страхователя сумму страховой выплаты в порядке регресса в случае предоставления страховщику недостоверных сведений, приведших к необоснованному уменьшению размера страховой премии.
Вопрос
18.01.2017
Развернуть ответ
За каждый год безаварийной езды начисляется скидка 5%. Таким образом, максимальный размер скидки за 10 лет страхования может составить 50%.
На нашем сайте вы можете проверить свой КБМ и страховой класс.
Вопрос
18.01.2017
Я купил б/у автомобиль, у которого нет ни талона ТО, ни ОСАГО. Могу ли я доехать до оператора ТО без полиса ОСАГО?
Развернуть ответ
Владельцы транспортных средств обязаны застраховать свою гражданскую ответственность до регистрации транспортного средства, но не позднее чем через 10 дней после возникновения права владения им. Таким образом, в течение 10 дней можно доехать до пункта технического осмотра без полиса ОСАГО, пройти технический осмотр приобретенного транспортного средства, после чего заключить договор ОСАГО.
Вопрос
18. 01.2017
01.2017
Могу ли я оформить ОСАГО по временной регистрации?
Развернуть ответ
Да, если у вас нет постоянной регистрации в РФ. Если постоянная регистрация имеется, при расчете ОСАГО будет учитываться именно этот региональный коэффициент.
Вопрос
18.01.2017
Когда пора продлевать ОСАГО?
Развернуть ответ
Продлить ОСАГО лучше до истечения текущего полиса, чтобы не было перерывов в страховании.
Продлить полис можно не ранее, чем за 2 месяца (60 дней) до истечения предыдущего ОСАГО.
Напоминаем, что за просроченную страховку ОСАГО и за езду без полиса полагается штраф.
Вопрос
18.01.2017
Хочу период страхования указать не на 1 год, а на определенный период. Как это сделать?
Развернуть ответ
Чтобы застраховаться на срок менее 1 года, выберите в настройках онлайн-калькулятора период использования автомобиля на первом шаге «На 1 год. Транспортное средство может использоваться только в указанные периоды» Срок страхования при этом останется равным 1 году, но период использования полиса будет скорректирован в соответствии с выбранным вами сроком.
Вопрос
18.01.2017
Где брать извещение о ДТП при покупке полиса е-ОСАГО?
Развернуть ответ
Извещение о ДТП отправляется в электронном виде вместе с полисом в виде ссылки на скачивание.
Достаточно скачать PDF-файл, распечатать и возить с собой вместе с пакетом документов.
Вопрос
18.01.2017
Нужно ли показывать сотруднику ГИБДД электронный полис?
Развернуть ответ
Мы рекомендуем распечатать полученный на email электронный полис и список законных оснований для страхования в электронной форме и всегда иметь эти документы при себе в момент управления автомобилем!
Наряды ДПС могут проверять онлайн наличие электронного полиса ОСАГО через сеть ИМТС МВД России или сайт РСА.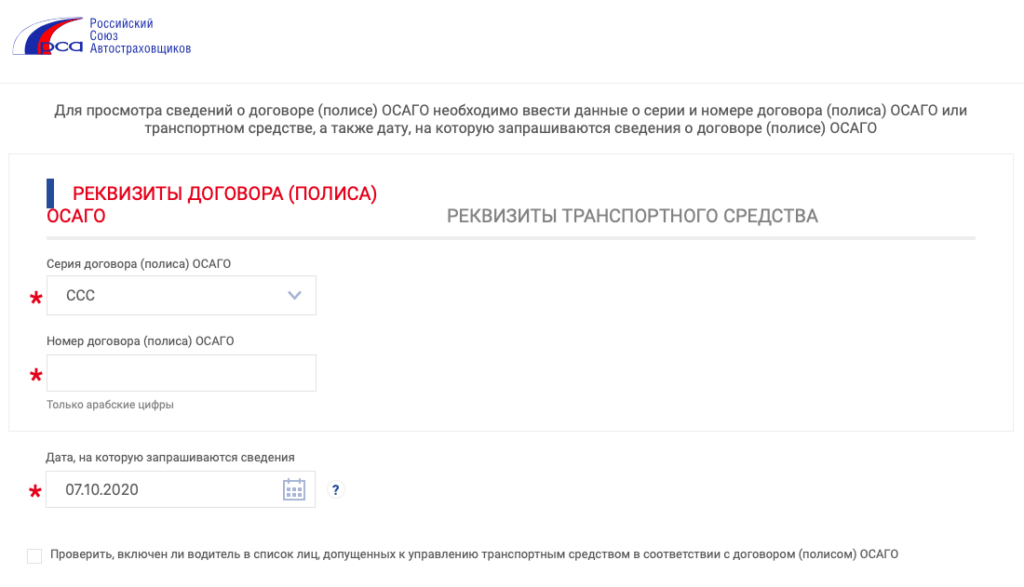 При наличии в информационной системе сведений о заключении такого договора они обязаны исключить привлечение водителя к административной ответственности по части 2 статьи 12.3 КоАП РФ*
При наличии в информационной системе сведений о заключении такого договора они обязаны исключить привлечение водителя к административной ответственности по части 2 статьи 12.3 КоАП РФ*
*Согласно письму ГУОБДД МВД России от 03.07.2015 № 13/12-у-4440 Начальнику ЦСН БДД МВД России, начальникам подразделений ГАИ на региональном уровне «Об изменениях в законодательстве Российской Федерации».
Вопрос
18.01.2017
Каков порядок расторжения договора ОСАГО, оформленного в электронном виде?
Развернуть ответ
Расторжение электронного договора ОСАГО возможно только в офисе страховщика. Для расторжения договора необходимо обратиться в любой офис страховщика с заявлением о расторжении договора, документом, удостоверяющим личность и документами, подтверждающими основания для расторжения договора.
Вопрос
18.01.2017
Как можно проверить подлинность электронного полиса ОСАГО?
Развернуть ответ
Вопрос
18. 01.2017
01.2017
Нужна ли диагностическая карта (техосмотр, ТО) для оформления электронного ОСАГО?
Развернуть ответ
Диагностическая карта требуется для легковых транспортных средств, не используемых в качестве такси, старше 3 лет, включая год выпуска. Если Ваше транспортное средство старше трех лет и у Вас нет действующей на дату заключения договора диагностической карты, то для заключения договора ОСАГО сначала необходимо пройти техосмотр. Обращаем внимание на то, что три года исчисляются с 1 января года изготовления транспортного средства и не зависят от даты его покупки или даты выдачи ПТС. Данные о наличии действующей ДК страховые компании также получают из АИС РСА.
Вопрос
18.01.2017
Страховая история, моя скидка за безаварийное вождение (коэффициент бонус-малус — КБМ) при оформлении электронного ОСАГО применяется?
Развернуть ответ
При оформлении полиса ОСАГО (в любом виде) применяется коэффициент, соответствующий страховой истории, содержащейся в автоматизированной информационной системе РСА (Российского союза автостраховщиков). Поэтому скидки за безаварийное вождение (если информация о них содержится в РСА), будут применены. Информация о новом договоре ОСАГО, заключенном в электронном виде, будет также передана в РСА.
Поэтому скидки за безаварийное вождение (если информация о них содержится в РСА), будут применены. Информация о новом договоре ОСАГО, заключенном в электронном виде, будет также передана в РСА.
Вопрос
18.01.2017
Почему бланк е-ОСАГО не розовый, а черно-белый?
Развернуть ответ
«Полис ОСАГО в электронном виде при его оформлении сразу передается в единую базу договоров ОСАГО в РСА. На сайте РСА информацию по полису можно увидеть уже через час. Сотрудники полиции при проверке действительности полиса ОСАГО будут руководствоваться сведениями из единой базы РСА. Взамен электронного полиса ОСАГО страховщик в любое время может выписать полис на розовом бланке. Для этого надо обратиться в ближайший офис САО «Надежда» или направить заявку на направление полиса почтой на электронную почту. Направление полиса почтой производится за счет клиента».
Вопрос
18.01.2017
Отличается ли стоимость полиса ОСАГО, оформленного на бумажном бланке строгой отчетности от оформленного онлайн?
Может ли в разных страховых компаниях стоимость одного и того же полиса отличаться?
Развернуть ответ
Тарифы по договорам ОСАГО устанавливаются в соответствии с указаниями Банка России. Страховщики вправе самостоятельно устанавливать размеры базовой ставки при расчете стоимости ОСАГО в зависимости от территории преимущественного использования ТС, но с учетом минимальной и максимальной ставки, утвержденной Банком России.
Страховщики вправе самостоятельно устанавливать размеры базовой ставки при расчете стоимости ОСАГО в зависимости от территории преимущественного использования ТС, но с учетом минимальной и максимальной ставки, утвержденной Банком России.
О том, какой тариф конкретный страховщик будет применять, страховщик в обязательном порядке уведомляет Банк России. Устанавливать разные тарифы в зависимости от способа оформления полиса ОСАГО страховщики не вправе.
Таким образом, стоимость полиса ОСАГО у одного и того же страховщика, независимо от способа его оформления, отличаться не может. При этом стоимость полиса на одно и то же ТС у разных страховщиков может отличаться.
Вопрос
18.01.2017
Для оформления полиса ОСАГО онлайн физическим лицам требуется электронная подпись. Где ее можно оформить или получить?
Развернуть ответ
Для создания простой электронной подписи используется специальный ключ, который направляется страховщиком в виде смс-сообщения на сотовый номер телефона, который вы указываете при регистрации. Указанный ключ в целях безопасности каждый раз генерируется уникальный.
Указанный ключ в целях безопасности каждый раз генерируется уникальный.
Вопрос
18.01.2017
Страховая компания «Х», на сайт которой я обратился для оформления полиса ОСАГО онлайн, предложила мне оформить полис ОСАГО САО «Надежда». Я проживаю в субъекте РФ, где офисы САО «Надежда» отсутствуют. Подскажите, как поступить в этом случае?
Развернуть ответ
Право выбора страховой компании, где приобретать полис ОСАГО, безусловно, у потребителя. Вы вправе отказаться от приобретения полиса любой страховой компании, куда бы не перенаправляли Вас с сайта выбранного Вами страховщика.
На сайте выбранного Вами страховщика Вы можете обратиться с заявлением об отказе от передачи Ваших данных другой страховой компании и вправе потребовать выписать полис ОСАГО, в том числе в электронном виде.
Вопрос
18.01.2017
Страховая компания «Х», на сайт которой я обратился для оформления полиса ОСАГО онлайн, предложила мне оформить полис ОСАГО САО «Надежда». Я согласился, но при оформлении полиса на вашем сайте требуется вводить снова все данные. Могу ли я отказаться от вашего полиса и оформить полис ОСАГО в СК «Х»?
Я согласился, но при оформлении полиса на вашем сайте требуется вводить снова все данные. Могу ли я отказаться от вашего полиса и оформить полис ОСАГО в СК «Х»?
Зачем заполнять заново данные на сайте САО «Надежда», если я соглашаюсь оформить ваш полис?
Развернуть ответ
Право выбора страховой компании, где приобретать полис ОСАГО, безусловно, у потребителя. Вы вправе отказаться от приобретения полиса любой страховой компании, куда бы не перенаправляли Вас с сайта выбранного Вами страховщика.
В случае, если Вы согласились приобрести полис САО «Надежда» после того как заполнили сведения на сайте другого страховщика, заново заполнять эти сведения не требуется (если с Вашей стороны не было отказа от передачи сведений).
Вопрос
18.01.2017
Возможно ли приобрести полис ОСАГО онлайн на сайте САО «Надежда»?
Развернуть ответ
С 01.01.2017г. возможность приобретения полиса ОСАГО онлайн имеется на сайтах всех страховщиков, имеющих лицензию на ОСАГО, в том числе и в САО «Надежда».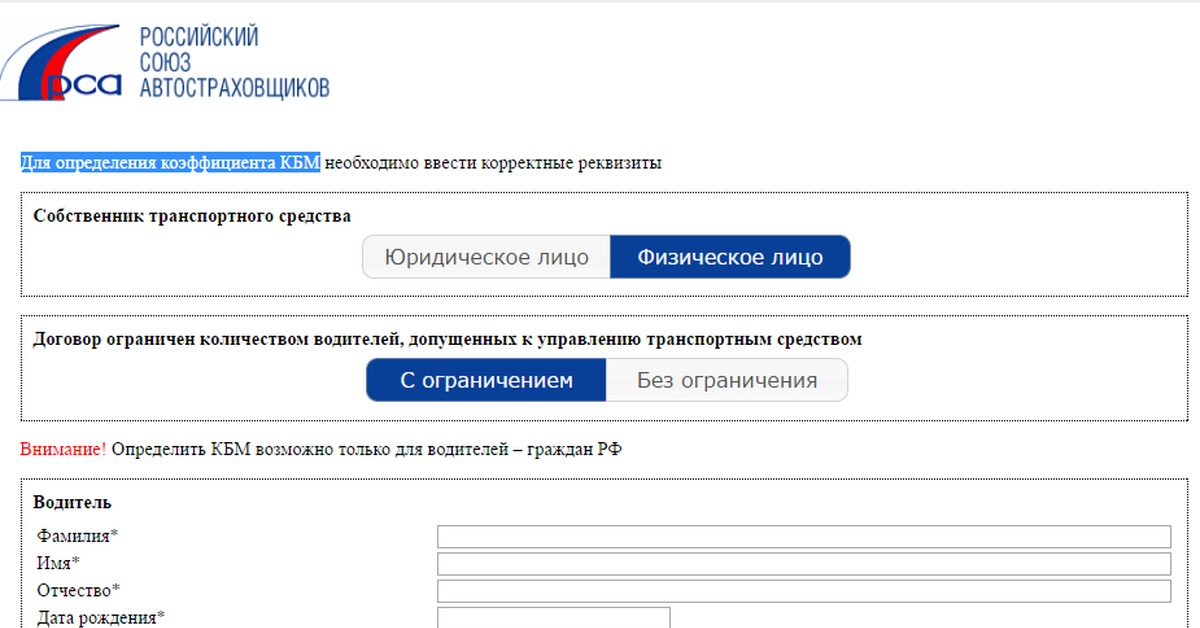
Вопрос
18.01.2017
Марка моего автомобиля отсутствует в списке на сайте САО «Надежда». Как оформить полис ОСАГО?
Развернуть ответ
Предлагаем направить сканы документов на электронную почту [email protected], чтобы мы могли связаться с Вами для оформления полиса.
Как выглядит электронный страховой полис ОСАГО и чем отличается от бумажного
Полис ОСАГО может быть оформлен как в бумажном, так и в электронном виде. Обе версии имеют равную юридическую силу и могут использоваться для оформления страхового случая. Страховщик имеет право выбрать, какой тип полиса он хочет оформить. Об основных отличиях электронного ОСАГО от бумажного.
Чем отличается электронный полис ОСАГО от бумажного
В первую очередь, электронный полис отличается от бумажного своим форматом. Он предоставляется в виде файла в формате PDF, подписанного электронной подписью страховщика. Электронный полис содержит те же данные и реквизиты, что и бумажный. Информация о нем в обязательном порядке заносится в базу АИС РСА.
Информация о нем в обязательном порядке заносится в базу АИС РСА.
Оформить электронное ОСАГО можно на сайте страховой компании. Для этого необходимо заполнить заявку на официальном сайте страховщика, загрузить скан-копии требуемых документов и оплатить стоимость страховки одним из доступных способов. Чтобы оформить электронный полис, вам потребуются стандартные документы — паспорт, ПТС и СТС, водительские удостоверения и диагностическая карта.
Какой полис дешевле
Электронный полис ОСАГО рассчитывается так же, как и бумажный. При его оформлении используются все установленные законом тарифы и коэффициенты — территориальный, КБМ, возраст-стаж, мощность автомобиля и другие. При оформлении такой страховки страховая компания не имеет права изменять их значения или вводить свои коэффициенты.
Стоимость страхового полиса не зависит от способа его оформления. Закон не устанавливает скидок или надбавок при оформлении электронного ОСАГО. Однако, страховщик может выбрать более крупный базовый тариф при оформлении е-ОСАГО. Перед оформлением страховки уточните тарифы интересующей вас страховой компании и рассчитайте стоимость страховки с помощью онлайн-калькулятора.
Что должно быть указано в Е-ОСАГО
Электронный полис ОСАГО оформляется на бланке серии ХХХ (для бумажных полисов используются бланки ККК и МММ). Цвет документа, как правило, оранжево-розовый, как и у бумажной версии. В отличие от бумажного полиса, в электронном не размещается QR-код для проверки документов.
Электронный полис содержит те же данные, что и бумажный:
- Размер страховой премии
- Сроки действия и периоды использования
- Сведения о страхователе
- Сведения о транспортном средстве и его собственнике
- Сведения о водителях и их количестве
- Сведения о размере страховой премии
- Сведения о страховых случаях
- Дату заключения договора
Также в документе ставится отметка о том, что полис является электронным, и о том, что он заверен электронной подписью страховщика.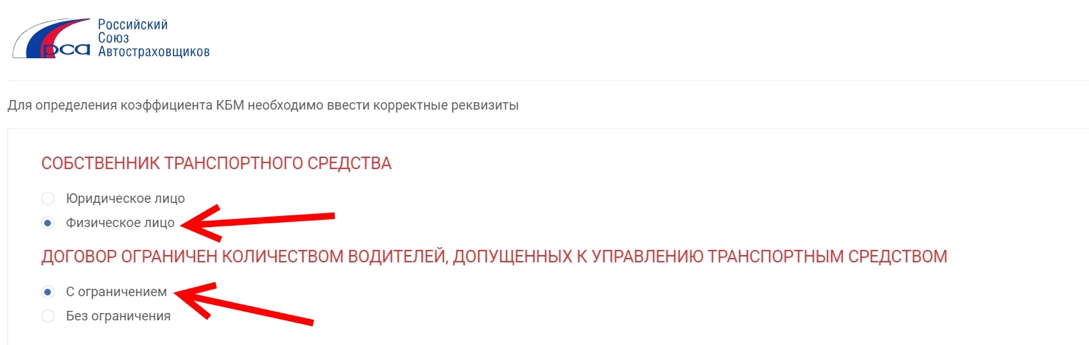
Как отличить фальшивый полис
При покупке е-ОСАГО есть шанс приобрести поддельный полис Такой документ не сможет защитить вашу ответственность в страховых случаях, а при его предъявлении вы рискуете получить не только штраф, но и наказание за подделку документов.
Отличить фальшивый полис ОСАГО можно как до покупки, так и после нее. Вначале обратите внимание на его цену — если страховка стоит заметно дешевле, чем в других страховых компаниях, то это может вызвать подозрения. Обратите внимание на сайт, где вы покупаете полис — он будет отличаться от официального сайта страховой компании. Изучите бланк и сравните его с образцом у выбранного вами страховщика — оформление и реквизиты в них могут отличаться.
После покупки проверьте наличие сертификата электронной подписи — по нему можно проверить подлинность документа. Некоторые страховщики высылают их вместе с полисом. Также после покупки подделки вам не придет подтверждение из РСА. При попытке найти фальшивый полис в официальной базе вы получите ошибку или сообщение о просроченном документе.
Как предъявить электронный полис ГИБДД
Электронный полис ОСАГО можно сохранить на любой смартфон или планшет с установленным приложением для просмотра PDF-файлов. Теперь, если сотрудник ГИБДД попросит вас предъявить полис, откройте документ на своем устройстве. Инспектор сможет проверить подлинность документа по внутренней базе — для этого сотрудникам ГИБДД выдаются рабочие планшеты с доступом в интернет.
Однако, многие инспекторы до сих пор не доверяют электронным документам и могут не признавать их. Также проблемы могут возникнуть в удаленных регионах с нестабильным или отсутствующим интернетом. Для этих случаев вы можете распечатать электронный полис и возить его с собой. Заверять распечатку у страховщика не нужно — достаточно, чтобы она была хорошо читаемой, и в ней присутствовали все требуемые данные.
Тем не менее, инспекторы часто продолжают штрафовать при попытке предъявить электронный полис. Такие штрафы неправомерны: вы имеете право обжаловать их через суд. Нужно будет подтвердить подлинность полиса информацией из РСА.
Нужно будет подтвердить подлинность полиса информацией из РСА.
Вопрос-ответ
Почему нельзя оформить е-ОСАГО при покупке новой машины?
Информации о новом автомобиле еще нет в базе РСА, поэтому оформить электронный полис для нее не получится. Купить первый полис ОСАГО для своей машины вы сможете только в офисе страховой компании.
Что делать, если электронный полис не был найден в базе?
Если страховка не обнаружена, то скорее всего, вы купили фальшивый полис или данные были внесены в РСА с ошибкой. Во втором случае необходимо обратиться к страховщику и выяснить причину. В случае некорректного занесения данных – внести исправления. Если страховая компания не имеет лицензии – придется приобрести новый ОСАГО в проверенной СК. Также вы можете сообщить страховой компании о мошеннике, который продает фальшивые полисы.
Электронный полис можно купить в любой компании или только в той, где уже приобретался бумажный?
Купить страховку онлайн можно как впервые в компании, так и при последующих обращениях. Главное – наличие соответствующей лицензии у страховщика.
Главное – наличие соответствующей лицензии у страховщика.
Источники
Как проверить КБМ по базе РСА
В процессе заключения ОСАГО, либо же продления такового, при расчете цены полиса используется коэффициент КБМ. Он может, как повысить, так и снизить цену полиса. Все будет зависеть от поведения водителя в рамках предыдущего периода. Если имели место аварии и производились страховые выплаты, показатель КБМ изменится не в пользу собственника транспорта. В случае, когда водитель придерживался аккуратной езды и не становился участником ДТП, коэффициент снижает стоимость ОСАГО.
