
Номерограм — проверка авто по гос номеру for PC / Mac / Windows 7.8.10 — Free Download
Developed By: Дром
License: FREE
Rating: 4.3/5 — 47,775 votes
Last Updated: November 26, 2021
App Details
| Version | 2.29.1 |
| Size | 11M |
| Release Date | November 26, 2021 |
| Category | Auto & Vehicles Apps |
What’s New: | |
Description: | |
Permissions: | |
Looking for a way to Download Номерограм — проверка авто по гос номеру for Windows 10/8/7 PC? You are in the correct place then.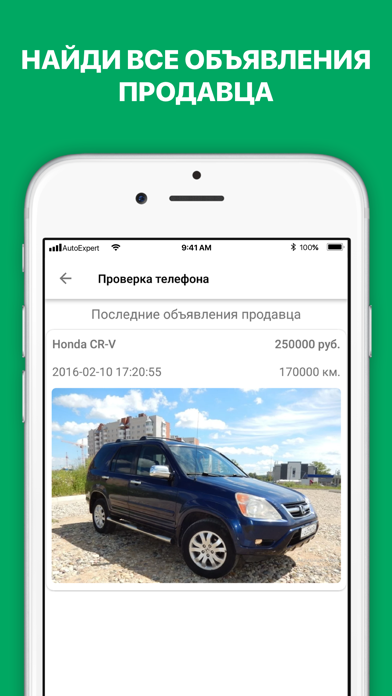
Most of the apps available on Google play store or iOS Appstore are made exclusively for mobile platforms. But do you know you can still use any of your favorite Android or iOS apps on your laptop even if the official version for PC platform not available? Yes, they do exits a few simple tricks you can use to install Android apps on Windows machine and use them as you use on Android smartphones.
Here in this article, we will list down different ways to Download Номерограм — проверка авто по гос номеру on PC
Номерограм — проверка авто по гос номеру for PC – Technical Specifications
| Name | Номерограм — проверка авто по гос номеру |
| Installations | 5,000,000+ |
| Developed By | Дром |
Номерограм — проверка авто по гос номеру is on the top of the list of Auto & Vehicles category apps on Google Playstore. It has got really good rating points and reviews. Currently, Номерограм — проверка авто по гос номеру for Windows
It has got really good rating points and reviews. Currently, Номерограм — проверка авто по гос номеру for Windows
Номерограм — проверка авто по гос номеру Download for PC Windows 10/8/7 Laptop:
Most of the apps these days are developed only for the mobile platform. Games and apps like PUBG, Subway surfers, Snapseed, Beauty Plus, etc. are available for Android and iOS platforms only. But Android emulators allow us to use all these apps on PC as well.
So even if the official version of Номерограм — проверка авто по гос номеру for PC not available, you can still use it with the help of Emulators. Here in this article, we are gonna present to you two of the popular Android emulators to use
Bluestacks is one of the coolest and widely used Emulator to run Android applications on your Windows PC. Bluestacks software is even available for Mac OS as well. We are going to use Bluestacks in this method to Download and Install Номерограм — проверка авто по гос номеру for PC Windows 10/8/7 Laptop. Let’s start our step by step installation guide.
Bluestacks software is even available for Mac OS as well. We are going to use Bluestacks in this method to Download and Install Номерограм — проверка авто по гос номеру for PC Windows 10/8/7 Laptop. Let’s start our step by step installation guide.
- Step 1: Download the Bluestacks software from the below link, if you haven’t installed it earlier –
- Step 2: Installation procedure is quite simple and straight-forward. After successful installation, open Bluestacks emulator.
- Step 3: It may take some time to load the Bluestacks app initially. Once it is opened, you should be able to see the Home screen of Bluestacks.
- Step 4: Google play store comes pre-installed in Bluestacks. On the home screen, find Playstore and double click on the icon to open it.
- Step 5: Now search for the App you want to install on your PC.
 In our case search for Номерограм — проверка авто по гос номеру
In our case search for Номерограм — проверка авто по гос номеру - Step 6: Once you click on the Install button, Номерограм — проверка авто по гос номеру will be installed automatically on Bluestacks. You can find the App under list of installed apps in Bluestacks.
 In our case search for Номерограм — проверка авто по гос номеру
In our case search for Номерограм — проверка авто по гос номеруNow you can just double click on the App icon in bluestacks and start using Номерограм — проверка авто по гос номеру App on your laptop. You can use the App the same way you use it on your Android or iOS smartphones.
If you have an APK file, then there is an option in Bluestacks to Import APK file. You don’t need to go to Google Playstore and install the game. However, using the standard method to Install any android applications is recommended.
 You need to have a minimum configuration PC to use Bluestacks. Otherwise, you may face loading issues while playing high-end games like PUBGНомерограм — проверка авто по гос номеру Download for PC Windows 10/8/7 – Method 2:
You need to have a minimum configuration PC to use Bluestacks. Otherwise, you may face loading issues while playing high-end games like PUBGНомерограм — проверка авто по гос номеру Download for PC Windows 10/8/7 – Method 2:Yet another popular Android emulator which is gaining a lot of attention in recent times is MEmu play. It is super flexible, fast and exclusively designed for gaming purposes. Now we will see how to Download Номерограм — проверка авто по гос номеру for PC Windows 10
- Step 1: Download and Install MemuPlay on your PC. Here is the Download link for you – Memu Play Website. Open the official website and download the software.
- Step 2: Once the emulator is installed, just open it and find Google Playstore App icon on the home screen of Memuplay. Just double tap on that to open.
- Step 3: Now search for Номерограм — проверка авто по гос номеру App on Google playstore.
- Step 4: Upon successful installation, you can find Номерограм — проверка авто по гос номеру on the home screen of MEmu Play.

MemuPlay is simple and easy to use application. It is very lightweight compared to Bluestacks. As it is designed for Gaming purposes, you can play high-end games like PUBG, Mini Militia, Temple Run, etc.
Номерограм — проверка авто по гос номеру for PC – Conclusion:
Номерограм — проверка авто по гос номеру has got enormous popularity with it’s simple yet effective interface. We have listed down two of the best methods to Install Номерограм — проверка авто по гос номеру on PC Windows laptop
We are concluding this article on Номерограм — проверка авто по гос номеру Download for PC with this. If you have any queries or facing any issues while installing Emulators or Номерограм — проверка авто по гос номеру for Windows, do let us know through comments. We will be glad to help you out!
If you have any queries or facing any issues while installing Emulators or Номерограм — проверка авто по гос номеру for Windows, do let us know through comments. We will be glad to help you out!
Вы просили добавить тёмную тему, мы сделали!
Теперь смотреть историю авто можно даже ночью. Тёмная тема включается на экране «Мои фото».
- Camera take pictures and videos.
- Device & app history retrieve running apps.
- Wi-Fi connection information view Wi-Fi connections.
- Location approximate location (network-based).
- Photos/Media/Files modify or delete the contents of your USB storage.
- Storage modify or delete the contents of your USB storage.
- Other control vibration.
- Uncategorized receive data from Internet.
This app has access to:
precise location (GPS and network-based).
read the contents of your USB storage.

read the contents of your USB storage.
full network access.
prevent device from sleeping.
run at startup.
view network connections.
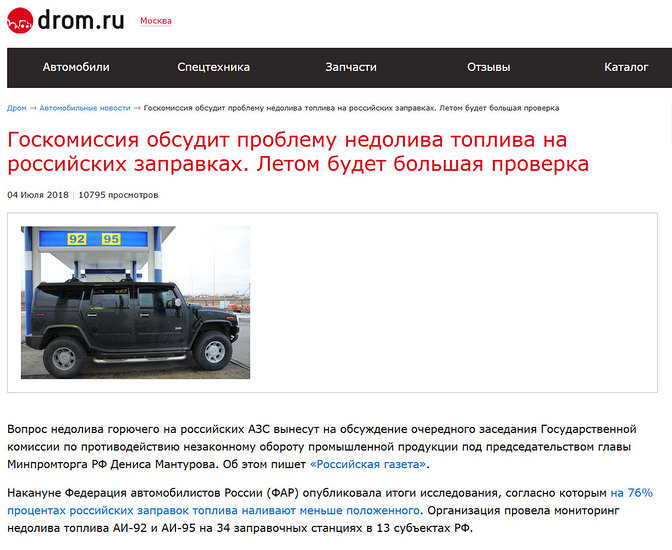
Приложение «Номерограм» позволяет найти историю продаж и отдельные фото машины в Интернете по гос номеру. Пробить по гос номеру авто у нас можно бесплатно. Номерограмм дополняет информацию, когда идет проверка автомобиля по VIN-коду, на ограничения, на арест и по гос номеру на ДТП.
Установите приложение. Введите в поиск гос номер, и мы найдём вам историю продажи машины или отдельные её фото из Интернета. Покажем даты размещения объявления, цену и пробег.
Если автомобиль размещался на avito (авито), auto ru (autoru, автору), Дром ру (Drom ru) и т. д. (am.ru, бибика.ру bibika.ru, карпрайс carprice, Юла, автокод avtocod avtokod, автотека, Штрафы ГИБДД РФ и ПДД 2019, антиперекуп, автокомпромат), мы найдём его фотографии и покажем пробег, который указал продавец в объявлении. Наша база непрерывно пополняется и уже содержит гос номера 25’000’000 машин по всем регионам России.
д. (am.ru, бибика.ру bibika.ru, карпрайс carprice, Юла, автокод avtocod avtokod, автотека, Штрафы ГИБДД РФ и ПДД 2019, антиперекуп, автокомпромат), мы найдём его фотографии и покажем пробег, который указал продавец в объявлении. Наша база непрерывно пополняется и уже содержит гос номера 25’000’000 машин по всем регионам России.
Фотографии в «Номерограм» приходят не только с досок обьявлений, но и от людей (можно добавить фото машины с гос номером через приложение), социальных сетей и других сайтов. Всё из открытых источников.
«Номерограм» найдёт для вас по гос номеру:
Номерограм – проверка авто по вин коду и госномеру by Дром — more detailed information than App Store & Google Play by AppGrooves — Auto & Vehicles
2.28.0 October 12, 2021
Напоминаем, что в Номерограме можно не только смотреть фотографии авто по госномеру, но и самим их загружать. Чем больше фотографий вы загружаете, тем большему количеству людей вы поможете узнать историю авто.
Чем больше фотографий вы загружаете, тем большему количеству людей вы поможете узнать историю авто.
А мы, тем временем, исследуем новые источники получения фото.
2.27.0 September 6, 2021
Мы много работали и сделали возможность узнать марку, модель, год и технические характеристики почти любого авто.
Если вы вводите госномер и видите только фото без данных, нажмите на кнопку «Запросить данные» и мы узнаем для вас больше информации об авто.
2.26.0 August 9, 2021
Проверяете авто перед покупкой или смотрите информацию по интересному авто? Специально для вас появилась возможность узнать среднюю цену авто по госномеру.
Заходите в Номерограм, вводите госномер и смотрите не только фотографии и технические данные, но и среднюю цену.
2.25.0 June 21, 2021
Мы готовим большое обновление функционала. Тестируем технические штуки
2.24.0 May 25, 2021
Исправление багов и повышение стабильности приложения
2.23.0 May 5, 2021
Мы значительно улучшили функционал загрузки фотографий. Загружать фотографии стало быстрее и удобнее.
2.22.0 March 18, 2021
Мы добавили возможность сообщить о несоответствии фото с реальным авто.
Также исправили ошибку с переворотом фото при загрузке.
2. 21.0 February 19, 2021
21.0 February 19, 2021
Мы добавили пуш-уведомления о завершении генерации отчета об авто. Теперь отчеты не потеряются.
А также сделали возможность загружать до 30 фото за раз.
2.20.0 January 20, 2021
Теперь не нужно копировать ссылки на объявления и открывать их в отдельном браузере.
Мы сделали возможность переходить по ссылкам одним нажатием.
2.19.0 December 28, 2020
Теперь в Номерограме ещё больше фотографий, госномеров и другой полезной информации.
2.18.0 November 26, 2020
Теперь в Номерограме ещё больше фотографий, госномеров и другой полезной информации.
2.17.0 November 11, 2020
Теперь в Номерограме ещё больше фотографий, госномеров и другой полезной информации.
2.16.1 September 3, 2020
Теперь в Номерограме ещё больше фотографий, госномеров и другой полезной информации.
2.15.0 July 29, 2020
Теперь в Номерограме ещё больше фотографий, госномеров и другой полезной информации.
2.14.1 July 24, 2020
Теперь в Номерограме ещё больше фотографий, госномеров и другой полезной информации.
2. 13.0 July 3, 2020
13.0 July 3, 2020
Не только машинам нужно проводить техосмотр. Мы заглянули под капот и кое-что подшаманили в Номерограме. Стало работать лучше.
Доработали камеру, добавили возможность оставлять описание при добавлении фотографии.
2.12.1 May 20, 2020
Не только машинам нужно проводить техосмотр. Мы заглянули под капот и кое-что подшаманили в Номерограме. Стало работать лучше.
Доработали камеру, добавили возможность оставлять описание при добавлении фотографии.
2.12.0 May 6, 2020
Не только машинам нужно проводить техосмотр. Мы заглянули под капот и кое-что подшаманили в Номерограме. Стало работать лучше.
Доработали камеру, добавили возможность оставлять описание при добавлении фотографии.
2.11.1 January 20, 2020
Не только машинам нужно проводить техосмотр. Мы заглянули под капот и кое-что подшаманили в Номерограме. Стало работать лучше.
Доработали камеру, добавили возможность оставлять описание при добавлении фотографии.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.4.0 June 10, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.1 July 2, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.4.0 June 10, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.5.0 June 27, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.4.0 June 10, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.3.0 April 22, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1 December 5, 2021
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.3.0 April 22, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.2.0 April 4, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.3.0 April 22, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.2.0 April 4, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.1.0 March 17, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.2.0 April 4, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
2.1.0 March 17, 2019
Добавили удобную галерею для просмотра фотографий в результатах поиска.
1.9.0 December 26, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
2.0.0 February 11, 2019
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.9.0 December 26, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
2.0.0 February 11, 2019
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.9.0 December 26, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
2.0.0 February 11, 2019
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.9.0 December 26, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
2.0.0 February 11, 2019
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.9.0 December 26, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
2.0.0 February 11, 2019
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.9.0 December 26, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.8.0 December 13, 2018
Прокачали Номерограм, добавив к фотографиям описание из объявлений.
1.7.0 November 28, 2018
Собрали все твои фотки на отдельной вкладке.
1.6.1 November 2, 2018
Теперь вы можете загружать несколько фотографий автомобилей за один раз.
1.7.0 November 28, 2018
Собрали все твои фотки на отдельной вкладке.
1.6.1 November 2, 2018
Теперь вы можете загружать несколько фотографий автомобилей за один раз.
1.6 October 5, 2018
Теперь вы можете загружать несколько фотографий автомобилей за один раз.
1.6.1 November 2, 2018
Теперь вы можете загружать несколько фотографий автомобилей за один раз.
Номерограм – проверка авто по вин коду и госномеру 2.26.0 Apk Download
A little about the app Номерограм – проверка авто по вин коду и госномеру
Проверять гос номер авто важно перед покупкой машины, потому что проверка авто по VIN (по ВИН) коду и базам ГИБДД РФ не всегда раскрывает всю историю авто.
Приложение «Номерограм» позволяет найти историю продаж и отдельные фото машины в Интернете по гос номеру. Пробить по гос номеру авто у нас можно бесплатно. Номерограмм дополняет информацию, когда идет проверка автомобиля по VIN-коду, на ограничения, на арест и по гос номеру на ДТП.
Установите приложение. Введите в поиск гос номер, и мы найдём вам историю продажи машины или отдельные её фото из Интернета. Покажем даты размещения объявления, цену и пробег.
Если автомобиль размещался на avito (авито), auto ru (autoru, автору), Дром ру (Drom ru) и т.д. (am.ru, бибика.ру bibika.ru, карпрайс carprice, Юла, автокод avtocod avtokod, автотека, Штрафы ГИБДД РФ и ПДД 2019, антиперекуп, автокомпромат), мы найдём его фотографии и покажем пробег, который указал продавец в объявлении. Наша база непрерывно пополняется и уже содержит гос номера 25’000’000 машин по всем регионам России.
Фотографии в «Номерограм» приходят не только с досок обьявлений, но и от людей (можно добавить фото машины с гос номером через приложение), социальных сетей и других сайтов. Всё из открытых источников.
Всё из открытых источников.