КМБ актуализируется ежегодно. В своем максимальном значении достигает 0,5. Как правило, на такую скидку можно рассчитывать тем, кто имеет десятилетний стаж безаварийного вождения. Проверку скидки при оформлении документа можно осуществить на сайте РСА. Процесс бесплатный, но требует внесения личных данных заявителя.
Проверка КБМ на autoins. org, с возможностью восстановления
org, с возможностью восстановления
Чтобы быстро проверить КБМ по базе РСА, достаточно перейти на сервис autoins.org. С его помощью можно не только произвести оперативную проверку, но и инициировать возобновление КБМ.
Официальная проверка осуществляется в онлайн режиме. Для выполнения расчета нужно указать: ФИО, номер удостоверения, а также его серию, а ещё день, месяц и год рождения собственника транспорта. Если при выполнении расчета присутствует ошибка, можно подать заявку в базу РСА, чтобы получить шанс восстановить КБМ. На сайте присутствует таблица кбм 2020 года, что позволит произвести предварительные расчеты полагающейся скидки.
Данные для проверки КБМ юридическими лицами
Чтобы выполнить проверку коэффициентов ИП и юридическими лицами, нужно располагать следующими данными:
- ИНН владельца автомобиля;
- VIN-номера либо госномера регистрации ТС;
- номер кузова и шасси;
- дату документа на машину.

При заполнении полей с данными для проверки, обязательно учитывайте то, что здесь вводятся только буквы и цифры.
Сведения для проверки КМБ физическими лицами
Проверить КБМ по базе РСА собственнику ТС с договоров, в которых указано не ограниченное количество лиц, можно при внесении следующих данных:
- инициалы собственника ТС с датой рождения;
- тип удостоверения, включая серию и номер;
- VIN-номер или знак госрегистрации авто;
- номер кузова и шасси;
- дата срока активной реализации договора либо дополнительного соглашения.
Чтобы получить точные данные по использовании скидки при оформлении ОСАГО, нужно корректно вносить данные из последнего действующего договора. Если после проведения индивидуальных расчетов скидка является большей, в отличие от значений системы, необходимо перейти на страницу https://autoins.org/vosstanovit-kbm. Здесь можно подать заявку на старт процесса возобновления КБМ. Для этого заполняются указанные поля. Если производилась замена удостоверения, нужно указать данные предыдущих прав.
Для этого заполняются указанные поля. Если производилась замена удостоверения, нужно указать данные предыдущих прав.
При восстановлении корректного значения КБМ, затраты на перерасчёт будут получены только после согласия АИС РСА. Все выплаты и возврат средств, связанные с продлением полиса, производит Центробанк. Для чего нужно подтвердить факт переплаты.
На правах рекламы
Как проверить полис ОСАГО на подлинность?
В настоящее время полис ОСАГО можно проверить различными способами.
На сайте РСА (Российского Союза Автостраховщиков), данная организация выдает полисы страховым компаниям и отвечает за единую базу полисов ОСАГО, которая существует с 01.01.2013г.
На сайте страховой компании, у которой приобретается полис, если у них есть онлайн-сервис проверки или просто позвонив непосредственно в саму страховую компанию, имея на руках номер полиса, скан/оригинал. В настоящее время нельзя продать полис Осаго не занеся его в базу. Если раньше можно было выписать или напечатать страховку Осаго, отдать клиенту, а данные попадали в базу страховой компании только в течение нескольких недель-месяцев и это это считалось нормальным. То теперь данные заносятся онлайн через программу страховой компании и только потом из этой же программы печатается полис. А страховая компания в течение 5-20 минут уже передает всю необходимую информацию в единую базу.
В настоящее время нельзя продать полис Осаго не занеся его в базу. Если раньше можно было выписать или напечатать страховку Осаго, отдать клиенту, а данные попадали в базу страховой компании только в течение нескольких недель-месяцев и это это считалось нормальным. То теперь данные заносятся онлайн через программу страховой компании и только потом из этой же программы печатается полис. А страховая компания в течение 5-20 минут уже передает всю необходимую информацию в единую базу.
Проверка полиса с помощью сервисов РСА:
1. Вариант проверки по номеру полиса
(видим статус полиса, сроки действия договора, название страховой компании) заходим на сайт РСА (http://autoins.ru) в разделе «ОСАГО» находите слева в меню пункт: «Сведения для страхователей и потерпевших» и переходим туда и выбираем: Сведения для страхователей о статусе бланков полисов ОСАГО и дате заключения договора.
Как только Вы перешли у Вас появляется вот такое окно:
Далее выбираете серию полиса и вбиваете его номер, если Вы сделали все верно (правильно вбили код безопасности и сервис работает в нормальном режиме), то возможны несколько статусов полиса:
- полис: находится у страховщика;
- полис: находится у страхователя;
- полис: утратил силу;
- полис: утерян;
- полис: испорчен.

А. Статус полиса — находится у страховщика (это означает, что полис может находится в страховой компании, также может выдан на руки агенту, брокеру. Или еще возможно такое: если Вам привезли напечатанный полис и при проверке, сервис РСА выдает статус — находится у страховщика, то это может означать, что страховая компания не передала данные в единую базу РСА (передача данных может занимать от 5 минут до целого дня, в разных компаниях это может быть по-разному). В таком случае самым правильным решением для проверки полиса будет звонок в страховую компанию или проверка онлайн на сайте страховой компании (если у них есть такая функция).
Б. Статус полиса — находится у страхователя (страхователь — это клиент, то есть проще говоря данный полис находится уже на руках у клиента, на самом деле это означает, что страховая компания по этому полису передала данные в единую базу РСА. При проверке полис не всегда бывает, что находится физически у страхователя на руках, т. к. клиент может заранее попросить серию/номер полиса (его скан/фото), а его доставка будет осуществлена позже. Обязательно внимательно проверяйте на соответствие даты договора и название страховой компании. Распространенная схема мошенничества — это поддельные полисы, у которые совпадают серия/номер, но на самом деле он выдан в других числах и числится за другим собственником и автомобилем.
к. клиент может заранее попросить серию/номер полиса (его скан/фото), а его доставка будет осуществлена позже. Обязательно внимательно проверяйте на соответствие даты договора и название страховой компании. Распространенная схема мошенничества — это поддельные полисы, у которые совпадают серия/номер, но на самом деле он выдан в других числах и числится за другим собственником и автомобилем.
В. Статус полиса — утратил силу (данный статус чаще всего присваивается полису, из-за каких либо изменений. Например клиент делал полис на полгода, потом продлили его на оставшиеся полгода, ему могли продлить как старом полисе, так и выдать новый бланк и забрать старый. Соответственно старый бланк прекращает свое действие, а новому присваивается статус — находится у страхователя. Это все случаи замены полиса на другой еще до окончания срока страхования, а также случаи прекращения договора страхования. Например, клиент продал свой автомобиль, обратился в страховую компанию за получением денежных средств за неиспользованный период страхования. Страховая компания компания расторгла договора и ему присвоили статус — утратил силу.
Страховая компания компания расторгла договора и ему присвоили статус — утратил силу.
Г. Статус полиса — утерян (данный статус присваивается полисам, о которых страховые компании сообщили в РСА как об утеренных (украденных).
Д. Статус полиса — испорчен (данный статус присваивается полисам, которые сдаются в страховую компанию как испорченные).
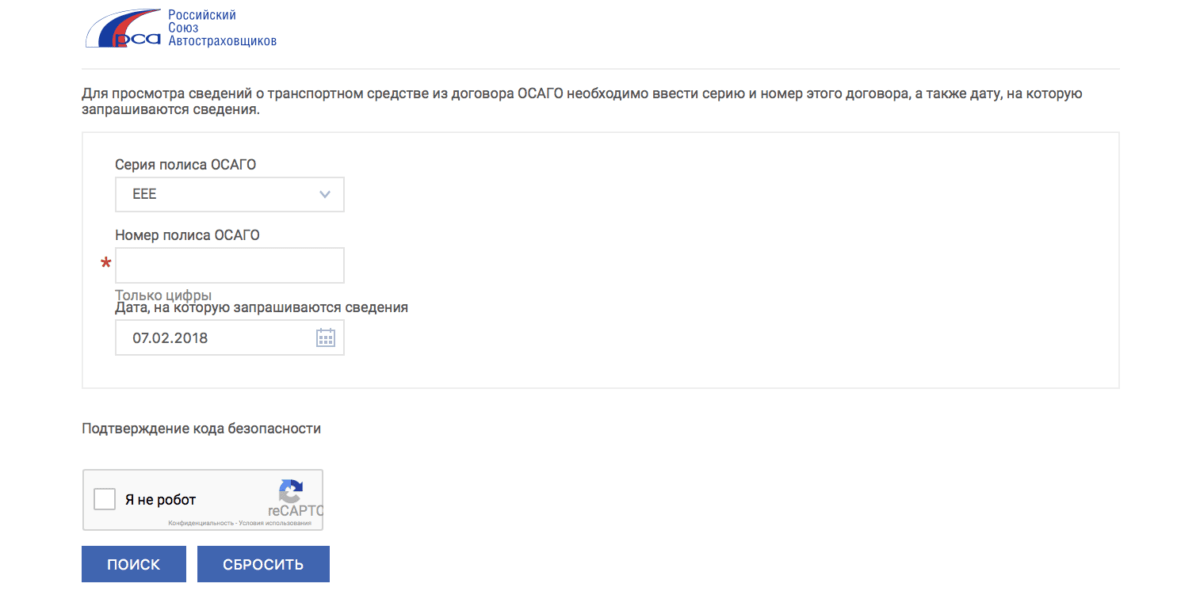
2. Еще один сервис проверки по номеру полиса
(мы видим данные по автомобилю (VIN-номер, госномер), название страховой компании, действует договор на указанную дату или нет), заходим на сайт РСА (http://autoins.ru) в разделе «ОСАГО» находите слева в меню пункт: «Сведения для страхователей и потерпевших» и переходим туда и выбираем: Сведения для страхователей о застрахованных транспортных средствах.
Далее выбираете серию полиса, вбиваете его номер, указываете дату, когда уже полис действует (можно и прошлую, и будущую дату), если Вы сделали все верно (правильно вбили код безопасности и сервис работает в нормальном режиме) и страховая компания передала данные по полису в единую базу РСА, то Вы увидите следующий результат:
Если данные по полису не переданы в РСА, то снизу появится надпись: Сведения о полисе ОСАГО с указанными серией и номером не найдены
Как приобрести электронный полис ОСАГО
С тем, что такое ОСАГО вообще, мы разобрались. Одно из главных новшеств последнего времени – возможность оформить полис ОСАГО через интернет, не выходя из дома. Как это сделать, чем будет отличаться электронный полис, и есть ли в этом какая-то выгода?
Одно из главных новшеств последнего времени – возможность оформить полис ОСАГО через интернет, не выходя из дома. Как это сделать, чем будет отличаться электронный полис, и есть ли в этом какая-то выгода?
1. Что нужно сделать?
Оформить электронный полис ОСАГО онлайн и получить возможность эксплуатировать автомобиль без риска получить штраф.
2. Как оформить электронный полис?
Процедура оформления электронного полиса ОСАГО проста. Вот алгоритм ваших действий:
- выбрать страховую компанию, предоставляющую услугу оформления электронного полиса ОСАГО – со списком таких СК можно ознакомиться здесь;
- зайти на официальный сайт выбранной страховой компании;
- пройти процедуру регистрации, указав свой адрес электронной почты и номер телефона или авторизовавшись через портал Госуслуг;
- заполнить предложенную форму заявления на оформление Е-ОСАГО, внеся данные о собственнике, страхователе, автомобиле и водителях, допущенных к управлению автомобилем, а также предоставив необходимые копии документов;
- получить расчет стоимости страхового полиса и оплатить его одним из предложенных способов;
- получить приобретенный полис ОСАГО на электронную почту и распечатать его для предъявления сотрудникам ГИБДД.

3. Какие особенности и нюансы существуют при оформлении электронного полиса ОСАГО?
Фактически никаких – вам нужно лишь максимально ответственно подойти к процессу оформления: ошибки при вводе данных могут осложнить жизнь, приведя к недействительности полиса. Стоит заранее подготовить документы, удостоверяющие личность собственника и страхователя, ПТС и свидетельство о регистрации автомобиля, а также водительские удостоверения лиц, которые будут допущены к управлению автомобилем. Разумеется, под рукой надо иметь телефон и компьютер с доступом в интернет. При регистрации на сайте страховой компании вам могут предложить зарегистрироваться с помощью вашей учетной записи на портале Госуслуг – это может быть удобно, но вопрос этой «интеграции» остается на ваш выбор. Кроме того, стоит помнить, что для оформления ОСАГО требуются действующая диагностическая карта и действующая регистрация автомобиля.
4. Как предъявлять электронный полис сотрудникам ГИБДД?
После окончания процедуры оформления вам на электронную почту придет полис ОСАГО. Для предъявления сотрудникам ГИБДД его надо просто распечатать и иметь при себе эту бумажную копию. На ней нет печати и рукописной подписи страховщика: он подписывает документ при помощи электронной подписи. Вам же для формальности стоит поставить подпись страхователя на распечатанной копии, хотя на актуальность полиса это никак не влияет.
Для предъявления сотрудникам ГИБДД его надо просто распечатать и иметь при себе эту бумажную копию. На ней нет печати и рукописной подписи страховщика: он подписывает документ при помощи электронной подписи. Вам же для формальности стоит поставить подпись страхователя на распечатанной копии, хотя на актуальность полиса это никак не влияет.
5. Как убедиться, что приобретенный мной полис ОСАГО действующий и не поддельный?
Для того, чтобы убедиться, что полис, присланный вам на почту, действителен, можно проверить его на сайте Российского Союза Автостраховщиков (РСА) – вот здесь. Для проверки потребуется лишь ввести номер полиса, после чего вам будет предоставлена информация о его статусе.
6. Каковы преимущества приобретения электронного полиса ОСАГО?
Преимущества оформления ОСАГО через интернет очевидны: это экономия времени, сил и денег, а зачастую и нервов. С временем и силами все ясно: вам не потребуется лично посещать офис страховой компании, сидеть в очередях и записываться на прием на следующий месяц (а ведь в некоторых регионах подобная практика до сих пор актуальна). Что же касается денег и нервов, то их можно будет «сэкономить» на отказе от навязанных дополнительных услуг: поскольку полис оформляете лично вы, то вы и решаете, какие услуги хотите приобрести. В обозримом прошлом на сайтах некоторых страховщиков были явно незаконные уловки вроде невозможности нажать кнопку «далее», не поставив галочку напротив строк вроде «да, я хочу приобрести дополнительную услугу страхования жизни, здоровья, квартиры, гаража и любимой собаки», но массовое внедрение электронного ОСАГО свело подобные трюки на нет. А значит, и спорить с сотрудником страховой компании, убеждающим вас, что без дополнительных услуг вы не сможете приобрести ОСАГО, больше не придется.
С временем и силами все ясно: вам не потребуется лично посещать офис страховой компании, сидеть в очередях и записываться на прием на следующий месяц (а ведь в некоторых регионах подобная практика до сих пор актуальна). Что же касается денег и нервов, то их можно будет «сэкономить» на отказе от навязанных дополнительных услуг: поскольку полис оформляете лично вы, то вы и решаете, какие услуги хотите приобрести. В обозримом прошлом на сайтах некоторых страховщиков были явно незаконные уловки вроде невозможности нажать кнопку «далее», не поставив галочку напротив строк вроде «да, я хочу приобрести дополнительную услугу страхования жизни, здоровья, квартиры, гаража и любимой собаки», но массовое внедрение электронного ОСАГО свело подобные трюки на нет. А значит, и спорить с сотрудником страховой компании, убеждающим вас, что без дополнительных услуг вы не сможете приобрести ОСАГО, больше не придется.
Проверить полис ОСАГО ВСК на подлинность через РСА
Чтобы проверить полис ОСАГО ВСК, понадобятся его реквизиты: серия и номер. Для этого подойдет как электронный полис ОСАГО, так и бумажный. В зависимости от типа выполняемой проверки можно получить данные о полисе, автомобиле, допущенных к управлению лицах.
Для этого подойдет как электронный полис ОСАГО, так и бумажный. В зависимости от типа выполняемой проверки можно получить данные о полисе, автомобиле, допущенных к управлению лицах.
Отсутствие данных в системе характерно для поддельных бланков, сведения о которых не вносятся в базу данных РСА. При появлении такой проблемы сначала следует обратиться в страховую компанию, выдавшую документ.
Проверка полиса ОСАГО ВСК по номеру бланка
Проверить онлайн полис ОСАГО ВСК на подлинность можно с помощью специального сервиса, предоставляемого Российским союзом автостраховщиков. Для этого нужно внести в форму реквизиты страховки: серию и номер бланка. Эти данные есть как в бумажном, так и электронном документе. Реквизиты расположены в верхней правой части бланка. Номер — это 10 цифр, серия — 3 заглавные латинские буквы (EEE, XXX, KKK и другие).
Необходимо учитывать, что при заполнении полей на сайте следует вводить только цифры, без дополнительных символов и знаков.
В случае отсутствия данных в системе либо при наличии ошибок в указанных реквизитах система выведет соответствующее уведомление. Если сведения введены правильно, но поиск не выдает результатов. Вероятно, проверяемый документ является поддельным — данные о нем не внесены в РСА.
Для уточнения информации нужно обратиться к своему страховщику. В редких случаях информация в единой базе РСА отсутствует по вине страховой компании — из-за возникших сбоев либо при ошибке сотрудников. При выявлении неточностей страховщик должен передать новую информацию.
Если проверка полиса ОСАГО ВСК по номеру и серии прошла, откроется новое окно со следующей информацией:
- дата выполняемой проверки;
- наименование страховой компании;
- дата заключения договора;
- дата начала действия договора и его окончания.
Важно помнить, что допускается небольшая задержка во времени между оформлением нового полиса и внесением его реквизитов в единую базу РСА.
 Однако отсутствие данных более недели — это повод для обращения в страховую компанию, оформлявшую страховку.
Однако отсутствие данных более недели — это повод для обращения в страховую компанию, оформлявшую страховку.Узнать реквизиты страховки по номеру автомобиля, или VIN
Зная VIN и государственный регистрационный номер автомобиля, можно проверить все когда-либо оформленные на него страховые полисы ОСАГО. Точные данные указаны в ПТС и свидетельстве о регистрации автомобиля.
Поскольку для проверки потребуются документы на ТС, сделать это может собственник либо потенциальный покупатель. Способ полезен при покупке авто на вторичном рынке для проверки честности продавца.
Для проверки также используется специальная форма на официальном сайте РСА. Необходимо указать VIN, государственный регистрационный знак, данные кузова или шасси, затем выбрать дату оформления запроса.
Если реквизиты указаны правильно, и на проверяемый автомобиль были оформлены страховки, данные о которых внесены в базу РСА, появится следующая информация:
- реквизиты страхового договора ОСАГО;
- наименование страховой компании;
- тип страховки — с ограничением или без.

Дополнительно можно посмотреть допущенных к управлению этим автомобилем водителей. Для этого понадобятся данные водительского удостоверения. Следует помнить, что отсутствие информации в системе не может стать основанием для отказа в предоставлении страховой выплаты.
Система выводит все страховки, которые были оформлены на проверяемый автомобиль, в момент отправки запроса. Допускается задержка в несколько дней при обновлении баз РСА.
Узнать сведения о застрахованном автомобиле по номеру полиса ВСК
Реквизиты бланка ОСАГО позволяют узнать государственный регистрационный номер и VIN застрахованного транспортного средства.
Чтобы получить эту информацию, необходимо воспользоваться специальной формой на официальном сайте РСА и внести в нее реквизиты ОСАГО — серию и номер.
Если данные внесены верно, и сведения имеются в единой базе РСА, система выведет сведения о застрахованном транспортном средстве: государственный регистрационный знак, VIN, наименование страховщика и текущий статус договора.
В РСА сведения о транспортном средстве поступают от страховой компании при оформлении страховки. Если проверяемый автомобиль новый, либо собственник не получал страховку официально, в базе не будет искомой информации.
Форма проверки вписанных водителей
С помощью информации о застрахованном транспортном средстве можно найти данные полиса ОСАГО ВСК, в том числе сведения о допущенных к управлению водителях. Для проведения проверки потребуются следующие данные: государственный регистрационный знак, VIN, номер кузова и шасси. После выбора точной даты проведения проверки откроется окно со всеми страховками, когда-либо оформленными на искомый автомобиль.
Далее необходимо указать серию и номер в/у проверяемого водителя. Если сведения найдены, система выведет результат. Информации не будет, если водитель вписан в страховку незаконно либо проверяемый полис является неограниченным.
Не во всех случаях получается провести проверку, и отсутствие информации не является фактом незаконного владения и не может служить основанием для отказа в предоставлении страховой выплаты.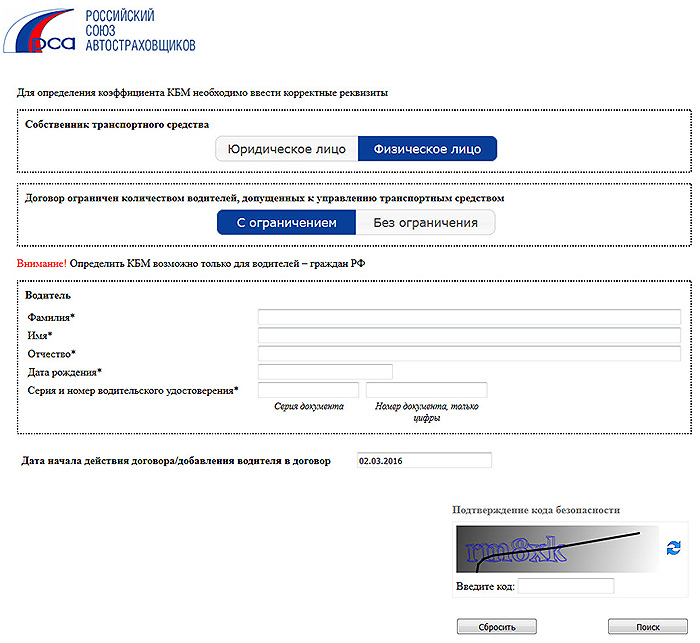 Ошибки происходят из-за задержек со стороны страховщика, а также в случае приобретения подложных бланков.