«Номерограм» найдёт для вас по гос номеру:
📌Цена машины, и сколько раз она выставлялась
📌Пробег авто, и его динамику по обьявлениям
📌Города продажи
📌Фото ДТП и ремонтов
📌Работала ли машина в такси
Несколько показательных примеров:
Скрутил 100 000 километров пробега — А 774 СО 716
Жёсткое ДТП, машину восстановили — А 714 НТ 38
Была в ДТП и работала в такси — Т 146 УС 56
Бесславный конец японской гонки — О 461 ЕА 125
И это не всё!
Мы хотим сделать мир лучше и помочь покупателям подержанных машин пробить авто по гос номеру. Всё-таки приятно подстраховать себя перед покупкой, а не играть в лотерею. Для этого «Номерограм» и сделан.
Добавляйте фото машин с гос номерами в «Номерограм». Помогайте купить авто с чистой историей. 🚗
download Номерограм — проверка авто по гос номеру android apk free
Проверять гос номер авто важно перед покупкой машины, потому что проверка авто по VIN (по ВИН) коду и базам ГИБДД РФ не всегда раскрывает всю историю авто.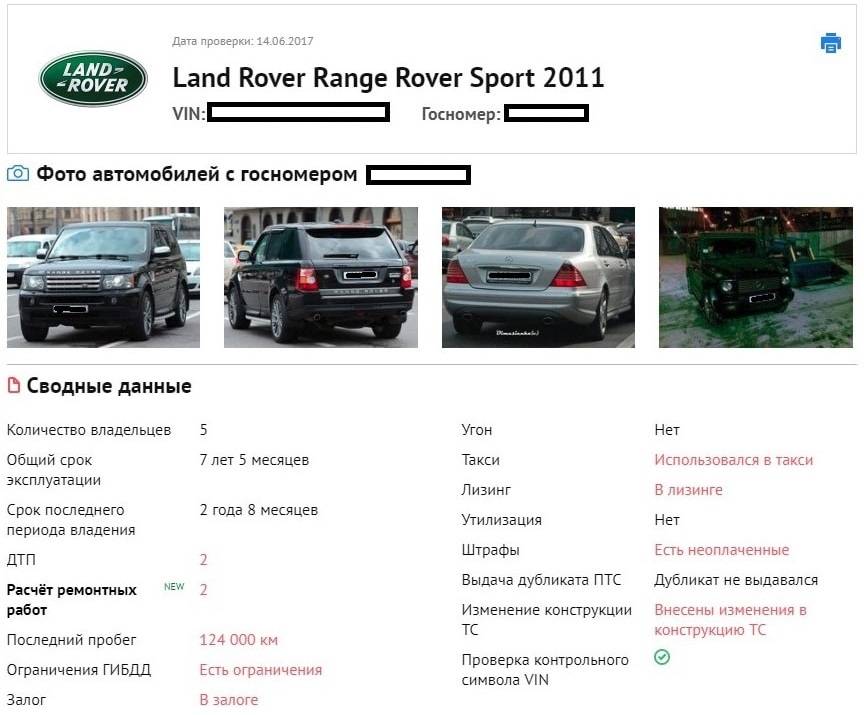 Приложение «Номерограм» позволяет найти историю продаж и отдельные фото машины в Интернете по гос номеру. Пробить по гос номеру авто у нас можно бесплатно. Номерограмм дополняет информацию, когда идет проверка автомобиля по VIN-коду, на ограничения, на арест и по гос номеру на ДТП.
Установите приложение. Введите в поиск гос номер, и мы найдём вам историю продажи машины или отдельные её фото из Интернета. Покажем даты размещения объявления, цену и пробег.
Если автомобиль размещался на avito (авито), auto ru (autoru, автору), Дром ру (Drom ru) и т.д. (am.ru, бибика.ру bibika.ru, карпрайс carprice, Юла, автокод avtocod avtokod, автотека, Штрафы ГИБДД РФ и ПДД 2019, антиперекуп, автокомпромат), мы найдём его фотографии и покажем пробег, который указал продавец в объявлении. Наша база непрерывно пополняется и уже содержит гос номера 25’000’000 машин по всем регионам России.
Фотографии в «Номерограм» приходят не только с досок обьявлений, но и от людей (можно добавить фото машины с гос номером через приложение), социальных сетей и других сайтов.
Приложение «Номерограм» позволяет найти историю продаж и отдельные фото машины в Интернете по гос номеру. Пробить по гос номеру авто у нас можно бесплатно. Номерограмм дополняет информацию, когда идет проверка автомобиля по VIN-коду, на ограничения, на арест и по гос номеру на ДТП.
Установите приложение. Введите в поиск гос номер, и мы найдём вам историю продажи машины или отдельные её фото из Интернета. Покажем даты размещения объявления, цену и пробег.
Если автомобиль размещался на avito (авито), auto ru (autoru, автору), Дром ру (Drom ru) и т.д. (am.ru, бибика.ру bibika.ru, карпрайс carprice, Юла, автокод avtocod avtokod, автотека, Штрафы ГИБДД РФ и ПДД 2019, антиперекуп, автокомпромат), мы найдём его фотографии и покажем пробег, который указал продавец в объявлении. Наша база непрерывно пополняется и уже содержит гос номера 25’000’000 машин по всем регионам России.
Фотографии в «Номерограм» приходят не только с досок обьявлений, но и от людей (можно добавить фото машины с гос номером через приложение), социальных сетей и других сайтов.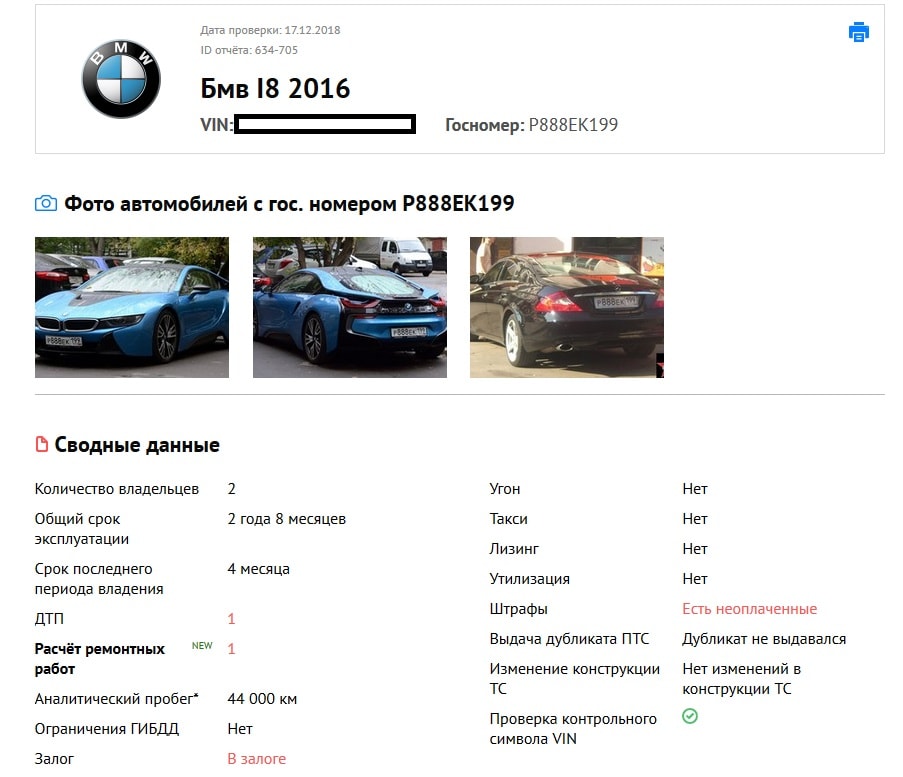 Всё из открытых источников.
«Номерограм» найдёт для вас по гос номеру:
📌Цена машины, и сколько раз она выставлялась
📌Пробег авто, и его динамику по обьявлениям
📌Города продажи
📌Фото ДТП и ремонтов
📌Работала ли машина в такси
Несколько показательных примеров:
Скрутил 100 000 километров пробега — А 774 СО 716
Жёсткое ДТП, машину восстановили — А 714 НТ 38
Была в ДТП и работала в такси — Т 146 УС 56
Бесславный конец японской гонки — О 461 ЕА 125
И это не всё!
Мы хотим сделать мир лучше и помочь покупателям подержанных машин пробить авто по гос номеру. Всё-таки приятно подстраховать себя перед покупкой, а не играть в лотерею. Для этого «Номерограм» и сделан.
Добавляйте фото машин с гос номерами в «Номерограм». Помогайте купить авто с чистой историей. 🚗
Es importante verificar el número de estado de un automóvil antes de comprarlo, ya que al verificar un automóvil mediante el código VIN (por VIN) y las bases de la policía de tránsito de la Federación Rusa no siempre se revela la historia completa del automóvil.
Всё из открытых источников.
«Номерограм» найдёт для вас по гос номеру:
📌Цена машины, и сколько раз она выставлялась
📌Пробег авто, и его динамику по обьявлениям
📌Города продажи
📌Фото ДТП и ремонтов
📌Работала ли машина в такси
Несколько показательных примеров:
Скрутил 100 000 километров пробега — А 774 СО 716
Жёсткое ДТП, машину восстановили — А 714 НТ 38
Была в ДТП и работала в такси — Т 146 УС 56
Бесславный конец японской гонки — О 461 ЕА 125
И это не всё!
Мы хотим сделать мир лучше и помочь покупателям подержанных машин пробить авто по гос номеру. Всё-таки приятно подстраховать себя перед покупкой, а не играть в лотерею. Для этого «Номерограм» и сделан.
Добавляйте фото машин с гос номерами в «Номерограм». Помогайте купить авто с чистой историей. 🚗
Es importante verificar el número de estado de un automóvil antes de comprarlo, ya que al verificar un automóvil mediante el código VIN (por VIN) y las bases de la policía de tránsito de la Federación Rusa no siempre se revela la historia completa del automóvil. La aplicación «Número de registro» le permite encontrar el historial de ventas y fotos individuales de la máquina en Internet por número de estado. Es posible perforar coches por número de estado de forma gratuita. La placa de número complementa la información cuando se verifica un automóvil con el código VIN, las restricciones de arresto y el número de estado para un accidente.
Instala la aplicación. Ingrese el número de estado en la búsqueda y le encontraremos el historial de la venta del automóvil o algunas de sus fotos de Internet. Mostramos las fechas del anuncio, precio y kilometraje.
Si el auto fue colocado en avito (avito), auto ru (autoru, autor), Drom ru (Drom ru), etc. (am.ru, bibika.ru, bibika.ru, carprice carprice, Yula, avtocod avtokod autocode, autotech, multas de la policía de tránsito y reglas de tránsito 2019, anti-hacinamiento, autocompete), encontraremos sus fotos y mostraremos el kilometraje indicado por el vendedor en el anuncio. Nuestra base se actualiza continuamente y ya contiene los números estatales de 25’000’000 automóviles en todas las regiones de Rusia.
La aplicación «Número de registro» le permite encontrar el historial de ventas y fotos individuales de la máquina en Internet por número de estado. Es posible perforar coches por número de estado de forma gratuita. La placa de número complementa la información cuando se verifica un automóvil con el código VIN, las restricciones de arresto y el número de estado para un accidente.
Instala la aplicación. Ingrese el número de estado en la búsqueda y le encontraremos el historial de la venta del automóvil o algunas de sus fotos de Internet. Mostramos las fechas del anuncio, precio y kilometraje.
Si el auto fue colocado en avito (avito), auto ru (autoru, autor), Drom ru (Drom ru), etc. (am.ru, bibika.ru, bibika.ru, carprice carprice, Yula, avtocod avtokod autocode, autotech, multas de la policía de tránsito y reglas de tránsito 2019, anti-hacinamiento, autocompete), encontraremos sus fotos y mostraremos el kilometraje indicado por el vendedor en el anuncio. Nuestra base se actualiza continuamente y ya contiene los números estatales de 25’000’000 automóviles en todas las regiones de Rusia.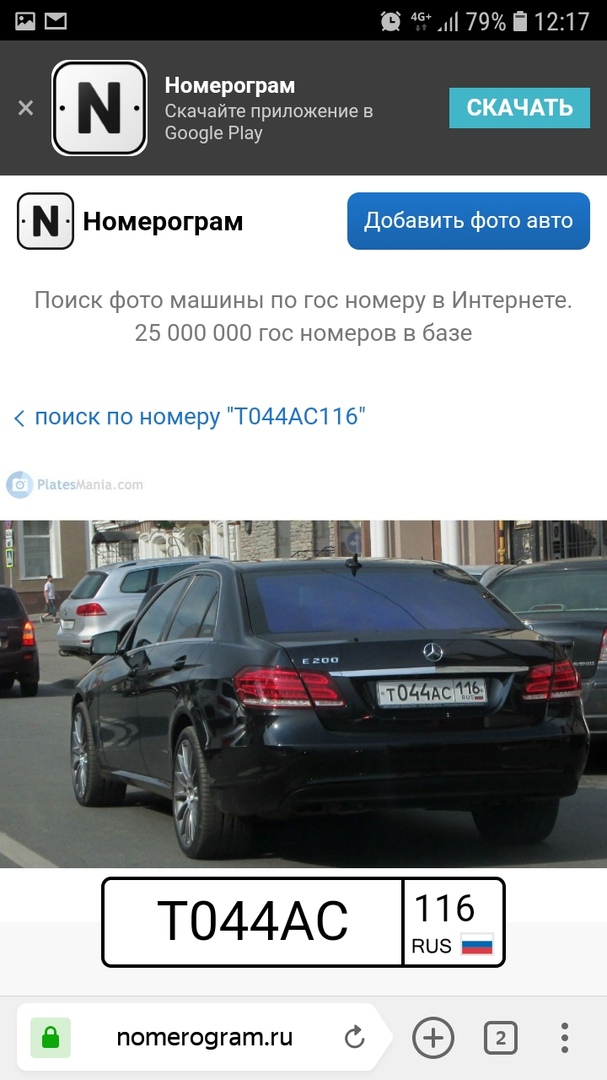 Las fotos en el «Numberogram» provienen no solo de los tableros de anuncios, sino también de personas (puede agregar fotos de autos con el número del estado a través de la aplicación), redes sociales y otros sitios. Todo a partir de fuentes abiertas.
«Número de registro» encontrará para usted por número de estado:
📌 Precio del auto y cuántas veces se ha configurado
📌 Kilometraje automático y su dinámica por anuncios
📌 Ciudades de venta
📌 Fotos del accidente y reparaciones
📌 ¿Funcionó el automóvil en un taxi?
Algunos ejemplos ilustrativos:
Torcido 100,000 kilómetros — A 774 CO 716
Duro accidente , el auto fue restaurado — A 714 NT 38
Fue en accidente y trabajó en un taxi — T 146 CSS 56
El final sin gloria de la raza japonesa — O 461 EA 125
¡Y eso no es todo!
Queremos mejorar el mundo y ayudar a los compradores de autos usados a perforar autos por número de estado. Aún así, es bueno estar seguro antes de comprar, no jugar a la lotería. Para este «nomerograma» y hecho.
Las fotos en el «Numberogram» provienen no solo de los tableros de anuncios, sino también de personas (puede agregar fotos de autos con el número del estado a través de la aplicación), redes sociales y otros sitios. Todo a partir de fuentes abiertas.
«Número de registro» encontrará para usted por número de estado:
📌 Precio del auto y cuántas veces se ha configurado
📌 Kilometraje automático y su dinámica por anuncios
📌 Ciudades de venta
📌 Fotos del accidente y reparaciones
📌 ¿Funcionó el automóvil en un taxi?
Algunos ejemplos ilustrativos:
Torcido 100,000 kilómetros — A 774 CO 716
Duro accidente , el auto fue restaurado — A 714 NT 38
Fue en accidente y trabajó en un taxi — T 146 CSS 56
El final sin gloria de la raza japonesa — O 461 EA 125
¡Y eso no es todo!
Queremos mejorar el mundo y ayudar a los compradores de autos usados a perforar autos por número de estado. Aún así, es bueno estar seguro antes de comprar, no jugar a la lotería. Para este «nomerograma» y hecho. Agregue fotos de autos con números de estado en el «Registro de números». Ayuda a comprar un auto con una historia limpia. 🚗
Agregue fotos de autos con números de estado en el «Registro de números». Ayuda a comprar un auto con una historia limpia. 🚗
Добавили удобную галерею для просмотра фотографий в результатах поиска.
4 способа определить количество ядер в вашем процессоре в Windows 10
31 января, 2019 по Admin Оставьте ответ »Как узнать, сколько физических ядер и логических ядер у вашего процессора? Необходимо проверить ядро процессора перед покупкой нового ноутбука? В этом руководстве мы покажем вам 4 простых способа определить количество физических ядер и логических ядер в вашем процессоре в Windows 10.