Ошибки происходят из-за задержек со стороны страховщика, а также в случае приобретения подложных бланков.
Поиск по официальным базам данных РСА может предоставить информацию о страховом полисе, допущенных к управлению водителях, государственном регистрационном знаке автомобиля и его VIN. В зависимости от типа проверки требуются те или иные реквизиты, но чаще всего это серия и номер страхового бланка. Посмотреть их можно на бумажном или электронном полисе. Отсутствие искомых данных в РСА является признаком поддельного бланка ОСАГО.
Вы можете поставить оценку компании ВСК
Информация страхователям
Приведение в порядок с помощью PCA: Введение в анализ основных компонентов | Автор: Сидней Фирмин.
Анализ главных компонентов (PCA) — это метод уменьшения размерности, который представляет собой процесс уменьшения количества переменных-предикторов в наборе данных.
В частности, PCA — это неконтролируемый тип извлечения признаков, при котором исходные переменные объединяются и сокращаются до их наиболее важных и описательных компонентов.
Цель PCA — выявить закономерности в наборе данных, а затем выделить переменные в их наиболее важные особенности, чтобы упростить данные без потери важных характеристик.PCA спрашивает, вызывают ли радость все измерения набора данных, а затем дает пользователю возможность удалить те, которые этого не делают.
PCA — очень популярный метод, но его часто не понимают люди, применяющие его. Моя цель в этом сообщении в блоге — дать общий обзор того, зачем использовать PCA, а также как это работает.
Проклятие размерности (Или, зачем беспокоиться о снижении размерности?)
Проклятие размерности — это совокупность явлений, которые утверждают, что по мере увеличения размерности, управляемость и эффективность данных имеют тенденцию к снижению .На высоком уровне проклятие размерности связано с тем фактом, что по мере добавления размеров (переменных / характеристик) к набору данных среднее и минимальное расстояние между точками (записями / наблюдениями) увеличивается.
Я считаю, что визуализация переменных как измерений и наблюдений как записей / точек помогает, когда я начинаю думать о таких темах, как кластеризация или PCA. Каждая переменная в наборе данных — это набор координат для построения наблюдения в проблемном пространстве.
Создание хороших прогнозов становится более трудным, поскольку расстояние между известными точками и неизвестными точками увеличивается.Кроме того, функции в вашем наборе данных могут не добавить большой ценности или предсказательной силы в контексте целевой (независимой) переменной. Эти функции не улучшают модель, скорее они увеличивают шум в наборе данных, а также общую вычислительную нагрузку модели.
Из-за проклятия размерности уменьшение размерности часто является критическим компонентом аналитических процессов. Особенно в приложениях, где данные имеют высокую размерность, например компьютерное зрение или обработка сигналов.
При сборе данных или применении набора данных не всегда очевидно или легко узнать, какие переменные важны. Нет даже гарантии, что переменные, которые вы выбрали или были предоставлены, являются переменными правильными . Кроме того, в эпоху больших данных огромное количество переменных в наборе данных может выйти из-под контроля и даже сбить с толку и ввести в заблуждение. Это может затруднить (или сделать невозможным) выбор значимых переменных вручную.
Нет даже гарантии, что переменные, которые вы выбрали или были предоставлены, являются переменными правильными . Кроме того, в эпоху больших данных огромное количество переменных в наборе данных может выйти из-под контроля и даже сбить с толку и ввести в заблуждение. Это может затруднить (или сделать невозможным) выбор значимых переменных вручную.
Не бойтесь, PCA смотрит на общую структуру непрерывных переменных в наборе данных, чтобы извлечь значимые сигналы из шума в наборе данных.Он направлен на устранение избыточности в переменных при сохранении важной информации.
PCA тоже любит беспорядок.
Как работает PCA
PCA изначально возникла из области линейной алгебры. Это метод преобразования, который создает (взвешенные линейные) комбинации исходных переменных в наборе данных с намерением, чтобы новые комбинации улавливали как можно большую дисперсию (т. Е. Разделение между точками) в наборе данных, устраняя при этом корреляции ( я.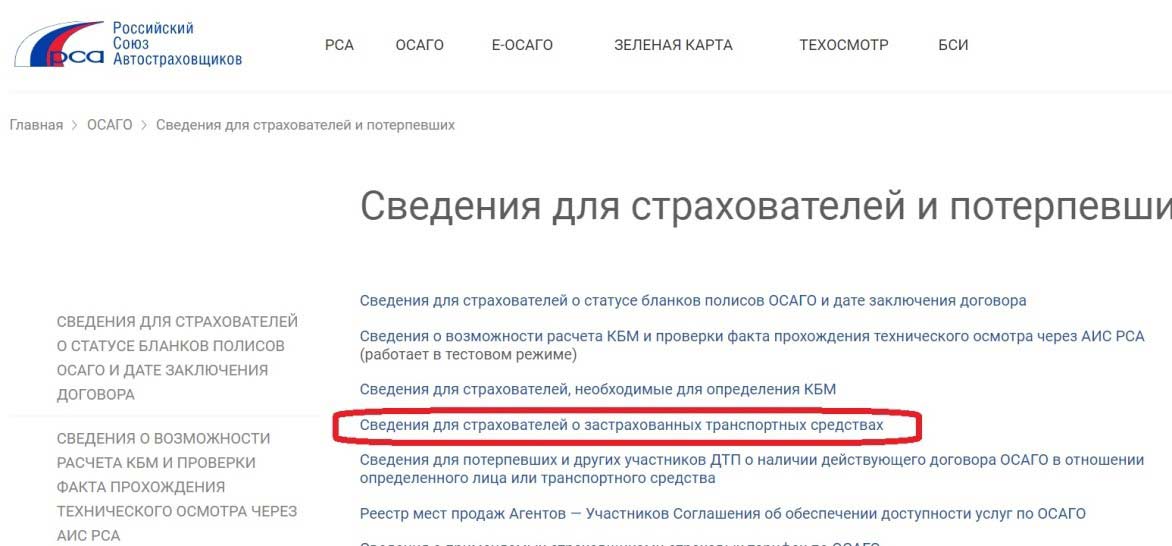 е., избыточность).
е., избыточность).
PCA создает новые переменные путем преобразования исходных (центрированных по среднему) наблюдений (записей) в наборе данных в новый набор переменных (измерений) с использованием собственных векторов и собственных значений, вычисленных на основе ковариационной матрицы исходных переменных.
Это полный рот. Давайте разберемся, начав со среднего значения исходных переменных.
Первым шагом PCA является центрирование значений всех входных переменных (например, вычитание среднего значения каждой переменной из значений), при котором среднее значение каждой переменной становится равным нулю.Центрирование является важным этапом предварительной обработки, поскольку оно гарантирует, что результирующие компоненты смотрят только на дисперсию в наборе данных, а не фиксируют общее среднее значение набора данных в качестве важной переменной (измерения). Без центрирования среднего первый главный компонент, найденный PCA, мог бы соответствовать среднему значению данных, а не направлению максимальной дисперсии.
После того, как данные центрированы (и, возможно, масштабированы, в зависимости от единиц переменных), необходимо вычислить ковариационную матрицу данных.
Ковариация измеряется между двумя переменными (измерениями) одновременно и описывает, как значения переменных связаны друг с другом: например, поскольку наблюдаемые значения увеличения переменной x одинаковы для переменной y? Большое значение ковариации (положительное или отрицательное) указывает на то, что переменные имеют сильную линейную связь друг с другом. Значения ковариации, близкие к 0, указывают на слабую или несуществующую линейную связь.
Эта визуализация из https: // stats.stackexchange.com/questions/18058/how-would-you-explain-covariance-to-someone-who-understands-only-the-mean очень полезен для понимания ковариации.
Ковариация всегда измеряется в двух измерениях. Если вы имеете дело с более чем двумя переменными, наиболее эффективный способ убедиться, что вы получили все возможные значения ковариации, — это поместить их в матрицу (следовательно, матрицу ковариации). В ковариационной матрице диагональ — это дисперсия для каждой переменной, а значения по диагонали являются зеркалом друг для друга, потому что каждая комбинация переменных включается в матрицу дважды.Это квадратная симметричная матрица.
В ковариационной матрице диагональ — это дисперсия для каждой переменной, а значения по диагонали являются зеркалом друг для друга, потому что каждая комбинация переменных включается в матрицу дважды.Это квадратная симметричная матрица.
В этом примере дисперсия переменной A составляет 0,67, а дисперсия второй переменной — 0,25. Ковариация между двумя переменными составляет 0,55, что отражается на главной диагонали матрицы.
Поскольку ковариационные матрицы являются квадратными и симметричными, их можно диагонализовать, что означает, что для матрицы можно вычислить собственное разложение. Здесь PCA находит собственные векторы и собственные значения для набора данных.
Собственный вектор линейного преобразования — это (ненулевой) вектор, который изменяется на скалярное кратное самому себе, когда к нему применяется соответствующее линейное преобразование.Собственное значение — это скаляр, связанный с собственным вектором. Самая полезная вещь, которую я нашел для понимания собственных векторов и значений, — это увидеть пример (если это не имеет смысла, попробуйте посмотреть этот урок умножения матриц от Khan Acadamy).
Мне сказали, что использование * для матричного умножения — это необычное явление, но я оставил его для ясности. Приношу свои извинения любому оскорбленному математику, читающему это.
В этом примере
— это собственный вектор, а 5 — собственное значение.
В контексте понимания PCA на высоком уровне, все, что вам на самом деле нужно знать о собственных векторах и собственных значениях, — это то, что собственные векторы ковариационной матрицы являются осями основных компонентов в наборе данных. Собственные векторы определяют направления главных компонентов, рассчитываемых PCA. Собственные значения, связанные с собственными векторами, описывают величину собственного вектора или насколько далеко друг от друга разнесены наблюдения (точки) вдоль новой оси.
Первый собственный вектор будет охватывать наибольшую дисперсию (разделение между точками), обнаруженную в наборе данных, а все последующие собственные векторы будут перпендикулярны (или, говоря математическим языком, ортогональны) к вычисленному перед ним. Вот как мы можем узнать, что каждый из основных компонентов не коррелирует друг с другом.
Вот как мы можем узнать, что каждый из основных компонентов не коррелирует друг с другом.
Если вы хотите узнать больше о собственных векторах и собственных значениях, в Интернете есть множество ресурсов, разбросанных именно с этой целью. Для краткости я буду избегать попыток преподавать линейную алгебру (плохо) в сообщениях в блоге.
Каждый собственный вектор, найденный PCA, выбирает комбинацию отклонений от исходных переменных в наборе данных.
На этом рисунке Главный компонент 1 учитывает отклонения от обеих переменных A и B.
Собственные значения важны, потому что они обеспечивают критерий ранжирования для вновь полученных переменных (осей). Основные компоненты (собственные векторы) сортируются по убыванию собственного значения. Главные компоненты с наивысшими собственными значениями «выбираются первыми» в качестве главных компонентов, поскольку они составляют наибольшую дисперсию данных.
Вы можете указать, что возвращает почти столько основных компонентов, сколько переменных в исходном наборе данных (обычно до n-1, где n — количество исходных входных переменных), но большая часть дисперсии будет учтена в главные основные компоненты. Чтобы узнать, сколько основных компонентов выбрать, ознакомьтесь с этим обсуждением переполнения стека. Или вы всегда можете просто спросить себя: «Я, сколько измерений вызовет радость?» (Это была шутка, вам, вероятно, следует использовать только график осыпи.)
Чтобы узнать, сколько основных компонентов выбрать, ознакомьтесь с этим обсуждением переполнения стека. Или вы всегда можете просто спросить себя: «Я, сколько измерений вызовет радость?» (Это была шутка, вам, вероятно, следует использовать только график осыпи.)
График осыпи показывает дисперсию, зафиксированную каждым главным компонентом. Этот график Scree был создан для вывода отчета инструмента «Основные компоненты» в Alteryx Designer.
После определения основных компонентов набора данных, наблюдения исходного набора данных необходимо преобразовать в выбранные основные компоненты.
Чтобы преобразовать наши исходные точки, мы создаем матрицу проекции. Эта матрица проекции — это просто выбранные собственные векторы, объединенные в матрицу. Затем мы можем умножить матрицу наших исходных наблюдений и переменных на нашу матрицу проекции. Результатом этого процесса является преобразованный набор данных, проецируемый в наше новое пространство данных, состоящий из наших основных компонентов!
Вот и все! Мы завершили СПС.
Допущения и ограничения
Перед применением PCA необходимо учесть несколько моментов.
Нормализация данных перед выполнением PCA может быть важной, особенно когда переменные имеют разные единицы или масштабы. Вы можете сделать это в инструменте «Дизайнер», выбрав опцию Масштабировать каждое поле, чтобы иметь единичную дисперсию.
PCA предполагает, что данные могут быть аппроксимированы линейной структурой и что данные могут быть описаны с меньшим количеством функций. Предполагается, что линейное преобразование может и будет захватывать наиболее важные аспекты данных. Также предполагается, что высокая дисперсия данных означает, что существует высокое отношение сигнал / шум.
Уменьшение размерности действительно приводит к потере некоторой информации. Если не сохранить все собственные векторы, некоторая информация будет потеряна. Однако, если собственные значения не включенных собственных векторов малы, вы не теряете слишком много информации.
Еще одно соображение, которое следует учитывать при использовании PCA, заключается в том, что переменные становятся менее интерпретируемыми после преобразования. Входная переменная может означать что-то конкретное, например «воздействие УФ-излучения», но переменные, созданные PCA, представляют собой беспорядочную смесь исходных данных и не могут быть интерпретированы однозначно, например, «увеличение воздействия УФ-излучения коррелирует с увеличением наличие рака кожи.«Менее интерпретируемый также означает менее объяснимый, когда вы представляете свои модели другим.
Сильные стороны
PCA популярен, потому что он может эффективно найти оптимальное представление набора данных с меньшим количеством измерений. Он эффективен для фильтрации шума и уменьшения избыточности. Если у вас есть набор данных с множеством непрерывных переменных, и вы не знаете, как выбрать важные функции для целевой переменной, PCA может идеально подойти для вашего приложения. Аналогичным образом, PCA также популярен для визуализации наборов данных с высокой размерностью (потому что нам, скудным людям, трудно мыслить более чем в трех измерениях).
Аналогичным образом, PCA также популярен для визуализации наборов данных с высокой размерностью (потому что нам, скудным людям, трудно мыслить более чем в трех измерениях).
Дополнительные ресурсы
Мой любимый учебник (который включает в себя обзор лежащих в основе математики) принадлежит Линдси И. Смит из Университета Отаго. Учебное пособие по анализу основных компонентов.
Вот еще один отличный учебник по анализу основных компонентов от Джона Шленса из UCSD
Все, что вы знали и не знали о PCA, из блога Its Neuronal посвящено математике и вычислениям в нейробиологии.
«Анализ главных компонентов за 3 простых шага» имеет несколько красивых иллюстраций и разбит на отдельные шаги.
«Анализ основных компонентов» из блога Джереми Куна — это приятная краткая статья, в которой есть ссылка на собственные лица.
Универсальный центр анализа основных компонентов от Мэтта Бремса.
Оригинал. Размещено с разрешения.
scikit learn — Анализ главных компонентов (PCA) в Python
Я сделал небольшой скрипт для сравнения различных PCA, который появился в качестве ответа здесь:
импортировать numpy как np
от scipy. linalg import svd
shape = (26424, 144)
повторить = 20
pca_components = 2
данные = np.array (np.random.randint (255, размер = форма)). astype ('float64')
# нормализация данных
# data.dot (data.T)
# (U, s, Va) = svd (data, full_matrices = False)
# data = data / s [0]
из fbpca import diffsnorm
from timeit импортировать default_timer как таймер
из scipy.linalg import svd
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = svd (data, full_matrices = False)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va)
print ('svd time:%.3fms, ошибка:% E '% (время * 1000 / повтор, ошибка))
из matplotlib.mlab импортировать PCA
start = timer ()
_pca = PCA (данные)
для я в диапазоне (повторить):
U = _pca.project (данные)
time = timer () - запуск
err = diffsnorm (данные, U, _pca.fracs, _pca.Wt)
print ('matplotlib PCA time:% .3fms, error:% E'% (time * 1000 / repeat, err))
из fbpca import pca
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca (данные, pca_components, True)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va)
print ('facebook pca time:% . 3fms, error:% E'% (time * 1000 / repeat, err))
из склеарна.декомпозиция импорта PCA
start = timer ()
_pca = PCA (n_components = pca_components)
_pca.fit (данные)
для я в диапазоне (повторить):
U = _pca.transform (данные)
time = timer () - запуск
err = diffsnorm (данные, U, _pca.explained_variance_, _pca.components_)
print ('sklearn PCA time:% .3fms, error:% E'% (time * 1000 / repeat, err))
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca_mark (данные, pca_components)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va.T)
print ('pca by Mark time:% .3fms, error:% E'% (time * 1000 / repeat, err))
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca_doug (данные, pca_components)
time = timer () - запуск
err = diffsnorm (данные, U, s [: pca_components], Va.Т)
print ('pca по времени обработки:% .3fms, ошибка:% E'% (время * 1000 / повтор, ошибка))
 linalg import svd
shape = (26424, 144)
повторить = 20
pca_components = 2
данные = np.array (np.random.randint (255, размер = форма)). astype ('float64')
# нормализация данных
# data.dot (data.T)
# (U, s, Va) = svd (data, full_matrices = False)
# data = data / s [0]
из fbpca import diffsnorm
from timeit импортировать default_timer как таймер
из scipy.linalg import svd
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = svd (data, full_matrices = False)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va)
print ('svd time:%.3fms, ошибка:% E '% (время * 1000 / повтор, ошибка))
из matplotlib.mlab импортировать PCA
start = timer ()
_pca = PCA (данные)
для я в диапазоне (повторить):
U = _pca.project (данные)
time = timer () - запуск
err = diffsnorm (данные, U, _pca.fracs, _pca.Wt)
print ('matplotlib PCA time:% .3fms, error:% E'% (time * 1000 / repeat, err))
из fbpca import pca
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca (данные, pca_components, True)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va)
print ('facebook pca time:% .
linalg import svd
shape = (26424, 144)
повторить = 20
pca_components = 2
данные = np.array (np.random.randint (255, размер = форма)). astype ('float64')
# нормализация данных
# data.dot (data.T)
# (U, s, Va) = svd (data, full_matrices = False)
# data = data / s [0]
из fbpca import diffsnorm
from timeit импортировать default_timer как таймер
из scipy.linalg import svd
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = svd (data, full_matrices = False)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va)
print ('svd time:%.3fms, ошибка:% E '% (время * 1000 / повтор, ошибка))
из matplotlib.mlab импортировать PCA
start = timer ()
_pca = PCA (данные)
для я в диапазоне (повторить):
U = _pca.project (данные)
time = timer () - запуск
err = diffsnorm (данные, U, _pca.fracs, _pca.Wt)
print ('matplotlib PCA time:% .3fms, error:% E'% (time * 1000 / repeat, err))
из fbpca import pca
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca (данные, pca_components, True)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va)
print ('facebook pca time:% . 3fms, error:% E'% (time * 1000 / repeat, err))
из склеарна.декомпозиция импорта PCA
start = timer ()
_pca = PCA (n_components = pca_components)
_pca.fit (данные)
для я в диапазоне (повторить):
U = _pca.transform (данные)
time = timer () - запуск
err = diffsnorm (данные, U, _pca.explained_variance_, _pca.components_)
print ('sklearn PCA time:% .3fms, error:% E'% (time * 1000 / repeat, err))
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca_mark (данные, pca_components)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va.T)
print ('pca by Mark time:% .3fms, error:% E'% (time * 1000 / repeat, err))
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca_doug (данные, pca_components)
time = timer () - запуск
err = diffsnorm (данные, U, s [: pca_components], Va.Т)
print ('pca по времени обработки:% .3fms, ошибка:% E'% (время * 1000 / повтор, ошибка))
3fms, error:% E'% (time * 1000 / repeat, err))
из склеарна.декомпозиция импорта PCA
start = timer ()
_pca = PCA (n_components = pca_components)
_pca.fit (данные)
для я в диапазоне (повторить):
U = _pca.transform (данные)
time = timer () - запуск
err = diffsnorm (данные, U, _pca.explained_variance_, _pca.components_)
print ('sklearn PCA time:% .3fms, error:% E'% (time * 1000 / repeat, err))
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca_mark (данные, pca_components)
time = timer () - запуск
err = diffsnorm (данные, U, s, Va.T)
print ('pca by Mark time:% .3fms, error:% E'% (time * 1000 / repeat, err))
start = timer ()
для я в диапазоне (повторить):
(U, s, Va) = pca_doug (данные, pca_components)
time = timer () - запуск
err = diffsnorm (данные, U, s [: pca_components], Va.Т)
print ('pca по времени обработки:% .3fms, ошибка:% E'% (время * 1000 / повтор, ошибка))
pca_mark — это pca в ответе Марка.
pca_doug — это pca в ответе Дуга.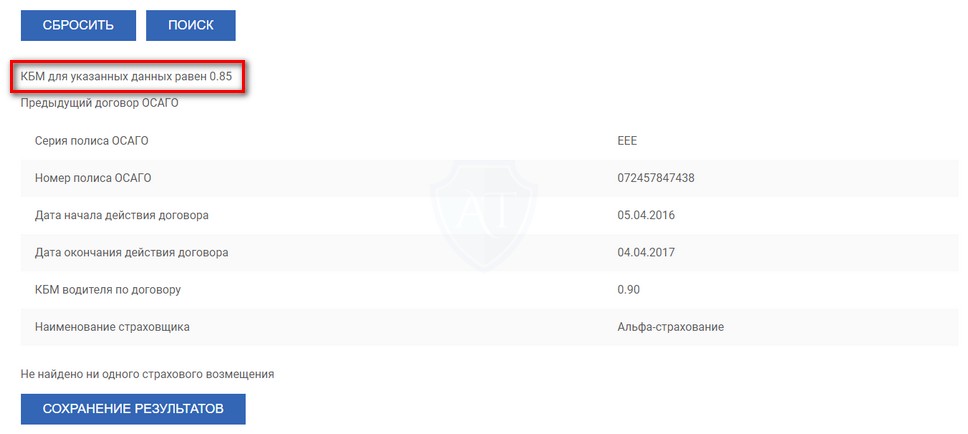
Вот пример вывода (но результат очень сильно зависит от размера данных и pca_components, поэтому я бы рекомендовал запустить собственный тест с вашими собственными данными. Кроме того, pca facebook оптимизирован для нормализованных данных, поэтому он будет быстрее и точнее в этом случае):
время свд: 3212.228 мс, ошибка: 1.0E-10
matplotlib Время PCA: 879,210 мс, ошибка: 2.478853E + 05
facebook pca time: 485.483ms, ошибка: 1.260335E + 04
sklearn Время PCA: 169,832 мс, ошибка: 7,469847E + 07
pca по времени Марка: 293,758 мс, ошибка: 1,713129E + 02
pca, время Дуга: 300,326 мс, ошибка: 1.707492E + 02
РЕДАКТИРОВАТЬ:
Функция diffsnorm из fbpca вычисляет ошибку спектральной нормы разложения Шура.