Физическое ядро VS.Логическое ядро
Физическое ядро - это реальное физическое ядро процессора в вашем ЦП. Каждое физическое ядро имеет свою собственную схему, а собственный кэш L1 (и обычно L2) может читать и выполнять инструкции отдельно (по большей части) от других физических ядер на кристалле. ЦП с двумя физическими ядрами называется двухъядерным процессором, а четыре физических ядра — четырехъядерным процессором.
ЦП с двумя физическими ядрами называется двухъядерным процессором, а четыре физических ядра — четырехъядерным процессором.
Логическое ядро (также известное как логические процессоры) — это скорее абстракция программирования, чем реальный физический объект.Логические ядра — это способность одного физического ядра выполнять несколько задач или потоков одновременно. Например, если у вас четырехъядерный ЦП, и каждое из его физических ядер может запускать два потока одновременно, то у вас есть 8 логических ядер.
Метод 1. Проверьте количество ядер ЦП с помощью диспетчера задач
Нажмите одновременно клавиши Ctrl + Shift + Esc, чтобы открыть диспетчер задач. Перейдите на вкладку Performance и выберите CPU в левом столбце.В правом нижнем углу вы увидите количество физических ядер и логических процессоров.
Метод 2: проверьте количество ядер ЦП с помощью команды msinfo32
Нажмите клавиши Windows + R, чтобы открыть командное окно «Выполнить», затем введите msinfo32 и нажмите Enter.
Должно открыться приложение «Информация о системе». Выберите Сводка и прокрутите вниз, пока не найдете процессор. Подробности покажут вам, сколько ядер и логических процессоров имеет ваш ЦП.
Метод 3. Проверьте количество ядер ЦП с помощью командной строки или PowerShell
Откройте командную строку или PowerShell. Введите следующую команду и нажмите Enter:
ЦП WMIC Получить идентификатор устройства, NumberOfCores, NumberOfLogicalProcessors
Вывод команды сообщает вам, сколько ядер и сколько логических процессоров находится в каждом процессоре на вашем компьютере.
Метод 4: проверьте количество ядер ЦП с помощью стороннего программного обеспечения
Если вы хотите узнать подробную информацию о своем процессоре, попробуйте стороннее бесплатное программное обеспечение CPU-Z.После запуска приложения вы можете увидеть количество физических ядер и потоков (логических ядер) внизу.
Вот и все!
Как определить мой процессор Intel®
Существуют различные варианты получения названия и количества процессоров Intel®.
Приведенные ниже методы применимы ко всем процессорам Intel®, таким как Intel® Core ™, Intel® Xeon®, Intel® Pentium®, Intel® Celeron® и Intel Atom®.
Вариант 1: Операционная система Windows *- Нажмите клавишу Windows на клавиатуре и начните вводить Система , выберите Системная информация , которая отобразит информацию о процессоре с именем , количество и скорость процессора.
- Если клавиша Windows недоступна на клавиатуре, с помощью мыши перейдите к значку Windows, расположенному в нижнем левом углу экрана, щелкните правой кнопкой мыши и выберите Система .Найдите имя и номер процессора в информации о процессоре .
Примеры ниже показывают случай выбора Системная информация и Система .
Введите следующую команду
lscpu | grep «Название модели»
См. примеры:
MAC OSВведите следующую команду в терминальном приложении
sysctl -a | grep machdep.cpu.brand_string
См. пример:
Вариант 2: Упаковочная коробкаЕсли вы купили процессор Intel® в штучной упаковке, информацию о номере процессора вместе с другой информацией, такой как номер партии (FPO) и серийный номер (ATPO) указаны на упаковке.
Вариант 3: Маркировка процессоровНазвание и номер процессора Intel® указаны в верхней части процессора.См. Пример ниже.
Посмотрите это видео, чтобы узнать, как определить название и номер вашего процессора Intel®.
Определите поколение для ваших процессоров Intel® Core ™
Вы также можете определить поколение процессора, если ваш процессор Intel® Core ™. Поколение процессора — это первое число после i9, i7, i5 или i3.
Поколение процессора — это первое число после i9, i7, i5 или i3.
Вот несколько примеров:
- Процессор Intel® Core ™ i7- 10 710U Процессор 10-го поколения , потому что номер 10 указан после i7.
- Процессор Intel® Core ™ i9- 9 900 Процессор 9-го поколения , потому что номер 9 указан после i9.
- Процессор Intel® Core ™ i7- 9 850H Процессор 9-го поколения , потому что номер 9 указан после i7.
- Процессор Intel® Core ™ i5- 8 600 Процессор 8-го поколения , потому что номер 8 указан после i5.
- Процессор Intel® Core ™ i3- 7 350K Процессор 7-го поколения , потому что номер 7 указан после i3.
- Процессор Intel® Core ™ i5- 6 400T Процессор 6-го поколения , потому что номер 6 указан после i5.
Как проверить количество ядер в процессоре в Windows 11 или 10
В некоторых случаях вам может потребоваться проверить количество ядер в процессоре ПК, который вы используете по разным причинам. Особенно, когда вы покупаете новый ПК, может возникнуть мысль проверить спецификацию, заявленную производителем. Если вы используете Windows 10 или 11, то ОС предоставляет вам несколько простых способов узнать количество ядер.
Особенно, когда вы покупаете новый ПК, может возникнуть мысль проверить спецификацию, заявленную производителем. Если вы используете Windows 10 или 11, то ОС предоставляет вам несколько простых способов узнать количество ядер.
В эпоху модернизации, когда Intel надеется выпустить Cannon Lake, Kaby Lake и Coffee Lake в ближайшее время, пользователю намного проще позволить себе четырехъядерный компьютер. Однако у нас уже есть представление о грядущих процессорах Intel с новейшими технологиями. Пришло время узнать ядро процессора, который вы используете.
Проверка количества ядер в ЦП в Windows 11 и 10
Прежде чем мы начнем проинструктировать способы проверки количества ядер в ЦП в Windows 11 или 10, уместно собрать информацию о том же.Посмотрите, что это значит —
Что означает Core? Компьютер включает в себя ряд важных компонентов, вместе называемых Аппаратным обеспечением. Среди всех этих элементов наиболее важной частью является центральный процессор (центральный процессор). В вычислительной операции ЦП первым получает информацию для выполнения вычисления. Этот процессор содержит набор инструкций. А вот и термин «ядро». Если процессор имеет только 1 набор инструкций, мы называем его одноядерным процессором.
В вычислительной операции ЦП первым получает информацию для выполнения вычисления. Этот процессор содержит набор инструкций. А вот и термин «ядро». Если процессор имеет только 1 набор инструкций, мы называем его одноядерным процессором.
Со временем Intel внесла огромные изменения в инструкции процессора. Как мы уже говорили ранее, процессор называется в зависимости от количества инструкций. В случае двух наборов инструкций мы называем это двухъядерным процессором. Точно так же 4 набора — это четырехъядерный процессор, 6 наборов — это шестиядерный процессор, а последний — восьмиядерный, поскольку он имеет 8 наборов инструкций. К этому времени мы уже узнали о ядре. Теперь перейдем к проверке количества ядер в процессоре.
Существуют разные методы определения ядра, и давайте изучим их один за другим.
Вы можете использовать диспетчер задач или инструмент «Информация о системе», а также воспользоваться помощью Google или стороннего программного обеспечения. Здесь мы обсудим каждый метод в последовательности шагов, чтобы вы все поняли.
Способы проверки количества ядер в процессоре в Windows 10 —
Способ 1 — через системную информациюСистемная информация — это альтернативный метод, который позволяет вам проверить количество ядер в процессоре без использования какого-либо программного обеспечения. По этой причине шаги следующие:
Шаг-1: Щелкните Start Menu на вашем компьютере и в поле поиска введите системную информацию .Нажмите Введите , чтобы открыть приложение «Информация о системе». По умолчанию выбрано Сводная информация о системе .
Шаг 2: На правой панели вы можете увидеть список элементов, описывающих каждую деталь вашего ПК. Медленно спускайтесь вниз, проверяя предметы, пока не увидите в списке Processor . В любом случае, если у вас два процессора, список показывает их по отдельности. Внимательно посмотрите на Value процессора, и вы увидите количество ядер (см. Снимок экрана).
Снимок экрана).
Среди всех процедур проверки количества ядер в ЦП самым быстрым является проверка с помощью диспетчера задач . Чтобы выполнить всю задачу, выполните указанные шаги.
Шаг-1: Запустите Task Manager на вашем компьютере, и есть два способа добиться этого. Вы можете нажать сочетания клавиш CTRL + SHIFT + ESC вместе, чтобы открыть его. Вместо этого вы можете щелкнуть правой кнопкой мыши меню «Пуск» и из списка опций выбрать « Task Manager ».
Step-2: В диспетчере задач вы можете увидеть некоторые вкладки, переключитесь на вкладку Performance. Здесь вы можете увидеть некоторые графики для ЦП, памяти, Ethernet, а также для диска 0, диска 1 и т. Д. На левой боковой панели.
Шаг 3 : Щелкните график CPU , и он откроет график с дополнительной информацией на правой панели.
Step-4: Чуть ниже графика вы можете увидеть такую информацию, как базовая скорость, сокеты, ядра и так далее.Итак, найдите здесь число, например, рядом с Ядрами — на изображении ниже он отображает 2 , что означает, что ПК имеет Dual Core .
Обычно это один график, и вы также можете изменить его по своему усмотрению. Для этого нужно щелкнуть правой кнопкой мыши по графику. Вы видите несколько вариантов, наведите курсор на Измените график на и в подменю выберите « Логические процессоры ».
Вы будете рады узнать, что в Windows 11 или 10 фактически нет необходимости изменять график.Потому что он автоматически сообщает о количестве ядер, сокетов, а также логических процессоров, присутствующих в системе.
Кроме того, он также предоставляет информацию о кэшах, таких как кеши L1, L2 и L3. В некоторых случаях в ЦП компьютеров используются специальные кеши для повышения производительности обработки.
Поиск в Google также поможет вам довольно легко проверить количество ядер в процессоре, если вы знаете номер модели процессора.Если вы не знаете номер, вы можете получить его в диспетчере задач или в информации о системе (см. Методы выше).
Например, я погуглил ядро — i34005U и из различных результатов, когда вы открываете кого-либо, вы получаете спецификацию. Лист содержит каждую деталь процессора. Найдите Core , и вы увидите номер.
Способ 4 — сторонние приложенияВы также можете использовать некоторые сторонние приложения, чтобы узнать подробную информацию о вашем процессоре, и эти приложения или программы бесплатны.Помимо сведений о процессоре, приложения также информируют вас о поддержке виртуализации ЦП, SSSE3, а также о vt-x и т. Д. Они действительно эффективны и одинаково полезны для получения информации об оборудовании.
У нас есть набор из нескольких инструментов Best System Info — Узнайте о материнской плате, о процессоре компьютера здесь.
Следовательно, вышеупомянутое — это несколько простых и простых способов узнать количество ядер в вашем процессоре. Помните, что если вы собираетесь купить компьютер с несколькими процессорами, лучшим выбором будет Windows 11 или 10 Pro для рабочих станций.Правда, в продаже его пока нет. Однако, как правило, пользователю требуется два процессора одновременно.
Для получения дополнительной информации, Windows 11 или 10 достаточно компетентны для поддержки до 32 ядер для 32-разрядной Windows. Если вы выберете 64-битную версию, она сможет поддерживать до 256 ядер. Мы действительно не можем ожидать такого количества ядер в нашей жизни!
Заключение При использовании компьютера вы должны знать детали устройства, и это действительно полезно для определения производительности, а также для профессиональной работы.Знание количества ядер в процессоре является обязательным, и Windows 11 или 10 упрощает это. Фактически, мы чувствуем необходимость знать методы поиска этой информации более простыми средствами. Итак, попробуйте описанные выше методы для проверки количества ядер в процессоре, и если вам известны другие советы, напишите их нам.
Итак, попробуйте описанные выше методы для проверки количества ядер в процессоре, и если вам известны другие советы, напишите их нам.
Многоядерное машинное обучение на Python с помощью Scikit-Learn
Многие вычислительно дорогостоящие задачи машинного обучения можно сделать параллельными, разделив работу между несколькими ядрами ЦП , что называется многоядерной обработкой.
Общие задачи машинного обучения, которые можно сделать параллельными, включают обучающие модели, такие как ансамбли деревьев решений, оценку моделей с использованием процедур повторной выборки, таких как перекрестная проверка в k-кратном размере, и настройка гиперпараметров модели, таких как сетка и случайный поиск.
Использование нескольких ядер для общих задач машинного обучения может значительно сократить время выполнения в зависимости от количества ядер, доступных в вашей системе. Обычный портативный и настольный компьютер может иметь 2, 4 или 8 ядер.В более крупных серверных системах может быть доступно 32, 64 или более ядер, что позволяет решать задачи машинного обучения, которые занимают часы, за минуты.
В этом руководстве вы узнаете, как настроить scikit-learn для многоядерного машинного обучения.
После прохождения этого руководства вы будете знать:
- Как обучать модели машинного обучения с использованием нескольких ядер.
- Как сделать оценку моделей машинного обучения параллельной.
- Как использовать несколько ядер для настройки гиперпараметров модели машинного обучения.
Приступим.
Многоядерное машинное обучение на Python с помощью Scikit-Learn
Фото Э. Р. Бауэра, некоторые права защищены.
Обзор руководства
Это руководство разделено на пять частей; их:
- Многоядерный Scikit-Learn
- Обучение многоядерной модели
- Оценка многоядерной модели
- Многоядерная настройка гиперпараметров
- Рекомендации
Многоядерный Scikit-Learn
Машинное обучение может быть дорогостоящим с точки зрения вычислений.
Есть три основных центра этих вычислительных затрат; их:
- Обучающие модели машинного обучения.
- Оценка моделей машинного обучения.
- Гиперпараметрическая настройка моделей машинного обучения.

Хуже того, это касается соединения.
Например, оценка моделей машинного обучения с использованием такой техники повторной выборки, как k-кратная перекрестная проверка, требует, чтобы процесс обучения повторялся несколько раз.
- Для оценки требуется повторное обучение
Настройка гиперпараметров модели еще больше усугубляет ситуацию, поскольку требует повторения процедуры оценки для каждой комбинации проверенных гиперпараметров.
- Настройка требует повторной оценки
Большинство, если не все, современные компьютеры имеют многоядерные процессоры. Это включает в себя вашу рабочую станцию, ваш ноутбук, а также более крупные серверы.
Вы можете настроить свои модели машинного обучения на использование нескольких ядер вашего компьютера, что значительно ускорит выполнение дорогостоящих в вычислительном отношении операций.
Библиотека машинного обучения Python scikit-learn предоставляет эту возможность с помощью аргумента n_jobs для ключевых задач машинного обучения, таких как обучение модели, оценка модели и настройка гиперпараметров.
Этот аргумент конфигурации позволяет указать количество ядер, используемых для задачи. По умолчанию установлено значение «Нет», при котором будет использоваться одно ядро. Вы также можете указать количество ядер в виде целого числа, например 1 или 2. Наконец, вы можете указать -1, и в этом случае задача будет использовать все ядра, доступные в вашей системе.
- n_jobs : укажите количество ядер, которые будут использоваться для ключевых задач машинного обучения.
Общие значения:
- n_jobs = Нет : Используйте одно ядро или значение по умолчанию, настроенное вашей внутренней библиотекой.
- n_jobs = 4 : использовать указанное количество ядер, в данном случае 4.
- n_jobs = -1 : использовать все доступные ядра.

Что такое ядро?
ЦП может иметь несколько физических ядер ЦП, что по сути аналогично наличию нескольких ЦП. Каждое ядро также может иметь гиперпоточность — технологию, которая во многих случаях позволяет удвоить количество ядер.
Например, моя рабочая станция имеет четыре физических ядра, которые увеличены вдвое до восьми ядер из-за гиперпоточности.Поэтому я могу поэкспериментировать с 1-8 ядрами или указать -1, чтобы использовать все ядра на моей рабочей станции.
Теперь, когда мы знакомы с возможностями библиотеки scikit-learn по поддержке многоядерной параллельной обработки для машинного обучения, давайте рассмотрим несколько примеров.