Пошаговое объяснение анализа основных компонентов
Цель этого поста — предоставить полное и упрощенное объяснение анализа основных компонентов и, особенно, пошагово ответить, как он работает, чтобы каждый мог его понять и использовать его, не обязательно имея сильную математическую подготовку.
PCA на самом деле широко освещенный в сети метод, и о нем есть несколько отличных статей, но лишь немногие из них переходят прямо к сути и объясняют, как он работает, не слишком углубляясь в технические детали и «почему». вещи. По этой причине я решил сделать свой пост, чтобы представить его в упрощенном виде.
Прежде чем перейти к объяснению, этот пост предоставляет логические объяснения того, что PCA делает на каждом шаге, и упрощает лежащие в его основе математические концепции, такие как стандартизация, ковариация, собственные векторы и собственные значения, не уделяя внимания тому, как их вычислять.
Что такое анализ главных компонентов?
Анализ главных компонентов, или PCA, представляет собой метод уменьшения размерности, который часто используется для уменьшения размерности больших наборов данных путем преобразования большого набора переменных в меньший, который по-прежнему содержит большую часть информации в большом наборе. .
Уменьшение количества переменных в наборе данных, естественно, происходит за счет точности, но хитрость в уменьшении размерности состоит в том, чтобы торговать небольшой точностью ради простоты. Потому что меньшие наборы данных легче исследовать и визуализировать, а анализ данных становится намного проще и быстрее для алгоритмов машинного обучения без обработки посторонних переменных.
Потому что меньшие наборы данных легче исследовать и визуализировать, а анализ данных становится намного проще и быстрее для алгоритмов машинного обучения без обработки посторонних переменных.
Итак, идея PCA проста — уменьшить количество переменных в наборе данных, сохраняя при этом как можно больше информации.
Пошаговое объяснение PCA
Шаг 1: Стандартизация
Цель этого шага — стандартизировать диапазон непрерывных исходных переменных, чтобы каждая из них в равной степени участвовала в анализе.
Более конкретно, причина того, почему так важно выполнить стандартизацию до PCA, заключается в том, что последний весьма чувствителен к дисперсиям исходных переменных. То есть, если есть большие различия между диапазонами исходных переменных, те переменные с большими диапазонами будут преобладать над переменными с небольшими диапазонами (например, переменная, которая находится в диапазоне от 0 до 100, будет преобладать над переменной, которая находится в диапазоне от 0 до 1. ), что приведет к необъективным результатам. Таким образом, преобразование данных в сопоставимые масштабы может предотвратить эту проблему.
Математически это можно сделать путем вычитания среднего и деления на стандартное отклонение для каждого значения каждой переменной.
После завершения стандартизации все переменные будут преобразованы в один и тот же масштаб.
Шаг 2: Расчет ковариационной матрицы
Цель этого шага — понять, как переменные входного набора данных отличаются от среднего по отношению друг к другу, или, другими словами, чтобы увидеть, есть ли какие-либо отношения между ними.Потому что иногда переменные сильно коррелированы, поэтому содержат избыточную информацию. Итак, чтобы идентифицировать эти корреляции, мы вычисляем ковариационную матрицу.
Ковариационная матрица — это симметричная матрица p × p (где p — количество измерений), в которой в качестве элементов есть ковариации, связанные со всеми возможными парами исходных переменных. Например, для 3-мерного набора данных с 3 переменными x , y и z ковариационная матрица представляет собой матрицу 3×3 из:
Например, для 3-мерного набора данных с 3 переменными x , y и z ковариационная матрица представляет собой матрицу 3×3 из:
Поскольку ковариация переменной с самой собой — это ее дисперсия (Cov (a, a) = Var (a)), по главной диагонали (сверху слева направо снизу) у нас фактически есть дисперсии каждой исходной переменной.А поскольку ковариация коммутативна (Cov (a, b) = Cov (b, a)), элементы ковариационной матрицы симметричны относительно главной диагонали, что означает, что верхняя и нижняя треугольные части равны.
Что ковариации, которые мы имеем в качестве элементов матрицы, говорят нам о корреляциях между переменными?
На самом деле имеет значение знак ковариации:
- , если положительный, то: две переменные увеличиваются или уменьшаются вместе (коррелировано)
- , если отрицательно, то: одна увеличивается, когда другая уменьшается (обратно коррелирована)
Сейчас , что мы знаем, что ковариационная матрица — это не более чем таблица, которая суммирует корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
Шаг 3: Вычислить собственные векторы и собственные значения ковариационной матрицы для определения главных компонентов
Собственные векторы и собственные значения — это концепции линейной алгебры, которые нам нужно вычислить из ковариационной матрицы, чтобы определить основные компоненты данных. Прежде чем перейти к объяснению этих концепций, давайте сначала поймем, что мы подразумеваем под основными компонентами.
Основные компоненты — это новые переменные, которые построены как линейные комбинации или смеси исходных переменных.Эти комбинации выполняются таким образом, что новые переменные (то есть главные компоненты) не коррелированы, и большая часть информации в исходных переменных сжимается или сжимается в первые компоненты. Итак, идея состоит в том, что 10-мерные данные дают вам 10 основных компонентов, но PCA пытается поместить максимум возможной информации в первый компонент, затем максимум оставшейся информации во второй и так далее, пока не будет что-то вроде того, что показано на графике осыпи ниже.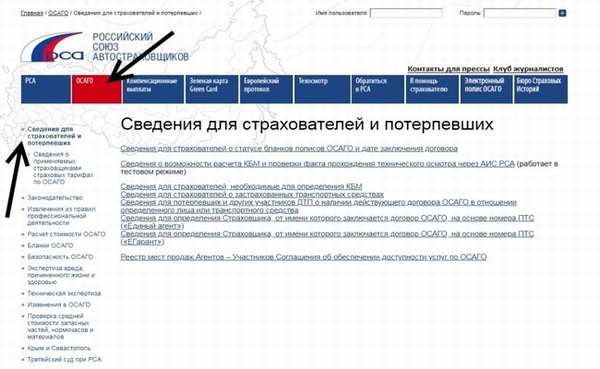
Такая организация информации по основным компонентам позволит вам уменьшить размерность без потери большого количества информации, и это за счет отбрасывания компонентов с низкой информацией и рассмотрения оставшихся компонентов как ваших новых переменных.
Здесь важно понимать, что главные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
Говоря геометрически, главные компоненты представляют направления данных, которые объясняют максимальное количество отклонений , то есть линии, которые захватывают большую часть информации данных. Связь между дисперсией и информацией здесь заключается в том, что чем больше дисперсия, переносимая линией, тем больше дисперсия точек данных вдоль нее, и чем больше дисперсия вдоль линии, тем больше информации она имеет.Проще говоря, просто думайте о главных компонентах как о новых осях, которые обеспечивают лучший угол для просмотра и оценки данных, чтобы различия между наблюдениями были лучше видны.
Будьте в курсе последних технических тенденций
Зарегистрируйтесь бесплатно, чтобы получать больше подобных историй о науке о данных.
Как PCA конструирует основные компонентыПоскольку количество основных компонентов равно количеству переменных в данных, главные компоненты строятся таким образом, что первый главный компонент составляет наибольшую возможную дисперсию в наборе данных.Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так, как показано ниже. Можем ли мы угадать первый главный компонент? Да, это примерно линия, которая соответствует фиолетовым отметкам, потому что она проходит через начало координат, и это линия, в которой проекция точек (красные точки) является наиболее разбросанной. Или, говоря математически, это линия, которая максимизирует дисперсию (среднее квадратов расстояний от проецируемых точек (красные точки) до начала координат).
Второй главный компонент рассчитывается таким же образом, при условии, что он не коррелирует с (т. е., перпендикулярно первому главному компоненту, и что он составляет следующую по величине дисперсию.
е., перпендикулярно первому главному компоненту, и что он составляет следующую по величине дисперсию.
Это продолжается до тех пор, пока не будет вычислено общее количество p главных компонентов, равное исходному количеству переменных.
Теперь, когда мы поняли, что мы подразумеваем под главными компонентами, давайте вернемся к собственным векторам и собственным значениям. В первую очередь вам нужно знать о них, что они всегда входят парами, так что каждый собственный вектор имеет собственное значение. И их количество равно количеству измерений данных.Например, для 3-мерного набора данных есть 3 переменных, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
Без лишних слов, за всей магией, описанной выше, стоят собственные векторы и собственные значения, потому что собственные векторы матрицы ковариации на самом деле являются , , , , , , направлениями осей, где наблюдается наибольшая дисперсия. информация), которую мы называем основными компонентами. А собственные значения — это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину отклонения , содержащуюся в каждом основном компоненте .
информация), которую мы называем основными компонентами. А собственные значения — это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину отклонения , содержащуюся в каждом основном компоненте .
Ранжируя собственные векторы в порядке их собственных значений, от наибольшего к наименьшему, вы получаете главные компоненты в порядке значимости.
Пример:
предположим, что наш набор данных является 2-мерным с 2 переменными x, y и что собственные векторы и собственные значения ковариационной матрицы следующие:
Если мы ранжируем собственные значения в В порядке убывания мы получаем λ1> λ2, что означает, что собственный вектор, соответствующий первой главной компоненте (PC1), равен v1, , а тот, который соответствует второму компоненту (PC2), равен v2.
После определения главных компонентов для вычисления процента дисперсии (информации), приходящейся на каждый компонент, мы делим собственное значение каждого компонента на сумму собственных значений. Если мы применим это к приведенному выше примеру, мы обнаружим, что ПК1 и ПК2 несут соответственно 96% и 4% дисперсии данных.
Если мы применим это к приведенному выше примеру, мы обнаружим, что ПК1 и ПК2 несут соответственно 96% и 4% дисперсии данных.
Шаг 4: Вектор признаков
Как мы видели на предыдущем шаге, вычисление собственных векторов и их упорядочение по их собственным значениям в порядке убывания позволяет нам найти главные компоненты в порядке значимости.На этом этапе мы выбираем, оставить ли все эти компоненты или отбросить те, которые имеют меньшее значение (с низкими собственными значениями), и сформировать с оставшимися матрицу векторов, которую мы называем Вектор признаков .
Итак, вектор признаков — это просто матрица, в столбцах которой есть собственные векторы компонентов, которые мы решили оставить. Это делает его первым шагом к уменьшению размерности, потому что, если мы решим оставить только собственные векторы (компоненты) p из n , окончательный набор данных будет иметь только размеры p .
Пример :
Продолжая пример из предыдущего шага, мы можем либо сформировать вектор признаков с обоими собственными векторами v 1 и v 2:
, либо отбросить собственный вектор v 2, который имеет меньшее значение и формирует вектор признаков только с v 1:
Отказ от собственного вектора v2 уменьшит размерность на 1 и, следовательно, вызовет потерю информации в окончательном наборе данных.Но учитывая, что v 2 несут только 4% информации, потеря, следовательно, не будет важной, и у нас все еще будет 96% информации, которая переносится v 1.
Итак, как мы видели в этом примере вам решать, сохранить ли все компоненты или отбросить менее важные, в зависимости от того, что вы ищете. Потому что, если вы просто хотите описать свои данные в терминах новых переменных (главных компонентов), которые не коррелированы, не стремясь уменьшить размерность, не нужно исключать менее значимые компоненты.
Последний шаг: повторное преобразование данных по осям основных компонентов
На предыдущих шагах, кроме стандартизации, вы не вносили никаких изменений в данные, вы просто выбираете основные компоненты и формируете вектор признаков, но набор входных данных всегда остается в терминах исходных осей (т. е. в терминах исходных переменных).
На этом этапе, который является последним, цель состоит в том, чтобы использовать вектор признаков, сформированный с использованием собственных векторов ковариационной матрицы, для переориентации данных с исходных осей на оси, представленные главными компонентами (отсюда и название Основные компоненты). Анализ компонентов).Это можно сделать, умножив транспонирование исходного набора данных на транспонирование вектора признаков.
* * *
Закария Джаади — специалист по анализу данных и инженер по машинному обучению. Ознакомьтесь с другими его материалами по темам Data Science на Medium.
Ссылки :
- [Стивен М. Холланд, Univ. of Georgia]: анализ главных компонентов
- [skymind.ai]: собственные векторы, собственные значения, PCA, ковариация и энтропия
- [Lindsay I.Smith]: Учебное пособие по анализу главных компонентов
 Холланд, Univ. of Georgia]: анализ главных компонентов
Холланд, Univ. of Georgia]: анализ главных компонентовСвязанныеПодробнее о Data Science
Анализ главных компонентов в R
[Эта статья была впервые опубликована на сайте poissonisfish и любезно предоставлена R-блогерам]. (Вы можете сообщить о проблеме с содержанием на этой странице здесь)Хотите поделиться своим контентом на R-bloggers? щелкните здесь, если у вас есть блог, или здесь, если нет.
Анализ главных компонентов (PCA) обычно используется для решения широкого круга задач.От обнаружения выбросов до прогнозного моделирования, PCA имеет возможность проецировать наблюдения, описанные
переменными, на несколько ортогональных компонентов, определенных в местах, где данные «растягиваются» больше всего, обеспечивая упрощенный обзор. PCA особенно эффективен при работе с мультиколлинеарностью и переменными, количество которых превышает количество выборок ().
Это неконтролируемый метод, что означает, что он всегда будет искать самые большие источники вариаций, независимо от структуры данных.Его аналог, метод частичных наименьших квадратов (PLS), является контролируемым методом и будет выполнять такую же ковариационную декомпозицию, хотя и выстраивает определяемое пользователем количество компонентов (часто обозначаемых как скрытые переменные), которые минимизируют SSE от прогнозирования указанного результата. с помощью обычного метода наименьших квадратов (МНК). PLS стоит целого поста, поэтому я воздержусь от второго внимания.
Если PCA для вас совсем новичок, я настоятельно рекомендую отличный Primer от Nature Biotechnology.Несмотря на то, что в центре внимания находятся науки о жизни, это должно быть ясно не биологам.
Математические основы В литературе существует множество формулировок PCA, датируемых веком, но в целом PCA — это чистая линейная алгебра. Один из самых популярных методов — разложение по сингулярным числам (SVD). Алгоритм SVD разбивает матрицу размером
Алгоритм SVD разбивает матрицу размером
, где
— матрица с собственными векторами, — диагональная матрица с сингулярными значениями и — матрица с собственными векторами.Эти матрицы имеют размер и, соответственно. Ключевое отличие SVD от диагонализации матрицы () состоит в том, что и представляют собой различные ортонормированные (ортогональные и единичные векторные) матрицы.PCA сокращает размер набора данных
до основных компонентов (ПК). Очки с первых компьютеров являются результатом умножения первых столбцов на верхнюю левую подматрицу. Коэффициенты загрузки ПК указаны непосредственно в строке в. Следовательно, умножение всех оценок и нагрузок восстанавливает.Вы также можете иметь в виду:- ПК упорядочены по убывающей разнице объясненной
- ПК ортогональны т.е. не коррелированы друг с другом
- Столбцы должны быть центрированы по среднему так, чтобы ковариационная матрица
- PCA на основе SVD не допускает пропущенных значений (но есть решения, которые мы вскоре рассмотрим)
Для более подробного объяснения вводной линейной алгебры, вот отличный бесплатный учебник по SVD, который я нашел в Интернете. В любом случае, я гарантирую, что вы сможете освоить PCA без полного понимания процесса.
В любом случае, я гарантирую, что вы сможете освоить PCA без полного понимания процесса.
Несмотря на то, что для R доступно множество методов PCA, я представлю только два,
- prcomp , функция по умолчанию из базового пакета R
- pcaMethods , пакет Bioconductor, который я часто использую для своих собственных PCA
Я начну с демонстрации того, что prcomp основан на алгоритме SVD с использованием функции base svd .
# Генерация масштабированной матрицы 4 * 5 со случайными стандартными выборками набор. семян (101) матПо умолчанию prcomp получит
ПК. Таким образом, в наших настройках мы ожидаем, что у нас будет четыре ПК. Функция svd будет вести себя так же:# Выполнить СВД mySVDТеперь, когда у нас есть объекты PCA и SVD, давайте сравним соответствующие оценки и нагрузки.
и SVD. В R умножение матриц возможно с помощью оператора % *% .Затем мы напрямую сравним нагрузки от PCA и SVD и, наконец, покажем, что умножение оценок и нагрузок восстанавливается. Я округлил результаты до пяти десятичных знаков, так как результаты не совсем совпадают! Функция t извлекает транспонированную матрицу.# Сравните результаты PCA с U * Sigma SVD теоретическиеPCA набора данных вина
Теперь, когда мы установили связь между SVD и PCA, мы выполним PCA для реальных данных.Я нашел набор данных Wine в репозитории машинного обучения UCI, который может служить хорошим стартовым примером.
виноСогласно документации, эти данные состоят из 13 физико-химических параметров, измеренных в 178 образцах вин трех различных сортов, выращенных в Италии. Давайте проверим паттерны в парах переменных, а затем посмотрим, что PCA сделает с этим, построив график PC1 против PC2.
# Назовите переменные colnames (вино)
Среди прочего, мы наблюдаем корреляции между переменными ( e.грамм. общее количество фенолов и флавоноидов), а иногда и двухмерное разделение трех сортов (, например, с использованием процентного содержания спирта и отношения OD).
Если достаточно сложно рассмотреть все попарные взаимодействия в наборе из 13 переменных, не говоря уже о наборах из сотен или тысяч переменных. В этих случаях очень помогает PCA. Давайте попробуем в этом наборе данных:
dev.off () # очищаем формат от предыдущего графика виноPCA
Три строчки кода, и мы видим четкое разделение между сортами винограда.Кроме того, точки данных равномерно разбросаны в относительно узких диапазонах на обоих ПК. Затем мы могли бы исследовать, какие параметры больше всего способствуют этому разделению и какая вариация объясняется каждым компьютером, но я оставлю это для pcaMethods . Теперь мы повторим процедуру после введения выброса вместо 10-го наблюдения.
WineOutlier
Как и ожидалось, огромная дисперсия, связанная с отделением 10-го наблюдения от ядра всех других образцов, полностью поглощается первым ПК.Внешний образец становится очевидным.