Вы получите разные тайминги для всех примеров в этом руководстве; поделитесь своими результатами в комментариях. Вам также может потребоваться изменить количество ядер, чтобы оно соответствовало количеству ядер в вашей системе.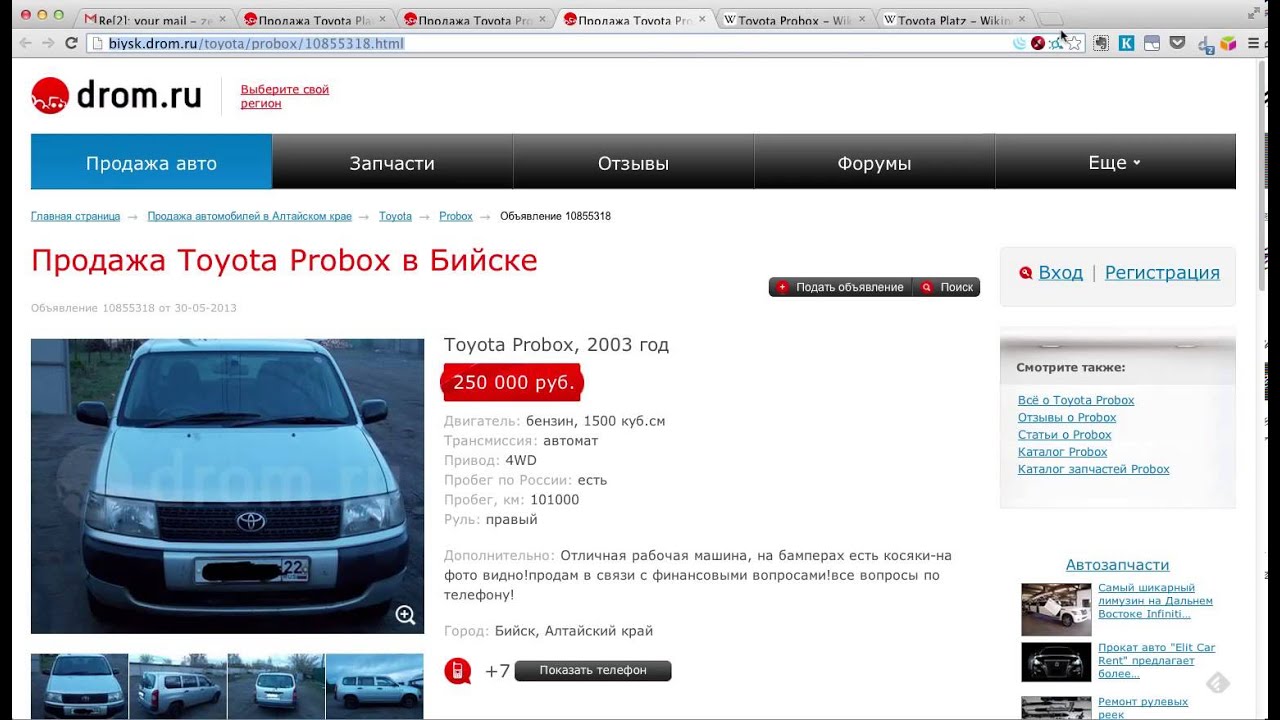
Примечание : Да, я знаю API timeit, но выбрал его для этого руководства.Мы не профилируем примеры кода как таковые; Вместо этого я хочу, чтобы вы сосредоточились на том, как и когда использовать многоядерные возможности scikit-learn и что они предлагают реальные преимущества. Я хотел, чтобы примеры кода были чистыми и простыми для чтения даже для новичков. Я установил его как расширение, чтобы обновить все примеры, чтобы использовать API timeit и получать более точные тайминги. Делитесь своими результатами в комментариях.
Обучение многоядерной модели
Многие алгоритмы машинного обучения поддерживают многоядерное обучение с помощью аргумента n_jobs при определении модели.
Это влияет не только на обучение модели, но и на использование модели при построении прогнозов.
Популярным примером является ансамбль деревьев решений, таких как пакетированные деревья решений, случайный лес и повышение градиента.
В этом разделе мы рассмотрим ускорение обучения модели RandomForestClassifier с использованием нескольких ядер. Мы будем использовать задачу синтетической классификации для наших экспериментов.
Мы будем использовать задачу синтетической классификации для наших экспериментов.
В этом случае мы определим случайную модель леса с 500 деревьями и будем использовать одно ядро для обучения модели.
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 1)
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 1) |
Мы можем записать время до и после вызова функции train () , используя функцию time () . Затем мы можем вычесть время начала из времени окончания и указать время выполнения в секундах.
Полный пример оценки времени выполнения обучения модели случайного леса с одним ядром приведен ниже.
# пример тайминга обучения модели случайного леса на одном ядре
от времени импорта времени
из sklearn.datasets импортировать make_classification
из sklearn.ensemble импортировать RandomForestClassifier
# определить набор данных
X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3)
# определить модель
model = RandomForestClassifier (n_estimators = 500, n_jobs = 1)
# записать текущее время
начало = время ()
# соответствовать модели
модель. подходят (X, y)
# записать текущее время
конец = время ()
# время выполнения отчета
результат = конец — начало
print (‘%. 3f seconds’% результат)
подходят (X, y)
# записать текущее время
конец = время ()
# время выполнения отчета
результат = конец — начало
print (‘%. 3f seconds’% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # пример синхронизации обучения модели случайного леса на одном ядре из времени импорта из sklearn.наборы данных import make_classification from sklearn.ensemble import RandomForestClassifier # define dataset X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state ) # определить модель 9000 = 3) model = RandomForestClassifier (n_estimators = 500, n_jobs = 1) # текущее время записи start = time () # соответствует модели model.fit (X, y) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%. |
 3f секунд ‘% результат)
3f секунд ‘% результат)При выполнении примера отображается время, затраченное на обучение модели с одним ядром.
В данном случае мы видим, что это занимает около 10 секунд.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Теперь мы можем изменить пример, чтобы использовать все физические ядра в системе, в данном случае четыре.
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 4)
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 4) |
Полный пример многоядерного обучения модели с четырьмя ядрами приведен ниже.
# пример тайминга обучения случайной модели леса на 4 ядрах
от времени импорта времени
из sklearn.datasets импортировать make_classification
из sklearn.ensemble импортировать RandomForestClassifier
# определить набор данных
X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3)
# определить модель
model = RandomForestClassifier (n_estimators = 500, n_jobs = 4)
# записать текущее время
начало = время ()
# соответствовать модели
модель. подходят (X, y)
# записать текущее время
конец = время ()
# время выполнения отчета
результат = конец — начало
print (‘%. 3f seconds’% результат)
подходят (X, y)
# записать текущее время
конец = время ()
# время выполнения отчета
результат = конец — начало
print (‘%. 3f seconds’% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # пример синхронизации обучения модели случайного леса на 4 ядрах из времени импорта из sklearn.наборы данных import make_classification from sklearn.ensemble import RandomForestClassifier # define dataset X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state ) # определить модель 9000 = 3) model = RandomForestClassifier (n_estimators = 500, n_jobs = 4) # текущее время записи start = time () # соответствует модели model.fit (X, y) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%. |
 3f секунд ‘% результат)
3f секунд ‘% результат)При выполнении примера отображается время, затраченное на обучение модели с одним ядром.
В этом случае мы видим, что скорость выполнения упала более чем вдвое и составила примерно 3,151 секунды.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Теперь мы можем изменить количество ядер на восемь, чтобы учесть гиперпоточность, поддерживаемую четырьмя физическими ядрами.
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 8)
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 8) |
Мы можем добиться того же эффекта, установив для n_jobs значение -1, чтобы автоматически использовать все ядра; например:
… # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = -1)
. # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = -1) |
 ..
..Пока что мы будем указывать количество ядер вручную.
Полный пример многоядерного обучения модели с восемью ядрами приведен ниже.
# пример тайминга обучения модели случайного леса на 8 ядрах от времени импорта времени из sklearn.datasets импортировать make_classification из склеарна.импорт ансамбля RandomForestClassifier # определить набор данных X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = 8) # записать текущее время начало = время () # соответствовать модели model.fit (X, y) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало print (‘%. 3f seconds’% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # пример времени обучения модели случайного леса на 8 ядрах из времени импорта из sklearn. from sklearn.ensemble import RandomForestClassifier # define dataset X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state ) # определить модель 9000 = 3) model = RandomForestClassifier (n_estimators = 500, n_jobs = 8) # текущее время записи start = time () # соответствует модели model.fit (X, y) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%.3f секунд ‘% результат) |
 наборы данных import make_classification
наборы данных import make_classificationПри выполнении примера отображается время, затраченное на обучение модели с одним ядром.