PCA набора данных вина с pcaMethods
Теперь перейдем к pcaMethods , компактному набору инструментов PCA. Сначала вам нужно будет установить его из Bioconductor:
Источник("https://bioconductor.org/biocLite.R") biocLite ("pcaMethods") библиотека (pcaMethods)Я так широко использую pcaMethods по трем основным причинам:
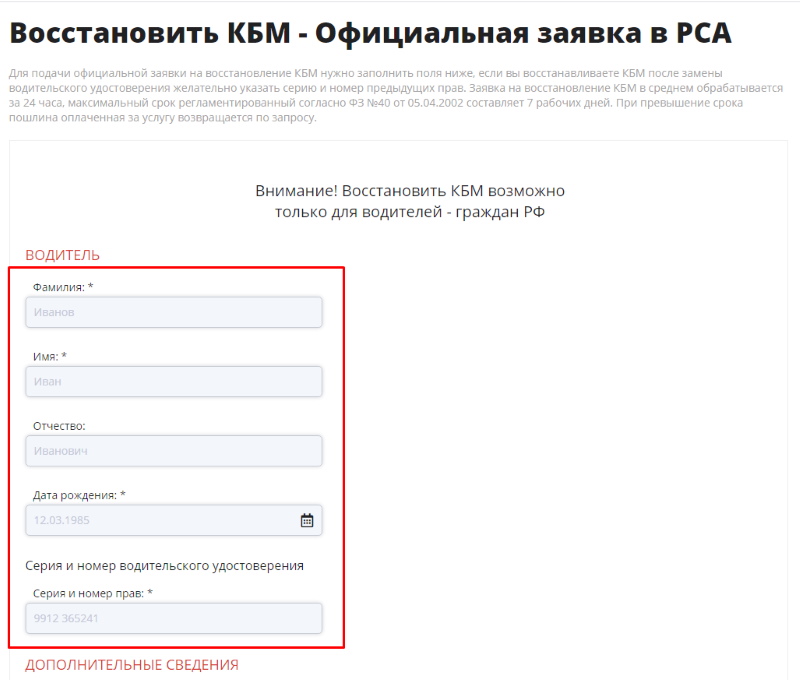
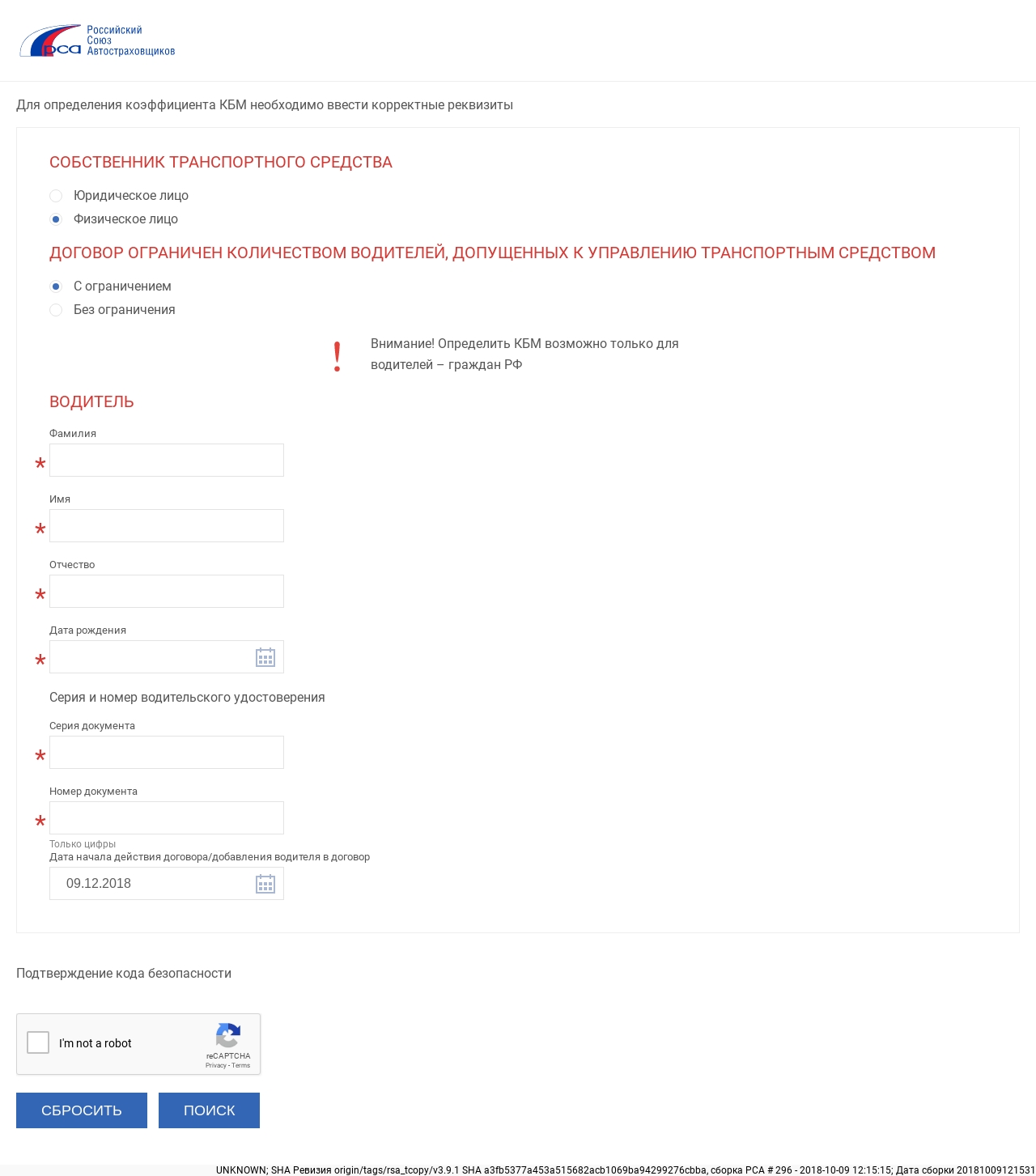
- Помимо SVD, он предоставляет несколько различных методов (байесовский PCA, вероятностный PCA, надежный PCA и многие другие)
- Некоторые из этих алгоритмов допускают и вменяют пропущенные значения
- Структура объекта и возможности построения графиков удобны для пользователя
Всю доступную информацию о пакете можно найти здесь. Сейчас я просто покажу совместные графики оценок и нагрузок, но все же рекомендую вам изучить их дальше.
Сейчас я просто покажу совместные графики оценок и нагрузок, но все же рекомендую вам изучить их дальше.
Я выберу метод SVD по умолчанию, чтобы воспроизвести наш предыдущий результат PCA, с той же стратегией масштабирования, что и раньше (UV или единичная дисперсия, как выполняется с помощью шкалы ). Аргумент scoresLoadings дает вам контроль над печатью оценок, загрузок или того и другого вместе, как показано ниже. Стандартные графические параметры (, например, cex , pch , col ), которым предшествуют буквы s или l , управляют эстетикой на графиках оценок или нагрузок соответственно.
winePCAmethods
Итак, во-первых, у нас есть точное воспроизведение предыдущего графика PCA. Тогда, имея панель нагрузок с правой стороны, мы можем утверждать, что
- Вино из Cv2 (красное) имеет более светлую интенсивность цвета, более низкий процент алкоголя, большую OD и больший оттенок по сравнению с вином из Cv1 и Cv3.
- Вино из Cv3 (зеленое) имеет более высокое содержание яблочной кислоты и нефлаваноидных фенолов, а также более высокую щелочность золы по сравнению с вином из Cv1 (черное)

Наконец, хотя разница, совместно объясняемая первыми двумя ПК, печатается по умолчанию (55.41%), было бы более информативно проконсультироваться с расхождениями, объясненными на отдельных ПК. Мы можем вызвать структуру winePCAmethods , проверить слоты и распечатать те, которые представляют интерес, так как там содержится много информации. Разница, объясненная для каждого компонента, сохраняется в слоте с именем R2 .
str (winePCAmethods) # слоты помечены @ [электронная почта защищена]
По-видимому, PC1 и PC2 объясняют 36,2% и 19,2% дисперсии в наборе данных по вину, соответственно.PCA данных, демонстрирующих сильные эффекты (таких как пример с выбросом, приведенный выше), вероятно, приведет к тому, что последовательность PC покажет резкое падение объясненной дисперсии.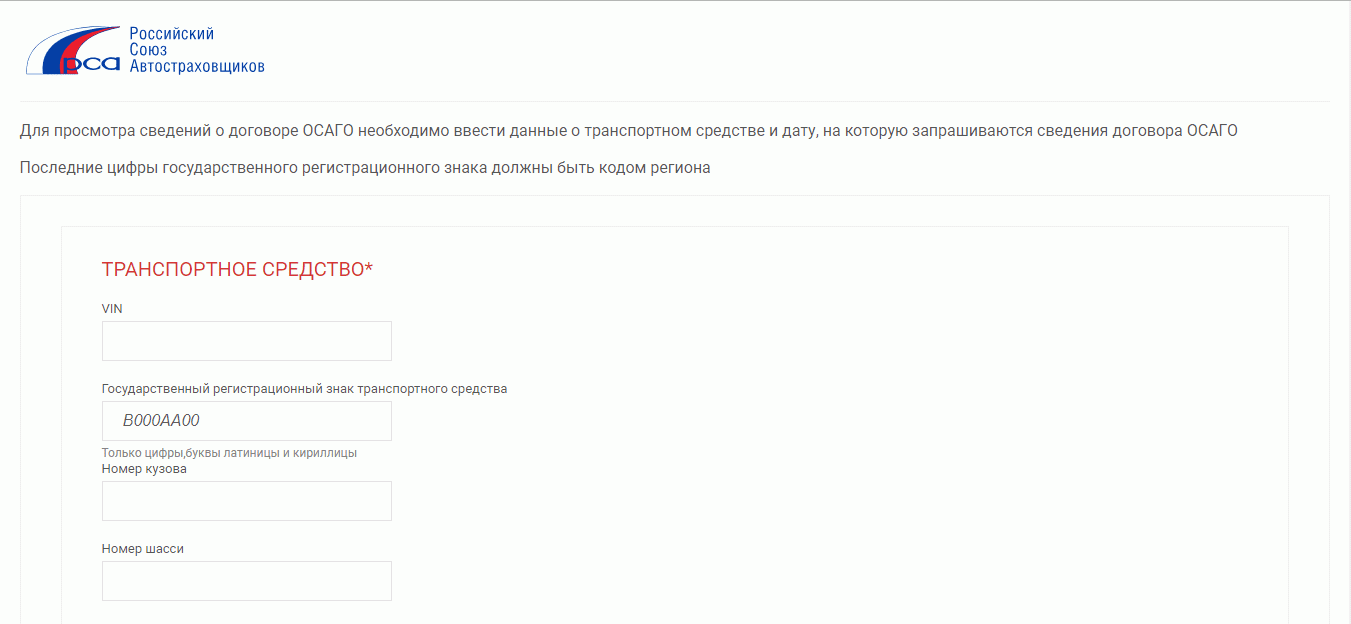 В этом отношении полезны графики-скрипты, которые позволяют определить, какую дисперсию вы можете вложить, например, в регрессию главных компонентов (PCR), что мы и попробуем дальше.
В этом отношении полезны графики-скрипты, которые позволяют определить, какую дисперсию вы можете вложить, например, в регрессию главных компонентов (PCR), что мы и попробуем дальше.
ПЦР с набором данных корпуса
Теперь мы решим проблему регрессии с помощью ПЦР. Я буду использовать набор данных о старом жилье, который также хранится в UCI MLR.Опять же, согласно документации, эти данные состоят из 14 переменных и 504 записей из разных городов где-то в США. Все, что нам нужно для выполнения ПЦР, — это провести ПЦР и передать результаты
ПК в OLS. Давайте попробуем предсказать среднюю стоимость домов, занимаемых владельцами, в тысячах долларов ( MEDV ), используя первые три ПК из PCA.домовВ печатном обзоре показаны два важных элемента информации. Во-первых, три оценочных коэффициента (плюс точка пересечения) считаются значимыми (
).Во-вторых, предсказуемость, определяемая (коэффициент детерминации, в большинстве случаев такой же, как квадрат коэффициента корреляции Пирсона), составляла 0,63.Затем мы сравним эту простую модель с моделью OLS, включающей все 14 переменных, и, наконец, сравним наблюдаемые и прогнозируемые графики MEDV для обеих моделей. Обратите внимание, что в синтаксисе lm ответ
дается слева от тильды, а набор предикторов - справа. Более того, при наличии аргумента для данных вы можете избежать необходимости вводить все имена переменных для полной модели () и просто использовать ..# Установите лм, используя все 14 варов модДомаПолный
Здесь полная модель показывает небольшое улучшение посадки (
). Высокая значимость большинства оценок коэффициентов свидетельствует о хорошо спланированном эксперименте. Тем не менее, примечательно, что такое сокращение от 13 до трех ковариат по-прежнему дает точную модель.Кстати, вы, вероятно, заметили, что обе модели недооценили MEDV в городах с MEVD стоимостью 50 000 долларов. Я предполагаю, что отсутствующие значения были установлены на MEVD = 50.
Заключительная,


- Алгоритм SVD основан на фундаментальных свойствах линейной алгебры, включая диагонализацию матрицы. PCA на основе SVD является частью своего решения и сохраняет уменьшенное количество ортогональных ковариат, которые объясняют как можно большую дисперсию.
- Используйте PCA при работе с данными большой размерности. Он нечувствителен к корреляции между переменными и эффективен при обнаружении выбросов в выборке.
- Если вы планируете использовать результаты PCA для последующих анализов, в этом процессе должны быть предприняты все меры.Хотя ПЦР, как правило, уступает по эффективности многочисленным методам, она все же имеет преимущество в интерпретируемости и может быть эффективной во многих условиях.
Мы приветствуем все отзывы об этих руководствах, пожалуйста, перейдите на вкладку «Контакты» и оставьте свои комментарии. Я также ценю предложения. Наслаждаться!
Связанные
Руководство для начинающих по собственным векторам, собственным значениям, PCA, ковариации и энтропии
Содержание
Этот пост знакомит с собственными векторами и их отношениями к матрицам простым языком и без особых математических выкладок. Он основан на этих идеях для объяснения ковариации, анализа главных компонентов и информационной энтропии.
Он основан на этих идеях для объяснения ковариации, анализа главных компонентов и информационной энтропии.
Собственное значение в собственном векторе происходит от немецкого языка и означает что-то вроде «очень собственный». Например, по-немецки «mein eigenes Auto» означает «моя собственная машина». Итак, eigen обозначает особую связь между двумя вещами. Что-то особенное, характерное и определенное. Эта машина или этот вектор принадлежит мне, а не кому-то другому.
Матрицы в линейной алгебре — это просто прямоугольные массивы чисел, набор скалярных значений в скобках, как электронная таблица.Все квадратные матрицы (например, 2 x 2 или 3 x 3) имеют собственные векторы, и у них есть особые отношения с ними, как у немцев со своими автомобилями.
Узнайте, как применять искусственный интеллект для моделирования »
Мы определим эту связь после краткого обзора того, что делают матрицы и как они соотносятся с другими числами.
Матрицы полезны, потому что с ними можно делать что-то вроде сложения и умножения. Если вы умножите вектор v на матрицу A , вы получите другой вектор b , и можно сказать, что матрица выполнила линейное преобразование входного вектора.
Если вы умножите вектор v на матрицу A , вы получите другой вектор b , и можно сказать, что матрица выполнила линейное преобразование входного вектора.
Av = b
Он отображает один вектор v на другой, b .
Проиллюстрируем на конкретном примере. (Вы можете увидеть, как выполняется этот тип матричного умножения, называемый скалярным произведением.)
Таким образом, A превратил v в b . На приведенном ниже графике мы видим, как матрица сопоставила короткую нижнюю линию v длинной высокой линии b .
Вы можете подавать один положительный вектор за другим в матрицу A, и каждый будет проецироваться на новое пространство, которое простирается все выше и дальше вправо.
Представьте, что все входные векторы v находятся в нормальной сетке, например:
И матрица проецирует их все в новое пространство, подобное приведенному ниже, которое содержит выходные векторы b :
Здесь вы можете увидеть два соседних места:
( Кредит: Уильям Гулд, Stata Blog )
А вот анимация, демонстрирующая работу матрицы по преобразованию одного пространства в другое:
Синие линии — собственные векторы.
Вы можете представить себе матрицу, подобную порыву ветра, невидимую силу, дающую видимый результат. И порыв ветра должен дуть в определенном направлении. Собственный вектор говорит вам, в каком направлении движется матрица.
( Кредит: Википедия )
Итак, какой из всех векторов, на которые воздействует матрица, проходящая через одно пространство, является собственным? Это тот, что изменяет длину, но не направление ; то есть собственный вектор уже указывает в том же направлении, в котором матрица подталкивает все векторы.Собственный вектор похож на флюгер. Собственный флюгер.
Таким образом, определение собственного вектора — это вектор, который реагирует на матрицу, как если бы эта матрица была скалярным коэффициентом. В этом уравнении A — матрица, x — вектор, а лямбда — скалярный коэффициент, например 5, 37 или пи.
Можно также сказать, что собственные векторы — это оси, вдоль которых действует линейное преобразование, растягивающее или сжимающее входные векторы. Это линии изменения, которые представляют действие большей матрицы, самой «линии» линейного преобразования.
Это линии изменения, которые представляют действие большей матрицы, самой «линии» линейного преобразования.
Обратите внимание, что мы используем множественное число — оси и линии. Так же, как у немца может быть Volkswagen для продуктовых покупок, Mercedes для деловых поездок и Porsche для увеселительных поездок (каждый из которых служит определенной цели), квадратные матрицы могут иметь столько собственных векторов, сколько у них размеров; т.е. матрица 2 x 2 может иметь два собственных вектора, матрица 3 x 3 3, а матрица n x n может иметь n собственных векторов, каждый из которых представляет свою линию действия в одном измерении.1
Поскольку собственные векторы определяют оси главных сил, по которым матрица перемещает входные данные, они полезны при разложении матрицы; я.е. диагонализация матрицы по собственным векторам. Поскольку эти собственные векторы представляют матрицу, они выполняют ту же задачу, что и автокодеры, используемые глубокими нейронными сетями.
Процитируем Йошуа Бенджио:
Многие математические объекты можно лучше понять, разбив их на составные части или обнаружив некоторые их свойства, которые являются универсальными, не обусловленными тем, как мы их представляем.

Например, целые числа можно разложить на простые множители.То, как мы представляем число 12, будет меняться в зависимости от того, записываем ли мы его в десятичном или двоичном формате, но всегда будет верно, что 12 = 2 × 2 × 3.
Из этого представления мы можем сделать вывод о полезных свойствах, например о том, что 12 не делится на 5 или что любое целое число, кратное 12, будет делиться на 3.
Так же, как мы можем узнать что-то об истинной природе целого числа, разложив его на простые множители, мы также можем разложить матрицы таким образом, чтобы показать нам информацию об их функциональных свойствах, которая не очевидна из представления матрицы в виде массива элементы.
Один из наиболее широко используемых видов разложения матриц называется разложением по собственным значениям, при котором мы разлагаем матрицу на набор собственных векторов и собственных значений.

PCA — это инструмент для поиска закономерностей в данных большой размерности, таких как изображения. Практики машинного обучения иногда используют PCA для предварительной обработки данных для своих нейронных сетей. Путем центрирования, вращения и масштабирования данных PCA отдает приоритет размерности (позволяя отказаться от некоторых измерений с низкой дисперсией) и может улучшить скорость сходимости нейронной сети и общее качество результатов.
Заинтересованы в обучении с подкреплением?
Автоматически применять RL к сценариям использования моделирования (например, колл-центры, складские помещения и т. Д.) С помощью Pathmind.
НачатьЧтобы перейти к PCA, мы собираемся быстро определить некоторые основные статистические идеи — среднее значение , стандартное отклонение, дисперсию и ковариацию — чтобы мы могли соединить их вместе позже. Их уравнения тесно связаны.
Среднее значение — это просто среднее значение всех x в наборе X, которое находится путем деления суммы всех точек данных на количество точек данных, n .
Стандартное отклонение , как бы забавно это ни звучало, это просто квадратный корень из среднего квадрата расстояния точек данных до среднего. В приведенном ниже уравнении числитель содержит сумму разностей между каждой точкой данных и средним значением, а знаменатель — это просто количество точек данных (минус один), дающее среднее расстояние.
Дисперсия — это мера разброса данных. Если я возьму команду голландских баскетболистов и измерю их рост, эти измерения не будут сильно отличаться.2 .
Как для дисперсии, так и для стандартного отклонения, возведение в квадрат разностей между точками данных и средним значением делает их положительными, так что значения выше и ниже среднего не компенсируют друг друга.
Предположим, вы построили возраст (ось x) и рост (ось y) этих людей (установив среднее значение равным нулю) и получили продолговатую диаграмму рассеяния:
PCA пытается провести прямые пояснительные линии через данные, как линейная регрессия.
Каждая прямая линия представляет «главный компонент» или отношение между независимой и зависимой переменной. Хотя существует столько же основных компонентов, сколько измерений в данных, роль PCA состоит в том, чтобы определить их приоритетность.
Первый главный компонент делит диаграмму рассеяния пополам с прямой линией таким образом, чтобы объяснить наибольшую дисперсию; то есть он следует по самому длинному измерению данных. (Это совпадает с наименьшей ошибкой, что выражено красными линиями…) На графике ниже это срезает длину «багета».”
Второй главный компонент прорезает данные перпендикулярно первому, согласуя ошибки, вызванные первым. На приведенном выше графике есть только два основных компонента, но если бы он был трехмерным, третий компонент соответствовал бы ошибкам из первого и второго основных компонентов и так далее.
В то время как мы представили матрицы как нечто, что преобразовывает один набор векторов в другой, другой способ думать о них — это описание данных, которые фиксируют силы, действующие на них, силы, с помощью которых две переменные могут относиться друг к другу, как выражено по их дисперсии и ковариации.
Представьте, что мы составляем квадратную матрицу чисел, которые описывают дисперсию данных и ковариацию между переменными. Это ковариационная матрица . Это эмпирическое описание наблюдаемых нами данных.
Нахождение собственных векторов и собственных значений ковариационной матрицы эквивалентно подгонке этих прямых линий главных компонент к дисперсии данных. Почему? Поскольку собственные векторы отслеживают основные силовые линии , а оси наибольшей дисперсии и ковариации показывают, где данные наиболее подвержены изменению.
Подумайте об этом так: если переменная изменяется, на нее действует известная или неизвестная сила. Если две переменные изменяются вместе, по всей вероятности, это либо потому, что одна действует на другую, либо они обе подвергаются одной и той же скрытой и неназванной силе.
Когда матрица выполняет линейное преобразование, собственные векторы отслеживают силовые линии, применяемые ко входу; когда матрица заполняется дисперсией и ковариацией данных, собственные векторы отражают силы, которые были приложены к данным. Один применяет силу, а другой отражает ее.
Один применяет силу, а другой отражает ее.
Собственные значения — это просто коэффициенты, прикрепленные к собственным векторам, которые определяют величину осей. В этом случае они являются мерой ковариации данных. Ранжируя собственные векторы в порядке их собственных значений, от наибольшего к наименьшему, вы получаете главные компоненты в порядке значимости.
Для матрицы 2 x 2 ковариационная матрица может выглядеть так:
Числа в верхнем левом и нижнем правом углу представляют собой дисперсию переменных x и y, соответственно, в то время как идентичные числа в нижнем левом и верхнем правом углу представляют собой ковариацию между x и y.Из-за этого тождества такие матрицы известны как симметричные. Как видите, ковариация положительна, поскольку график в верхней части раздела PCA указывает вверх и вправо.
Если две переменные увеличиваются и уменьшаются вместе (линия идет вверх и вправо), у них есть положительная ковариация, а если одна уменьшается, а другая увеличивается, они имеют отрицательную ковариацию (линия идет вниз и вправо).
( Кредит: Винсент Спруит, )
Обратите внимание: когда одна или другая переменная вообще не движется, а на графике нет диагонального движения, ковариации нет вообще.Ковариация отвечает на вопрос: танцуют ли эти две переменные вместе? Если один остается нулевым, пока другой движется, ответ отрицательный.
Кроме того, в приведенном ниже уравнении вы заметите, что существует лишь небольшая разница между ковариацией и дисперсией.
против
Самое замечательное в вычислении ковариации заключается в том, что в многомерном пространстве, где вы не можете наблюдать за взаимосвязями между переменными, вы можете узнать, как две переменные движутся вместе, по положительному, отрицательному или несуществующему характеру их ковариации.( Корреляция — это своего рода нормализованная ковариация со значением от -1 до 1.)
Подводя итог, ковариационная матрица определяет форму данных. Диагональный разброс по собственным векторам выражается ковариацией, а разброс по осям x и y выражается дисперсией.
Причинность имеет плохую репутацию в статистике, так что воспринимайте это с недоверием:
Хотя это не совсем точно, это может помочь думать о каждом компоненте как о причинной силе в вышеприведенном примере с голландским баскетболистом, причем первым главным компонентом является возраст; второй возможно пол; третья национальность (подразумевая разные системы здравоохранения наций), и каждая из них занимает свое собственное измерение в зависимости от роста.Каждый действует на высоту в разной степени. Вы можете рассматривать ковариацию как следы возможной причины.
Изменение базы
Поскольку собственные векторы ковариационной матрицы ортогональны друг другу, их можно использовать для переориентации данных с осей x и y на оси, представленные главными компонентами. Вы переустанавливаете систему координат для набора данных в новом пространстве, определяемом его линиями наибольшего отклонения.
Оси x и y, которые мы показали выше, являются так называемыми базисом матрицы; то есть они предоставляют точкам матрицы координаты x, y. Но можно преобразовать матрицу по другим осям; например, собственные векторы матрицы могут служить основой нового набора координат для той же матрицы. Матрицы и векторы сами по себе являются животными, независимо от чисел, связанных с определенной системой координат, такой как x и y.
Но можно преобразовать матрицу по другим осям; например, собственные векторы матрицы могут служить основой нового набора координат для той же матрицы. Матрицы и векторы сами по себе являются животными, независимо от чисел, связанных с определенной системой координат, такой как x и y.
На приведенном выше графике мы показываем, как один и тот же вектор v может быть расположен по-разному в двух системах координат: оси x-y показаны черным цветом, а две другие оси показаны красными штрихами.В первой системе координат v = (1,1), а во второй v = (1,0), но сама v не изменилась. Таким образом, векторы и матрицы можно абстрагировать от чисел, указанных в скобках.
Это имеет глубокие и почти духовные последствия, одно из которых состоит в том, что не существует естественной системы координат, а математические объекты в n-мерном пространстве подлежат множественному описанию. (Изменение базисов матриц также упрощает манипулирование ими.)
Изменение базы векторов примерно аналогично изменению базы чисел; я.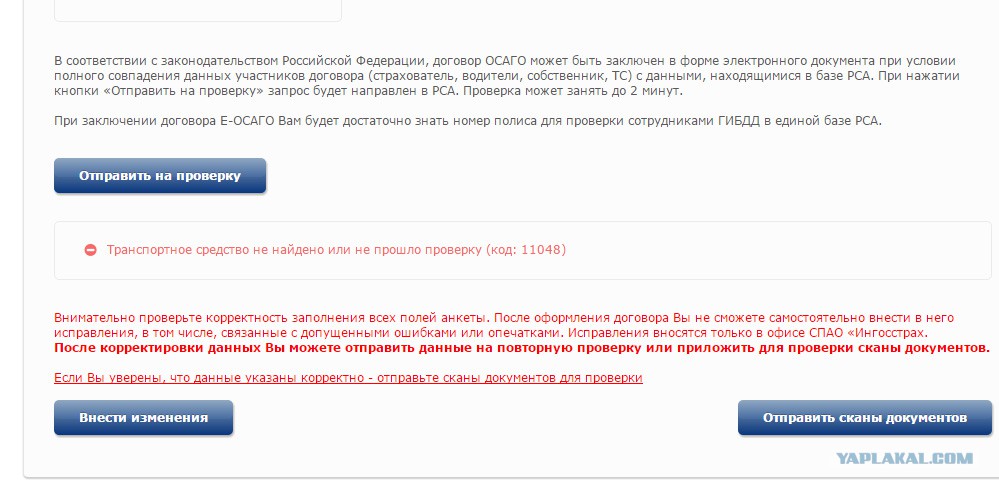 е. количество девять может быть описано как 9 в десятичной системе счисления, как 1001 в двоичной системе счисления и как 100 как в третьей (т.е. 1, 2, 10, 11, 12, 20, 21, 22, 100 <- то есть «девять») . То же количество, разные символы; тот же вектор, разные координаты.
е. количество девять может быть описано как 9 в десятичной системе счисления, как 1001 в двоичной системе счисления и как 100 как в третьей (т.е. 1, 2, 10, 11, 12, 20, 21, 22, 100 <- то есть «девять») . То же количество, разные символы; тот же вектор, разные координаты.
В теории информации термин энтропия относится к информации, которой у нас нет (обычно люди определяют «информацию» как то, что они знают, и жаргон снова восторжествовал, перевернув простой язык с ног на голову в ущерб непосвященным) .Информация, которой мы не располагаем о системе, ее энтропии, связана с ее непредсказуемостью: насколько она может нас удивить.
Если вы знаете, что на определенной монете есть выпуклые головы с обеих сторон, то подбрасывание монеты не дает вам абсолютно никакой информации, потому что каждый раз это будет орел. Необязательно переворачивать, чтобы узнать. Мы бы сказали, что двуглавая монета не содержит информации, потому что она не может вас удивить.
Сбалансированная двусторонняя монета действительно содержит элемент неожиданности при каждом подбрасывании монеты.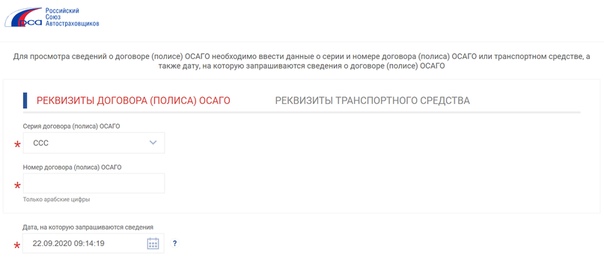 И шестигранный кубик, по тому же аргументу, содержит еще больше неожиданностей при каждом броске, который может дать любой из шести результатов с одинаковой частотой. Оба эти объекта содержат информацию в техническом смысле.
И шестигранный кубик, по тому же аргументу, содержит еще больше неожиданностей при каждом броске, который может дать любой из шести результатов с одинаковой частотой. Оба эти объекта содержат информацию в техническом смысле.
А теперь представим, что игральная кость загружена, выпадает «три» в пяти из шести бросков, и мы выясняем, что игра подстроена. Внезапно количество неожиданности, производимой этим кубиком при каждом броске, значительно уменьшается. Мы понимаем тенденцию в поведении матрицы, которая дает нам большую способность к прогнозированию.
Понимание того, что матрица загружена, аналогично поиску главного компонента в наборе данных. Вы просто определяете лежащий в основе шаблон.
Эта передача информации от того, что мы не знаем, о системе, до того, что мы знаем, , представляет собой изменение энтропии. Проницательность снижает энтропию системы. Получайте информацию, уменьшайте энтропию. Это получение информации. И да, этот тип энтропии субъективен в том смысле, что он зависит от того, что мы знаем об имеющейся системе. (Fwiw, получение информации является синонимом расхождения Кульбака-Лейблера, которое мы кратко исследовали в этом руководстве по ограниченным машинам Больцмана.)
(Fwiw, получение информации является синонимом расхождения Кульбака-Лейблера, которое мы кратко исследовали в этом руководстве по ограниченным машинам Больцмана.)
Таким образом, каждый главный компонент, прорезающий диаграмму рассеяния, представляет собой уменьшение энтропии системы в ее непредсказуемости.
Так получилось, что объяснение формы данных по одному главному компоненту за раз, начиная с компонента, который составляет наибольшую дисперсию, аналогично просмотру данных по дереву решений.Первый компонент PCA, как и первое разбиение if-then-else в правильно сформированном дереве решений, будет осуществляться по тому измерению, которое в наибольшей степени снижает непредсказуемость.
1) В некоторых случаях матрицы могут не иметь полного набора собственных векторов; они могут иметь самое большее количество линейно независимых собственных векторов, соответствующее их порядку или количеству измерений.
Другие сообщения в Pathmind Wiki
Анализ основных компонентов в
рандовАнализ основных компонентов
Я настраиваю записную книжку для выполнения анализа основных компонентов. Методы PCA очень полезны для исследования данных, когда набор данных «широкий», имеется много столбцов для количества строк точек данных. PCA ищет корреляции между столбцами путем поиска векторов (собственных векторов), которые сильно коррелируют с данными в столбцах (высокие собственные значения). Мы надеемся, что путем поиска этих собственных векторов с высокими собственными значениями можно уменьшить размерность набора данных.
Методы PCA очень полезны для исследования данных, когда набор данных «широкий», имеется много столбцов для количества строк точек данных. PCA ищет корреляции между столбцами путем поиска векторов (собственных векторов), которые сильно коррелируют с данными в столбцах (высокие собственные значения). Мы надеемся, что путем поиска этих собственных векторов с высокими собственными значениями можно уменьшить размерность набора данных.
PCA — это тип линейного преобразования заданного набора данных, который имеет значения для определенного количества переменных (координат) для определенного количества пробелов.Это линейное преобразование подгоняет этот набор данных к новой системе координат таким образом, что наиболее значительная дисперсия обнаруживается по первой координате, а каждая последующая координата ортогональна последней и имеет меньшую дисперсию. Таким образом, вы преобразуете набор из x коррелированных переменных по y выборкам в набор из p некоррелированных главных компонентов по тем же выборкам.
Если многие переменные коррелируют друг с другом, все они будут вносить значительный вклад в один и тот же главный компонент.Каждый главный компонент суммирует определенный процент от общей вариации в наборе данных. Если ваши исходные переменные сильно коррелированы друг с другом, вы сможете аппроксимировать большую часть сложности в своем наборе данных с помощью всего нескольких основных компонентов. По мере добавления новых основных компонентов вы суммируете все больше и больше исходного набора данных. Добавление дополнительных компонентов делает вашу оценку общего набора данных более точной, но при этом более громоздкой.
Проще говоря, собственный вектор — это направление, например «вертикальное» или «45 градусов», в то время как собственное значение — это число, показывающее, насколько велика дисперсия данных в этом направлении.Собственный вектор с наивысшим собственным значением, следовательно, является первой главной компонентой.
Стандартизация переменных
Если вы хотите сравнить разные переменные, которые имеют разные единицы измерения, имеют очень разные дисперсии, рекомендуется сначала стандартизировать переменные.
Тем не менее, хотите ли вы стандартизировать или нет, зависит от вопроса, который вы задаете, см. Это обсуждение обмена стеками
Если переменные не стандартизированы, в первом главном компоненте будут преобладать переменные, показывающие наибольшую дисперсию.
- Почему по умолчанию выполняется изменение масштаба данных?
Вы склонны использовать ковариационную матрицу, когда масштабы переменных аналогичны, и матрицу корреляции, когда переменные находятся в разных масштабах.
Использование корреляционной матрицы эквивалентно стандартизации каждой из переменных (для среднего значения 0 и стандартного отклонения 1)
Вспомните разницу между корреляцией и ковариацией. При корреляции вы изменяете масштаб путем деления на норму каждого измерения.{-2} \). Мы не хотим, чтобы результат нашего PCA изменялся в зависимости от единиц измерения измерения. Чтобы избежать подобных проблем, мы масштабируем наши данные так, чтобы каждое измерение имело отклонение 1.
Таким образом, было бы лучше сначала стандартизировать переменные, чтобы все они имели дисперсию 1 и среднее значение 0, а затем провести анализ главных компонентов на стандартизированных данных. Это позволило бы нам найти основные компоненты, которые обеспечивают наилучшее низкоразмерное представление вариации исходных данных, без чрезмерного смещения со стороны тех переменных, которые показывают наибольшую дисперсию исходных данных.
Вы можете стандартизировать переменные в R с помощью функции scale () .
Например, чтобы стандартизировать значения 18 переменных почвы на каждом участке, мы вводим: standardizedvalues <- as.data.frame (scale (T.18 [1:18]))
Обратите внимание, что мы используем функцию as.data.frame () для преобразования вывода scale () в кадр данных, который является переменной R того же типа, что и переменная T.18 .
Мы можем проверить, что каждая из стандартизованных переменных, хранящихся в стандартизированных значениях , имеет среднее значение 0 и стандартное отклонение 1, набрав:
#sapply (стандартные значения, среднее)
# V2 V3 V4 V5 V6 V7
# -8. 591766e-16 -6.776446e-17 8.045176e-16 -7.720494e-17 -4.073935e-17 -1.395560e-17
# V8 V9 V10 V11 V12 V13
# 6.958263e-17 -1.042186e-16 -1.221369e-16 3.649376e-17 2.093741e-16 3.003459e-16
# V14
# -1.034429e-16
#sapply (стандартные значения, SD)
# V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14
# 1 1 1 1 1 1 1 1 1 1 1 1 1  591766e-16 -6.776446e-17 8.045176e-16 -7.720494e-17 -4.073935e-17 -1.395560e-17
# V8 V9 V10 V11 V12 V13
# 6.958263e-17 -1.042186e-16 -1.221369e-16 3.649376e-17 2.093741e-16 3.003459e-16
# V14
# -1.034429e-16
#sapply (стандартные значения, SD)
# V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14
# 1 1 1 1 1 1 1 1 1 1 1 1 1
591766e-16 -6.776446e-17 8.045176e-16 -7.720494e-17 -4.073935e-17 -1.395560e-17
# V8 V9 V10 V11 V12 V13
# 6.958263e-17 -1.042186e-16 -1.221369e-16 3.649376e-17 2.093741e-16 3.003459e-16
# V14
# -1.034429e-16
#sapply (стандартные значения, SD)
# V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14
# 1 1 1 1 1 1 1 1 1 1 1 1 1 Мы видим, что все средние значения стандартизованных переменных являются очень маленькими числами и поэтому по существу равны 0, а стандартные отклонения стандартизованных переменных все равны 1.
- Почему по умолчанию по центру?
Допустим, мы не по центру. Мы можем связать PCA с направлениями с наивысшей ковариацией. Когда мы вычисляем выборочную ковариацию, мы вычитаем среднее значение из каждого наблюдения. Если мы пропустим этот шаг (не центрирование), то первая ось PCA всегда будет указывать в сторону центра масс.
Некоторые функции в R, вычисляющие PCA, по умолчанию не центрируются. Может быть веская причина не центрировать (например,, вы уже центрировали большой набор данных и смотрите только на подвыборку), но в целом вам всегда следует центрировать данные при выполнении PCA.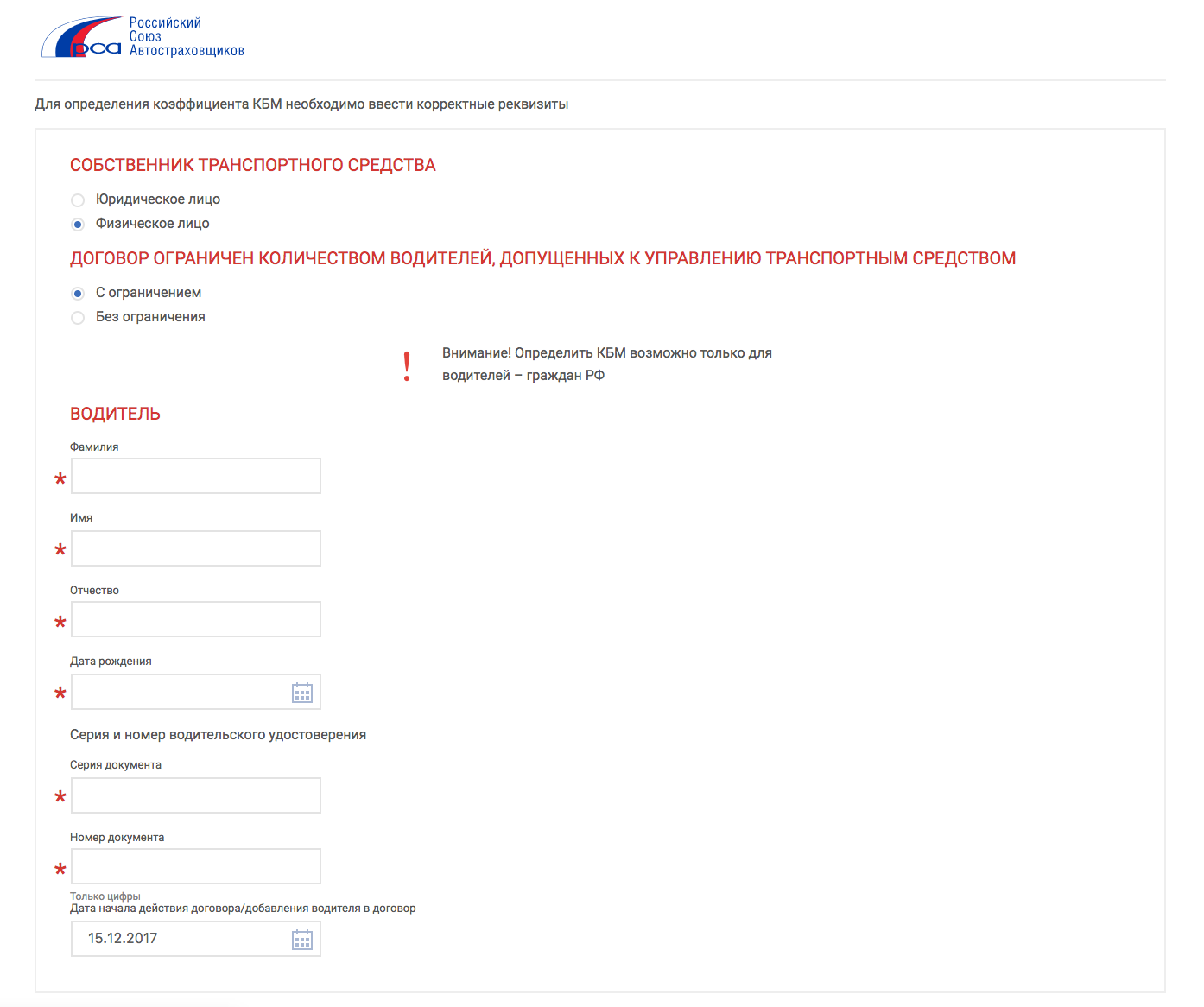
Создание PCA
Пакет prcomp содержит масштаб аргумента , который масштабирует переменные, используемые в PCA, поэтому нет необходимости вручную масштабировать, как указано выше.
Загрузка данных, выбор столбцов для включения в PCA и запуск масштабированного и центрированного PCA.
Env_18 <- читать.csv ("C: / Users / Cian / Documents / PhD / Data / Meggis Data / Env_18.csv")
colnames (Env_18) [1] <- "Param"
for (я в 1:18) {
rownames (Env_18) [i] <- as.character (droplevels (Env_18 $ Param [i]))
}
Env_18 <- Env_18 [, - 1]
#str (Env_18)
Env.18.pca <- prcomp (Env_18, center = TRUE, scale. = TRUE)
#summary (Env.18.pca)
#str (Env.18.pca)
# Перенос данных, чтобы мы смотрели на корреляцию между самими характеристиками почвы, а не на корреляцию между участками.T.18 <- as.data.frame (t (Env_18))
T.18.pca <- prcomp (T.18, center = TRUE, scale. = TRUE)
#summary (T.18.pca) - центр, масштабирование, стандартное отклонение каждого главного компонента.

$ center, $ scale, $ sdev - Взаимосвязь (корреляция или антикорреляция и т. Д.) Между исходными переменными и главными компонентами
$ вращение - Значения каждой выборки по основным компонентам
$ x Теория результатов PCA
Этот код рассчитает результаты PCA для переменных (т. Е.2
#helper function
var_coord_func <- функция (загрузки, comp.sdev) {
загрузки * comp.sdev
}
# Вычислить координаты
loadings <- T.18.pca $ вращение
sdev <- T.18.pca $ sdev
var.coord <- t (применить (loadings, MARGIN = 1, var_coord_func, sdev))
голова (вар.координаты [, 1: 4]) ## PC1 PC2 PC3 PC4
## m_gv 0.1112659 -0.8397329 -0.27438780 -0.02808150
## m_pH_h3O -0. 3770343 0.3365268 -0.78532581 -0.02319610
## m_pH_Ca -0.3978461 0.1885975 -0.73551774 -0.08737664
## m_CN 0.1787622 -0.6555604 0.60132147 0.15584940
## m_Cl -0.4319542 -0.3695436 -0.07478097 0.57131811
## m_NO3 0,2612686 -0,5962655 -0,49718902 -0,44795962 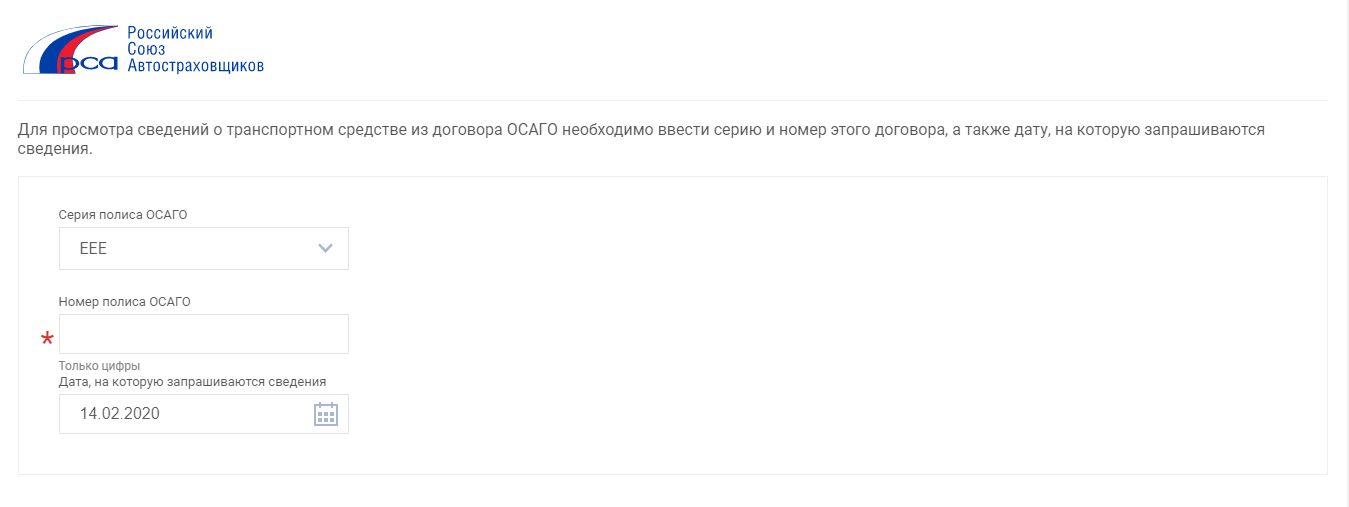 3770343 0.3365268 -0.78532581 -0.02319610
## m_pH_Ca -0.3978461 0.1885975 -0.73551774 -0.08737664
## m_CN 0.1787622 -0.6555604 0.60132147 0.15584940
## m_Cl -0.4319542 -0.3695436 -0.07478097 0.57131811
## m_NO3 0,2612686 -0,5962655 -0,49718902 -0,44795962
3770343 0.3365268 -0.78532581 -0.02319610
## m_pH_Ca -0.3978461 0.1885975 -0.73551774 -0.08737664
## m_CN 0.1787622 -0.6555604 0.60132147 0.15584940
## m_Cl -0.4319542 -0.3695436 -0.07478097 0.57131811
## m_NO3 0,2612686 -0,5962655 -0,49718902 -0,44795962 # вычислить Cos2 (квадраты компонентов переменной), или качество представления в заданном измерении
var.2
голова (var.cos2 [, 1: 4]) ## PC1 PC2 PC3 PC4
## m_gv 0,01238009 0,70515135 0,075288662 0,0007885708
## m_pH_h3O 0.14215486 0.11325025 0.616736633 0.0005380592
## m_pH_Ca 0,15828153 0,03556902 0,540986346 0,0076346773
## m_CN 0,03195592 0,42975950 0,361587515 0,02428
## m_Cl 0,18658447 0,13656246 0,005592193 0,3264043823
## m_NO3 0,06826130 0,35553253 0,247196926 0.2006678208 # Вычислить взносы
комп.cos2 <- применить (var.cos2, MARGIN = 2, FUN = sum)
contrib <- функция (var.cos2, comp.cos2) {var.cos2 * 100 / comp.cos2}
var.contrib <- t (применить (var. cos2, MARGIN = 1, contrib, comp.cos2))
голова (var.contrib [, 1: 4]) 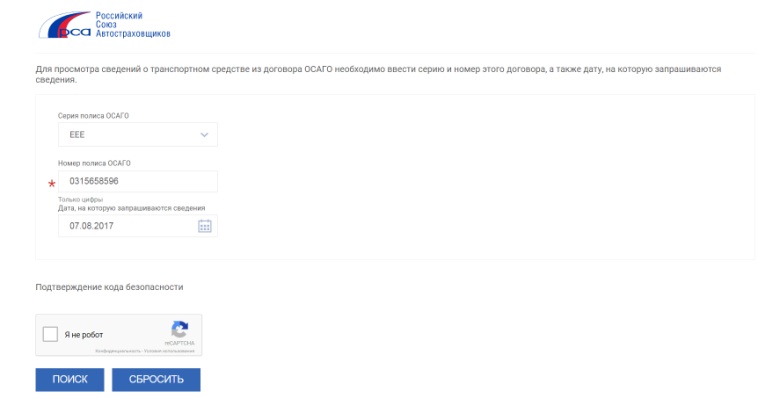 cos2, MARGIN = 1, contrib, comp.cos2))
голова (var.contrib [, 1: 4])
cos2, MARGIN = 1, contrib, comp.cos2))
голова (var.contrib [, 1: 4]) ## PC1 PC2 PC3 PC4
## m_gv 0.2028662 17.8681349 2.2542900 0,06399317
## m_pH_h3O 2.3294185 2.8696972 18.4663026 0,04366394
## m_pH_Ca 2.5936781 0.87 16.1981906 0.61956032
## m_CN 0.2). Обратите внимание, что сумма всех вкладов в столбце составляет 100
# Координаты лиц
# ::::::::::::::::::::::::::::::::::
ind.coord <- T.18.pca $ x
голова (ind.coord [, 1: 4])
## PC1 PC2 PC3 PC4
## aa 1.843619 0.6984034 1.331 0.8521719
## ab 1.499047 3.3314063 -0.13836903 -0.4757199
## ac 2.438382 2.3485011 -0.11155408 -1.0069934
## ba -4.068176 0.4089068 0.2 / d2)}
ind.cos2 <- применить (ind.coord, 2, cos2, d2)
голова (ind.cos2 [, 1: 4])
## PC1 PC2 PC3 PC4
## аа 0,3221090 0,046224592 1,833272e-01 0,06882002
## ab 0,1444967 0,713645955 1,231134e-03 0,01455225
## ac 0,3631827 0,3361 7.601385e-04 0,06194055
## ba 0,8227422 0,008312142 2,247494e-02 0,08577727
## bb 0,8706902 0,036753047 1,260538e-04 0,04434085
## bc 0,
29 0,009265135 6,2e-06 0,01721926 # Взносы физических лиц
# :::::::::::::::::::::::::::::::
contrib <- функция (инд. 2
}
ind.contrib <- t (применить (ind.coord, 1, contrib,
T.18.pca $ sdev, nrow (ind.coord)))
глава (инд.контриб [, 1: 4])  2
}
ind.contrib <- t (применить (ind.coord, 1, contrib,
T.18.pca $ sdev, nrow (ind.coord)))
глава (инд.контриб [, 1: 4])
2
}
ind.contrib <- t (применить (ind.coord, 1, contrib,
T.18.pca $ sdev, nrow (ind.coord)))
глава (инд.контриб [, 1: 4]) ## PC1 PC2 PC3 PC4
## аа 3.094253 0.6866526 3.21710 3.273971
## ab 2.045708 15.6235453 0.0318482443 1.020288
## ac 5.412734 7.7643643 0.0207003940 4.571658
## ba 15.066517 0.2353819 0.7520420308 7.779083
## bb 16.452371 1.0739134 0.0043522633 4.149311
## bc 16.410186 0,2583195 0,0002072405 1,537503 Визуализация PCA
Теперь пора построить PCA.
сначала рассмотрим пакет ggbiplot .
Вы создадите биплот, который включает положение каждой выборки в терминах ПК1 и ПК2, а также покажет вам, как исходные переменные отображаются на этом. Вы будете использовать пакет ggbiplot , который предлагает удобную и красивую функцию для построения биплотов. Двухуровневый график - это тип графика, который позволит вам визуализировать, как образцы соотносятся друг с другом в нашем PCA (какие образцы похожи, а какие разные), и одновременно покажет, как каждая переменная влияет на каждый главный компонент.
библиотека (devtools) ## Загрузка необходимого пакета: используйте этот #install_github ("vqv / ggbiplot")
библиотека (ggbiplot) ## Загрузка необходимого пакета: ggplot2 ## Загрузка необходимого пакета: plyr ## Загрузка необходимого пакета: весы ## Загрузка необходимого пакета: сетка библиотека (ggalt) ## Предупреждение: пакет 'ggalt' был собран под R версии 3.6,3 ## Зарегистрированные методы S3 заменены на 'ggalt':
## метод из
## grid.draw.absoluteGrob ggplot2
## grobHeight.absoluteGrob ggplot2
## grobWidth.absoluteGrob ggplot2
## grobX.absoluteGrob ggplot2
## grobY.absoluteGrob ggplot2 библиотека (ggforce) ## Предупреждение: пакет 'ggforce' был собран под R версии 3. 6.3  6.3
6.3 ggbiplot (Env.18.pca) ggbiplot (T.18.pca) #lets добавьте названия строк, чтобы мы могли видеть идентичность нанесенных точек.
ggbiplot (Env.18.pca, labels = rownames (Env_18)) ggbiplot (T.18.pca, labels = rownames (T.18)) Существует множество других пакетов для построения PCA. Другой набор пакетов - это семейство пакетов facto , которое снова использует функциональность ggplot
библиотека (factoextra) ## Предупреждение: пакет factoextra был собран под R версии 3.6,3 ## Добро пожаловать! Хотите узнать больше? См. Две книги, связанные с фактами, по адресу https://goo.gl/ve3WBa # участок под деревьями
fviz_eig (T.18.pca) # физические лица (строки)
fviz_pca_ind (T. 18.pca,
col.ind = "cos2", # Цвет по качеству представления
gradient.cols = c ("# 00AFBB", "# E7B800", "# FC4E07"),
Repel = TRUE # Избегать перекрытия текста
)  18.pca,
col.ind = "cos2", # Цвет по качеству представления
gradient.cols = c ("# 00AFBB", "# E7B800", "# FC4E07"),
Repel = TRUE # Избегать перекрытия текста
)
18.pca,
col.ind = "cos2", # Цвет по качеству представления
gradient.cols = c ("# 00AFBB", "# E7B800", "# FC4E07"),
Repel = TRUE # Избегать перекрытия текста
) # переменные (столбцы)
fviz_pca_var (Т.18.pca,
col.var = "contrib", # Раскрашиваем по вкладам в ПК
gradient.cols = c ("# 00AFBB", "# E7B800", "# FC4E07"),
Repel = TRUE # Избегать перекрытия текста
) #biplot
fviz_pca_biplot (T.18.pca, Repel = ИСТИНА,
col.var = "# 2E9FDF", # Цвет переменных
col.ind = "# 696969" # Цвет отдельных лиц
) библиотека (Фактошины) ## Предупреждение: пакет Factoshiny был собран под R версии 3.6,3 ## Загрузка необходимого пакета: FactoMineR ## Предупреждение: пакет 'FactoMineR' был собран под R версии 3. 6.3  6.3
6.3 ## Загрузка необходимого пакета: блестящий ## Загрузка необходимого пакета: FactoInvestigate ## Предупреждение: пакет FactoInvestigate был собран под R версии 3.6.3 #result <- Фактошины (Т.18) Дополнительные переменные
Качественные / категориальные переменные
Качественные / категориальные переменные могут использоваться для раскрашивания отдельных лиц (строк) по группам.Группирующая переменная должна иметь ту же длину, что и количество активных особей
. Код для извлечения данных из пакета Factoextra по результатам PCA
библиотека (factoextra)
# Собственные значения
eig.val <- get_eigenvalue (T.18.pca)
эиг.вал # Результаты для переменных (т.е. столбцов)
res.var <- get_pca_var (T.18.pca)
# res.var $ordin # Координаты
# res.var $ contrib # Вклад в ПК
#res. var $ cos2 # Качество представления
# Результатов для отдельных лиц (например, строки)
res.ind <- get_pca_ind (T.18.pca)
# res.ind $ordin # Координаты
# res.ind $ contrib # Вклад в ПК
# res.ind $ cos2 # Качество представления  var $ cos2 # Качество представления
# Результатов для отдельных лиц (например, строки)
res.ind <- get_pca_ind (T.18.pca)
# res.ind $ordin # Координаты
# res.ind $ contrib # Вклад в ПК
# res.ind $ cos2 # Качество представления
var $ cos2 # Качество представления
# Результатов для отдельных лиц (например, строки)
res.ind <- get_pca_ind (T.18.pca)
# res.ind $ordin # Координаты
# res.ind $ contrib # Вклад в ПК
# res.ind $ cos2 # Качество представления Решение, сколько основных компонентов оставить
Чтобы решить, сколько основных компонентов следует сохранить, обычно результаты анализа основных компонентов суммируют, создавая осыпной график, что мы можем сделать в R с помощью функции screeplot () :
т.18. pca <- prcomp (T.18, center = TRUE, scale. = TRUE)
screeplot (T.18.pca, type = "lines") Наиболее очевидное изменение наклона осыпи происходит на компоненте 4, который является «изгибом» осыпной площади. Следовательно, на основании графика осыпи можно утверждать, что следует сохранить первые три компонента.
Другой способ решить, сколько компонентов оставить, - использовать критерий Кайзера: мы должны сохранять только главные компоненты, для которых дисперсия превышает 1 (когда анализ главных компонентов применялся к стандартизированным данным). 2
2
## [1] 6.102590e + 00 3.946418e + 00 3.339795e + 00 1.232273e + 00 9.323371e-01
## [6] 7.314076e-01 6.372587e-01 3.753322e-01 3.178664e-01 1.847776e-01
## [11] 7.417828e-02 6.980869e-02 3.720730e-02 1.241689e-02 3.706036e-03
## [16] 2.339936e-03 2.868659e-04 1.028193e-32 Мы видим, что дисперсия выше 1 для главных компонентов 1, 2, 3 и 4 (которые имеют дисперсии 6,10, 3,95, 3,34 и 1,23 соответственно). Следовательно, используя критерий Кайзера, мы сохраним первые четыре основных компонента.
Третий способ решить, сколько основных компонентов оставить, - это решить сохранить количество компонентов, необходимых для объяснения хотя бы некоторой минимальной величины общей дисперсии. Например, если важно объяснить, по крайней мере, 80% дисперсии, мы должны сохранить первые четыре основных компонента, как мы можем видеть из выходных данных сводки (T.18.pca) , что первые четыре основных компонента объясняют 81,2% дисперсии (тогда как первые три компонента объясняют только 74. 4%, поэтому недостаточно).
4%, поэтому недостаточно).
сводка (T.18.pca) ## Значение компонентов:
## ПК1 ПК2 ПК3 ПК4 ПК5 ПК6 ПК7
## Стандартное отклонение 2,470 1,9866 1,8275 1,11008 0,9656 0,85522 0,7983
## Пропорция дисперсии 0,339 0,2192 0,1855 0,06846 0,0518 0,04063 0,0354
## Суммарная доля 0,339 0,5583 0,7438 0,81228 0,8641 0, 0,9401
## PC8 PC9 PC10 PC11 PC12 PC13 PC14
## Стандартное отклонение 0.61264 0,56380 0,42986 0,27236 0,26421 0,19289 0,11143
## Пропорция дисперсии 0,02085 0,01766 0,01027 0,00412 0,00388 0,00207 0,00069
## Совокупная доля 0,96097 0,97863 0,98889 0,99301 0,99689 0,99896 0,99965
## PC15 PC16 PC17 PC18
## Стандартное отклонение 0,06088 0,04837 0,01694 1,014e-16
## Пропорция дисперсии 0,00021 0,00013 0,00002 0,000e + 00
## Совокупная доля 0,99985 0,99998 1,00000 1.000e + 00
Интерпретация результатов
Теперь мы можем сгруппировать наши переменные и посмотреть, занимают ли группы одинаковое пространство в пространстве PCA, указывая на то, что они коррелированы друг с другом. Мы делаем это с помощью аргумента групп в ggbiplot
Мы делаем это с помощью аргумента групп в ggbiplot
# создание групп, включение эллипсов
T.18.pca <- prcomp (T.18, center = TRUE, scale. = TRUE)
site.groups <- c (rep ("a", 3), rep ("b", 3), rep ("c", 3), rep ("d", 3), rep ("e", 3) ), rep ("е", 3))
ggbiplot (T.18.pca, labels = rownames (T.18), groups = site.groups, ellipse = TRUE) # глядя на другие оси PCA
ggbiplot (T.18.pca, labels = rownames (T.18), groups = site.groups, ellipse = TRUE, choices = c (3,4)) показывает, что третья ось полезна для извлечения групп, таких как f, поэтому должна включать первые три оси, поскольку они содержат много вариаций.
Графические параметры с ggbiplot
Это также другие переменные, которые можно использовать для изменения биплотов. * Можно добавить круг в центр набора данных * Можно масштабировать образцы (obs.scale) и переменные (var.scale) * Можно полностью удалить стрелки, используя var.axes
T. 18.pca <- prcomp (T.18, center = TRUE, scale. = TRUE)
ggbiplot (T.18.pca, labels = rownames (T.18), groups = site.groups, ellipse = TRUE, circle = TRUE) 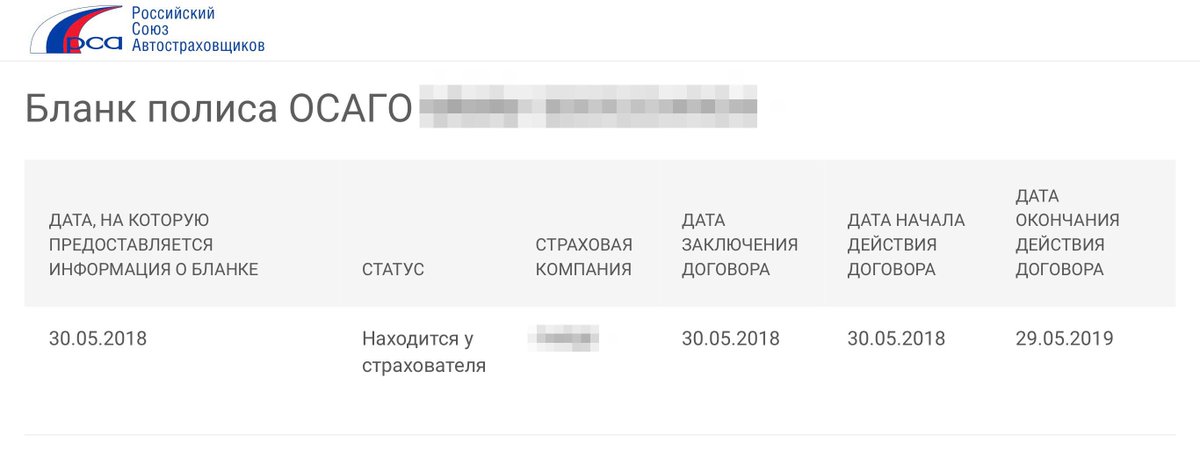 18.pca <- prcomp (T.18, center = TRUE, scale. = TRUE)
ggbiplot (T.18.pca, labels = rownames (T.18), groups = site.groups, ellipse = TRUE, circle = TRUE)
18.pca <- prcomp (T.18, center = TRUE, scale. = TRUE)
ggbiplot (T.18.pca, labels = rownames (T.18), groups = site.groups, ellipse = TRUE, circle = TRUE) ggbiplot (т.18. pca, labels = rownames (T.18), groups = site.groups, ellipse = TRUE, obs.scale = 1, var.scale = 1) ggbiplot (T.18.pca, labels = rownames (T.18), groups = site.groups, obs.scale = 1, var.scale = 1, var.axes = FALSE) +
theme_bw () +
geom_mark_hull (вогнутость = 5, развернуть = 0, радиус = 0, aes (fill = site.groups)) Поскольку ggbiplot основан на функции ggplot, вы можете использовать тот же набор графических параметров для изменения биплотов, что и для любого ggplot.
- Укажите цвета для использования в группах с помощью
scale_colour_manual () - Добавьте заголовок с
ggtitle () - Укажите тему
minimal ()или другие темы - Переместите легенду с темой
()
Многовариантные пакеты
До сих пор я использовал базовый пакет stats для проведения PCA. Но есть и другие пакеты, разработанные для облегчения набора многомерного анализа.
Но есть и другие пакеты, разработанные для облегчения набора многомерного анализа. ade4 и есть такой пакет.
Использование пакета ade4 для многомерного анализа вместо пакета базовой статистики. Комбинирование с графиками осыпи и сравнение функций построения графиков ade4 с индивидуальным построением графиков с использованием пакета ggplot Universe
библиотека (ade4) # многомерный анализ ##
## Прикрепляемый пакет: ade4 ## Следующий объект замаскирован из package: FactoMineR:
##
## reconst т.18.pca <- dudi.pca (T.18, scannf = F, nf = 8)
# $ Co - координаты переменных в пространстве PCA. Эквивалентно нагрузкам * sdev, рассчитанным в разделе теории выше для prcomp.
# $ Li соответствуют отдельным или ряду координат
разброс (T.18.pca) Настройка библиотек и основных тем сюжета
library (grid) # имеет функцию области просмотра, необходимую для вставки графика осыпи
библиотека (ggpubr) # для оформления готовых к публикации сюжетов ## Предупреждение: пакет 'ggpubr' был собран под R версии 3. 6,3 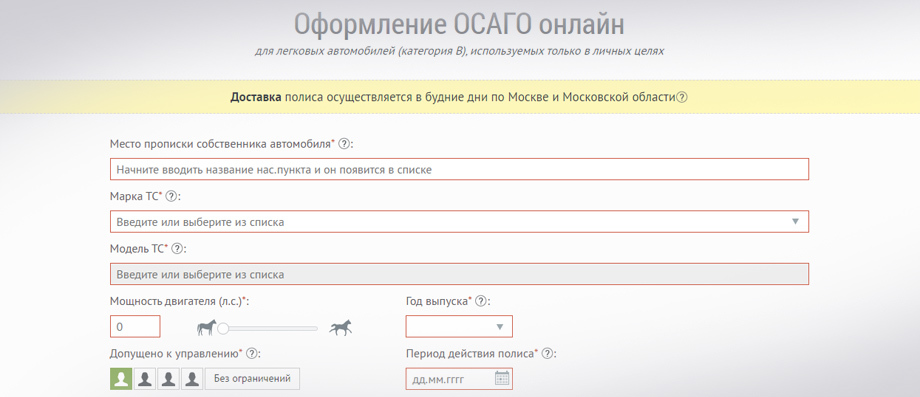 6,3
6,3 ## Загрузка необходимого пакета: magrittr ##
## Прикрепляемый пакет: 'ggpubr' ## Следующий объект замаскирован из package: plyr:
##
## mutate library (ggforce) # для хороших геометрий полигонов
library (ggalt) # содержит дополнительные геометрии
library (viridis) # несколько красивых цветовых палитр ## Предупреждение: пакет viridis был собран под R версии 3.6,3 ## Загрузка необходимого пакета: viridisLite ##
## Прикрепляемый пакет: viridis ## Следующий объект замаскирован из package: scale:
##
## viridis_pal библиотека (hrbrthemes) # несколько хороших тем для ggplot ## Предупреждение: пакет 'hrbrthemes' был собран под R версии 3.6.3 ## ПРИМЕЧАНИЕ. Для использования этих тем требуются шрифты Arial Narrow или Roboto Condensed. 
## Используйте hrbrthemes :: import_roboto_condensed () для установки Roboto Condensed и ##, если Arial Narrow отсутствует в вашей системе, см. Http://bit.ly/arialnarrow ### настроить сюжет, который мы будем использовать позже
ppp <- ggplot () +
Coord_fixed () +
labs (x = paste ("PCA 1", "(", round ((T.18.pca $ eig [1] / sum (T.18.pca $ eig)) * 100, 1), "% объяснил var ",") ", sep =" "),
y = paste ("PCA 2", "(", round ((T.18.pca $ eig [2] / sum (T.18.pca $ eig)) * 100, 1), "% объяснил var", ")", sep = "")) +
geom_hline (yintercept = 0, col = "темно-серый") +
geom_vline (xintercept = 0, col = "темно-серый") +
направляющие (size = guide_legend (title = "PCA 3 (18,6%)")) +
geom_segment (данные = T.18.pca $ co,
х = 0, у = 0,
xend = 2,5 * T.18.pca $ co [, 1], yend = 2,5 * T.18.pca $ co [, 2],
стрелка = стрелка (угол = 30, длина = единица измерения (0,25, "см"),
end = "last", type = "open"),
альфа = 0. 4) +
scale_color_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
theme_ipsum ()
# делаем график осыпи во вьюпорте
myscree <- function (eigs, x = 0.8, y = 0.1, just = c ("left", "center")) {
vp <- область просмотра (x = x, y = y, width = 0.2, height = 0.2, just = just)
data <- as.data.frame (cbind (factor (1: length (eigs)), eigs))
sp <- ggplot () +
geom_col (aes (x = V1, y = eigs), data = data, position = "stack") +
labs (x = NULL, y = NULL, title = "Scree Plot") +
тема (title = element_text (size = 6))
печать (sp, vp = vp)
} 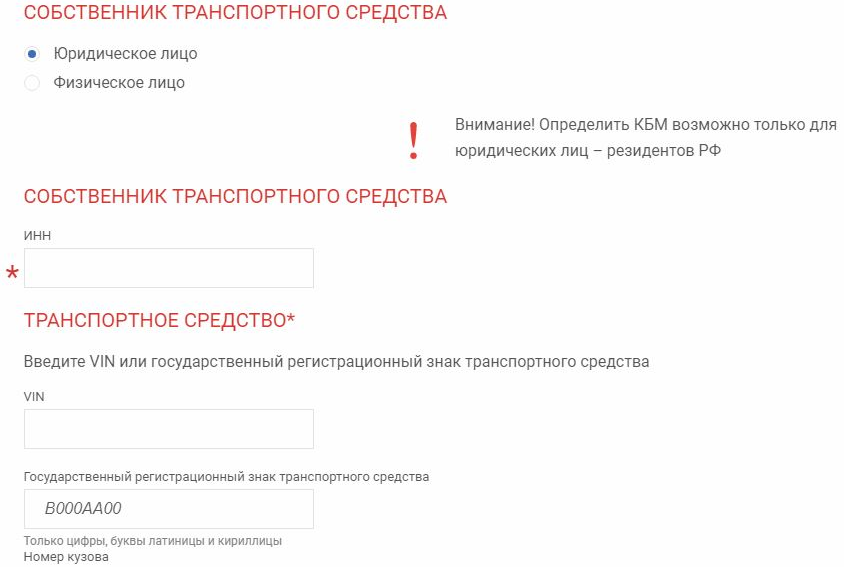 4) +
scale_color_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
theme_ipsum ()
# делаем график осыпи во вьюпорте
myscree <- function (eigs, x = 0.8, y = 0.1, just = c ("left", "center")) {
vp <- область просмотра (x = x, y = y, width = 0.2, height = 0.2, just = just)
data <- as.data.frame (cbind (factor (1: length (eigs)), eigs))
sp <- ggplot () +
geom_col (aes (x = V1, y = eigs), data = data, position = "stack") +
labs (x = NULL, y = NULL, title = "Scree Plot") +
тема (title = element_text (size = 6))
печать (sp, vp = vp)
}
4) +
scale_color_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
theme_ipsum ()
# делаем график осыпи во вьюпорте
myscree <- function (eigs, x = 0.8, y = 0.1, just = c ("left", "center")) {
vp <- область просмотра (x = x, y = y, width = 0.2, height = 0.2, just = just)
data <- as.data.frame (cbind (factor (1: length (eigs)), eigs))
sp <- ggplot () +
geom_col (aes (x = V1, y = eigs), data = data, position = "stack") +
labs (x = NULL, y = NULL, title = "Scree Plot") +
тема (title = element_text (size = 6))
печать (sp, vp = vp)
} Построение графика с использованием функции geom_mark_ellipse () в пакете ggforce
# установить коэффициент группировки для цвета, группировку по сайтам и добавление во фрейм данных
Т.18.pca $ li [, 1 + dim (T.18.pca $ li) [2]] = site.groups
# создание именованного логического вектора для отображения легенд. Хотите легенду о размере, но не о сайтах.
нога <- as.logical (c (1,0))
имена (нога) <- c ("размер", "столбец")
ppp +
geom_point (данные = T.18.pca $ li,
aes (x = Axis1,
y = Axis2,
size = Axis3,
col = T.18.pca $ li [, dim (T.18.pca $ li) [2]]), # раскраска на основе фактора группировки
show.legend = нога) +
scale_color_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
направляющие (size = guide_legend (title = "PCA 3 (18.6%) ")) +
geom_text (data = T.18.pca $ co,
aes (x = 2,5 * Comp1,
y = 2,5 * Comp2,
label = (colnames (T.18))),
размер = 2, альфа = 0,4) +
geom_mark_ellipse (data = T.18.pca $ li, aes (x = Axis1, y = Axis2,
группа = T.18.pca $ li [, dim (T.18.pca $ li) [2]],
fill = T.18.pca $ li [, dim (T.18.pca $ li) [2]]),
альфа = 0,4, развернуть = 0) +
scale_fill_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
гиды (fill = guide_legend (title = "Сайты"))  нога <- as.logical (c (1,0))
имена (нога) <- c ("размер", "столбец")
ppp +
geom_point (данные = T.18.pca $ li,
aes (x = Axis1,
y = Axis2,
size = Axis3,
col = T.18.pca $ li [, dim (T.18.pca $ li) [2]]), # раскраска на основе фактора группировки
show.legend = нога) +
scale_color_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
направляющие (size = guide_legend (title = "PCA 3 (18.6%) ")) +
geom_text (data = T.18.pca $ co,
aes (x = 2,5 * Comp1,
y = 2,5 * Comp2,
label = (colnames (T.18))),
размер = 2, альфа = 0,4) +
geom_mark_ellipse (data = T.18.pca $ li, aes (x = Axis1, y = Axis2,
группа = T.18.pca $ li [, dim (T.18.pca $ li) [2]],
fill = T.18.pca $ li [, dim (T.18.pca $ li) [2]]),
альфа = 0,4, развернуть = 0) +
scale_fill_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
гиды (fill = guide_legend (title = "Сайты"))
нога <- as.logical (c (1,0))
имена (нога) <- c ("размер", "столбец")
ppp +
geom_point (данные = T.18.pca $ li,
aes (x = Axis1,
y = Axis2,
size = Axis3,
col = T.18.pca $ li [, dim (T.18.pca $ li) [2]]), # раскраска на основе фактора группировки
show.legend = нога) +
scale_color_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
направляющие (size = guide_legend (title = "PCA 3 (18.6%) ")) +
geom_text (data = T.18.pca $ co,
aes (x = 2,5 * Comp1,
y = 2,5 * Comp2,
label = (colnames (T.18))),
размер = 2, альфа = 0,4) +
geom_mark_ellipse (data = T.18.pca $ li, aes (x = Axis1, y = Axis2,
группа = T.18.pca $ li [, dim (T.18.pca $ li) [2]],
fill = T.18.pca $ li [, dim (T.18.pca $ li) [2]]),
альфа = 0,4, развернуть = 0) +
scale_fill_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
гиды (fill = guide_legend (title = "Сайты")) ## Шкала для «цвета» уже присутствует. Добавляем еще одну шкалу для «цвета»,
##, который заменит существующий масштаб. 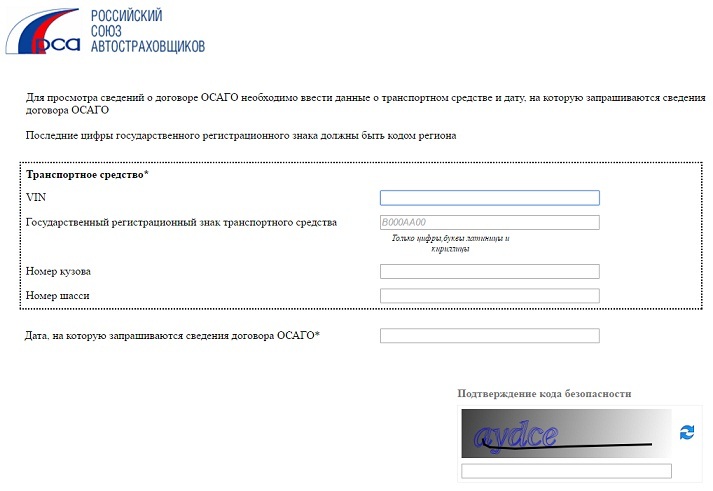 Добавляем еще одну шкалу для «цвета»,
##, который заменит существующий масштаб.
Добавляем еще одну шкалу для «цвета»,
##, который заменит существующий масштаб. ## Предупреждение в grid.Call (C_stringMetric, as.graphicsAnnot (x $ label)): семейство шрифтов не
## найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_stringMetric, as.graphicsAnnot (x $ label)): семейство шрифтов не
## найдено в базе данных шрифтов Windows ## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows ## Предупреждение в сетке.Вызов (C_stringMetric, as.graphicsAnnot (x $ label)): семейство шрифтов не
## найдено в базе данных шрифтов Windows ## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid. Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows  Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows
Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows ## Предупреждение в grid. Call.graphics (C_text, as.graphicsAnnot (x $ label), x $ x, x $ y,:
## семейство шрифтов не найдено в базе данных шрифтов Windows  Call.graphics (C_text, as.graphicsAnnot (x $ label), x $ x, x $ y,:
## семейство шрифтов не найдено в базе данных шрифтов Windows
Call.graphics (C_text, as.graphicsAnnot (x $ label), x $ x, x $ y,:
## семейство шрифтов не найдено в базе данных шрифтов Windows ## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows myscree (T.18.pca $ eig / sum (T.18.pca $ eig)) # с помощью этой функции можно размещать метки где угодно на графике, но она не остается относительной при изменении размера устройства печати
#сетка. text (label = "text", x = 0.83, y = 0.75, rot = 270, gp = gpar (fontsize = 8, col = "black"))  text (label = "text", x = 0.83, y = 0.75, rot = 270, gp = gpar (fontsize = 8, col = "black"))
text (label = "text", x = 0.83, y = 0.75, rot = 270, gp = gpar (fontsize = 8, col = "black")) Построение графика с использованием функции geom_encircle () в пакете ggalt
чел. +
geom_point (данные = T.18.pca $ li,
aes (x = Axis1,
y = Axis2,
size = Axis3,
col = T.18.pca $ li [, dim (T.18.pca $ li) [2]]),
show.legend = нога) +
направляющие (size = guide_legend (title = "PCA 3 (18.6%) ")) +
geom_text (data = T.18.pca $ co,
aes (x = 2,5 * Comp1,
y = 2,5 * Comp2,
label = (colnames (T.18))),
размер = 2, альфа = 0,4) +
geom_encircle (data = T.18.pca $ li, aes (x = Axis1, y = Axis2,
группа = T.18.pca $ li [, dim (T.18.pca $ li) [2]],
fill = T.18.pca $ li [, dim (T.18.pca $ li) [2]]),
альфа = 0,4, развернуть = 0) +
scale_fill_viridis (дискретный = ИСТИНА, направляющий = ЛОЖЬ) +
гиды (fill = guide_legend (title = "Сайты")) ## Предупреждение в сетке. Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid. Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows  Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.
Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid. Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows
Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows ## Предупреждение в grid.Call.graphics (C_text, as.graphicsAnnot (x $ label), x $ x, x $ y,:
## семейство шрифтов не найдено в базе данных шрифтов Windows ## Предупреждение в сетке.Вызов (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as. graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows  graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows
graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
Семейство ## не найдено в базе данных шрифтов Windows
## Предупреждение в grid.Call (C_textBounds, as.graphicsAnnot (x $ label), x $ x, x $ y,: font
## семейство не найдено в базе данных шрифтов Windows myscree (Т.18.pca $ eig / sum (T.18.pca $ eig)) Прогнозирование с использованием PCA
В этом разделе мы покажем, как предсказать координаты дополнительных индивидов и переменных, используя только информацию, предоставленную ранее выполненным PCA.
см. Здесь
Технические вопросы и ответы | Порше Клуб Америки
23.02.2021
944 (1986 - 1991) | Колеса и шины 1991 944 S2 144 000 Колеса и шины Колеса и шины Хантсвилл, Алабама Я заинтересован в переходе на 17-дюймовые диски Turbo Twist.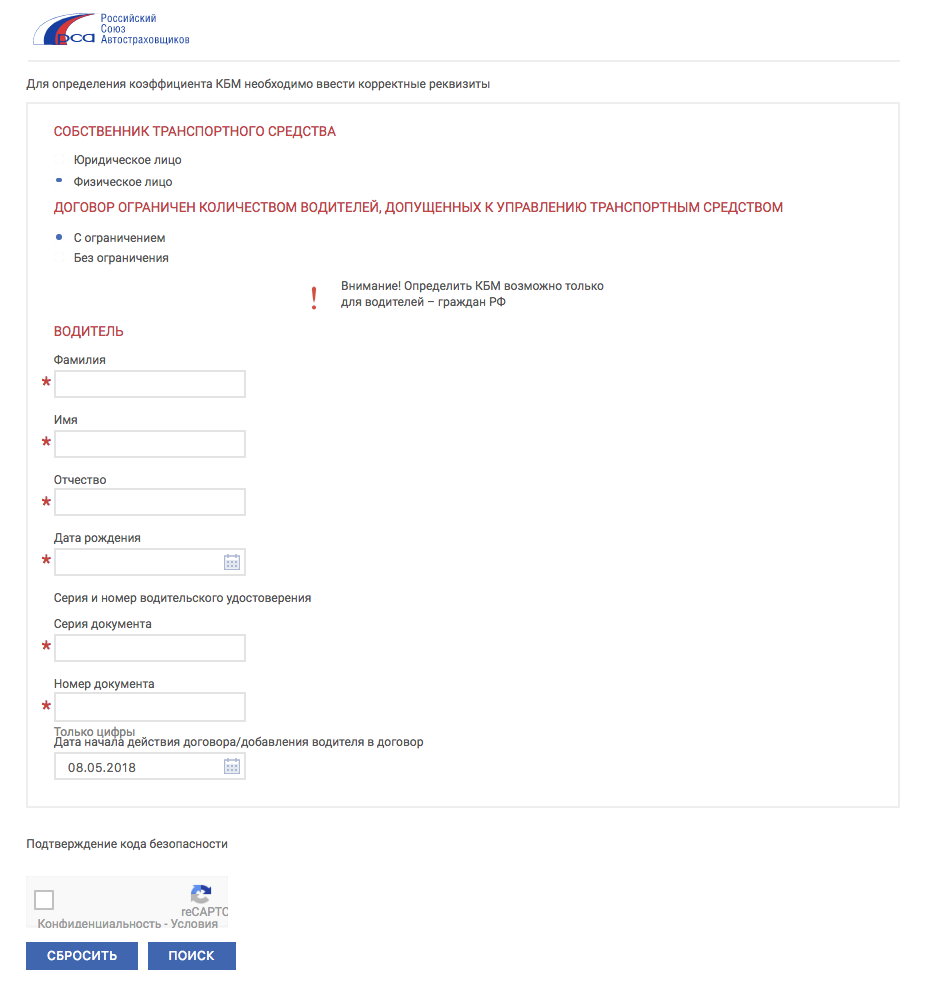 ..смещение, спереди 17x7,5 ET 23 ... сзади 17x9 дюймов. ET 15 .... Мне нравится ...
..смещение, спереди 17x7,5 ET 23 ... сзади 17x9 дюймов. ET 15 .... Мне нравится ...
22.02.2021
911 (1965 - 1973) | Двигатель1968 911 51 000 Двигатель Spotsylvania Вирджиния Привет, я пытаюсь выяснить, что случилось с моим двигателем. На нем нет серийного номера или номера сборки. У меня есть Hardex, в котором указано ...
19.02.2021
944 (1986 - 1991) | Интерьер1987 944 18 600 Интерьер Ливан Теннесси Мне любопытно узнать, насколько редким может быть этот полностью кожаный вариант в моем 944 1987 года, и может ли это сыграть роль.Коды опций: 981/983 ...
.18.02.2021
Кайман | Электрооборудование и электроника 2008 Cayman S 75 000 Электрическое и электронное оборудование San Miguel, Калифорния. После того, как я не водил свой Cayman S в течение нескольких недель, я обнаружил, что аккумулятор полностью разряжен. Пытался получить доступ к фронку по ...
Пытался получить доступ к фронку по ...
18.02.2021
911 (1984–1989) | Кузов и Интерьер1984 911 Carrera Targa 100 000 Кузов и интерьер LosAngels California Собираюсь покрасить автомобиль - пытаюсь найти прокладки вокруг автомобиля, которые нужно заменить, например, резиновые молдинги вокруг оконных дуг targa...
16.02.2021
911 (1978 - 1983) | Другой1983 911 SC 110 000 Другое Арлингтон Вирджиния Люк в крыше не открывается, хотя мотор работает. Выберите оценку Оценка 1/5 Оценка 2/5 Оценка 3/5 Оценка 4/5 Оценка 5/5 Пока голосов нет
16.02.2021
911 (1978 - 1983) | Интерьер1981 911 SC 62 432 Интерьер Оклахома-Сити Оклахома У меня есть оригинальная наклейка на окно, на которой указан цвет моего кузова и что у автомобиля особый кожаный салон, но я не могу найти подходящего...
16.02. 2021
2021
2002 911 Carrera 4S 90 000 Тросы и органы управления Meadow Vista California Ищете ручку (только) для переключателя регулировки сиденья со стороны водителя, которая электрически управляет сиденьем ...
13.02.2021
Кайман | Двигатель2018 718 Cayman S 38 000 Двигатель Malibu CA California В состоянии покоя двигатель останавливается.Когда я нажимаю педаль газа, он просыпается. Это нормально. Это подержанная машина, которую я только что купил, и я ...
13.02.2021
911 (1978 - 1983) | Другой1979 911 SC Targa 115 000 Другой город Пичтри Джорджия 911 1979 SC Targa- 115 000 миль В гараже Я владел машиной 8-9 лет, и с тех пор, как я ее купил, у нее была эта проблема. Оригинал ...
.