В этом случае мы видим, что мы получили еще одно снижение скорости выполнения с примерно 3,151 до примерно 2,521 при использовании всех ядер.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Мы можем сделать связь между количеством ядер, используемых во время обучения, и скоростью выполнения более конкретной, сравнив все значения от одного до восьми и построив график результата.
Полный пример приведен ниже.
# пример сравнения количества ядер, используемых во время обучения, со скоростью выполнения
от времени импорта времени
из sklearn.datasets импортировать make_classification
из sklearn.ensemble импортировать RandomForestClassifier
из matplotlib import pyplot
# определить набор данных
X, y = make_classification (n_samples = 10000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3)
результаты = список ()
# сравнить время для количества ядер
n_cores = [1, 2, 3, 4, 5, 6, 7, 8]
для n в n_cores:
# зафиксировать текущее время
начало = время ()
# определить модель
model = RandomForestClassifier (n_estimators = 500, n_jobs = n)
# соответствовать модели
модель.подходят (X, y)
# зафиксировать текущее время
конец = время ()
# хранить время выполнения
результат = конец — начало
print (‘> cores =% d:% .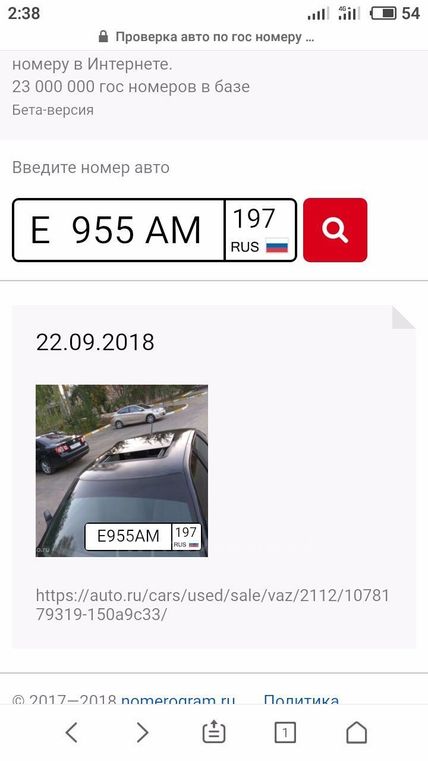 3f seconds’% (n, результат))
results.append (результат)
pyplot.plot (n_cores, результаты)
pyplot.show ()
3f seconds’% (n, результат))
results.append (результат)
pyplot.plot (n_cores, результаты)
pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 22 23 24 25 | # пример сравнения количества ядер, используемых во время обучения, со скоростью выполнения с момента импорта времени из sklearn.наборы данных import make_classification from sklearn.ensemble import RandomForestClassifier from matplotlib import pyplot # define dataset X, y = make_classification (n_samples = 10000, n_features = 20, n_n_informndant = 15) results = list () # сравнить время для количества ядер n_cores = [1, 2, 3, 4, 5, 6, 7, 8] для n в n_cores: # захватить текущее время start = time () # определить модель model = RandomForestClassifier (n_estimators = 500, n_jobs = n) # соответствует модели . # захват текущего времени end = time () # сохранить время выполнения result = end — start print (‘> cores =% d:% .3f seconds’% ( n, результат)) results.append (результат) pyplot.plot (n_cores, results) pyplot.show () |
 fit (X, y)
fit (X, y)При выполнении примера сначала отображается скорость выполнения для каждого количества ядер, использованных во время обучения.
Мы видим устойчивое снижение скорости выполнения с одного до восьми ядер, хотя значительные преимущества прекращаются после четырех физических ядер.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
> ядер = 1: 10,798 секунд > cores = 2: 5,743 секунды > cores = 3: 3,964 секунды > cores = 4: 3,158 секунды > ядер = 5: 2,868 секунды > cores = 6: 2,631 секунды > cores = 7: 2,528 секунды > cores = 8: 2,440 секунды
> ядра = 1: 10,798 секунд > ядра = 2: 5. > ядра = 3: 3,964 секунды > ядра = 4: 3,158 секунды > ядра = 5: 2,868 секунды > ядра = 6: 2,631 секунды > ядра = 7: 2,528 секунды > cores = 8: 2,440 секунды |
 743 секунды
743 секундыТакже создается график, показывающий взаимосвязь между количеством ядер, используемых во время обучения, и скоростью выполнения, показывая, что мы по-прежнему видим преимущество вплоть до восьми ядер.
Линейный график количества ядер, использованных во время обучения, по сравнению сСкорость исполнения
Теперь, когда мы знакомы с преимуществами многоядерного обучения моделей машинного обучения, давайте посмотрим на оценку многоядерных моделей.
Оценка многоядерной модели
Золотым стандартом оценки моделей является k-кратная перекрестная проверка.
Это процедура повторной выборки, которая требует, чтобы модель была обучена и оценена k раз на различных секционированных подмножествах набора данных. Результатом является оценка производительности модели при прогнозировании данных, не используемых во время обучения, которую можно использовать для сравнения и выбора хорошей или лучшей модели для набора данных.
Результатом является оценка производительности модели при прогнозировании данных, не используемых во время обучения, которую можно использовать для сравнения и выбора хорошей или лучшей модели для набора данных.
Кроме того, рекомендуется повторять этот процесс оценки несколько раз, что называется повторной k-кратной перекрестной проверкой.
Процедуру оценки можно настроить для использования нескольких ядер, где обучение и оценка каждой модели происходит на отдельном ядре. Это можно сделать, установив аргумент n_jobs при вызове функции cross_val_score (); например:
Мы можем изучить влияние нескольких ядер на оценку модели.
Во-первых, давайте оценим модель на одном ядре.
… # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 1)
… # оценить модель n_scores = cross_val_score (model, X, y, scoring = ‘precision’, cv = cv, n_jobs = 1) |
Мы будем оценивать модель случайного леса и использовать одно ядро при обучении модели (пока).
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1)
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) |
Полный пример приведен ниже.
# пример оценки модели с использованием одного ядра от времени импорта времени из sklearn.datasets импортировать make_classification из склеарна.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # записать текущее время начало = время () # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 1) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало Распечатать(‘%.3f секунд ‘% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 | # пример оценки модели с использованием одного ядра из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier #define dataset_assification # define dataset_assification 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 1) # запись текущего времени start = time () # оценка модели n_scores = cross_val_score (model, X, y, scoring = ‘precision’, cv = cv, n_jobs = 1) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%.3f секунд ‘% результат) |
При выполнении примера модель оценивается с использованием 10-кратной перекрестной проверки с тремя повторениями.
В данном случае мы видим, что оценка модели заняла около 6,412 секунды.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Мы можем обновить пример, чтобы использовать все восемь ядер системы и ожидать большого ускорения.
… # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 8)
… # оценить модель n_scores = cross_val_score (model, X, y, scoring = ‘precision’, cv = cv, n_jobs = 8) |
Полный пример приведен ниже.
# пример оценки модели с использованием 8 ядер от времени импорта времени из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из склеарна.импорт ансамбля RandomForestClassifier # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # записать текущее время начало = время () # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 8) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало Распечатать(‘%.3f секунд ‘% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 | # пример оценки модели с использованием 8 ядер из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier #define dataset_assification # define dataset_assification 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 1) # запись текущего времени start = time () # оценка модели n_scores = cross_val_score (model, X, y, scoring = ‘precision’, cv = cv, n_jobs = 8) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%.3f секунд ‘% результат) |
При выполнении примера модель оценивается с использованием нескольких ядер.
В этом случае мы видим, что время выполнения упало с 6,412 секунды до примерно 2,371 секунды, что дает долгожданное ускорение.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Как и в предыдущем разделе, мы можем задать время скорости выполнения для каждого количества ядер от одного до восьми, чтобы получить представление о взаимосвязи.
Полный пример приведен ниже.
# сравнить скорость выполнения для оценки модели с количеством ядер процессора от времени импорта времени из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier из matplotlib import pyplot # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) результаты = список () # сравнить время для количества ядер n_cores = [1, 2, 3, 4, 5, 6, 7, 8] для n в n_cores: # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # записываем текущее время начало = время () # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = n) # записываем текущее время конец = время () # хранить время выполнения результат = конец — начало print (‘> cores =% d:%.3f секунд ‘% (n, результат)) results.append (результат) pyplot.plot (n_cores, результаты) pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 22 23 24 25 26 27 28 29 | # сравнить скорость выполнения для оценки модели с количеством ядер процессора с момента импорта времени из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier из matplotlib_asemble ,из matplotlase_import 9000, import pyplot 9000 n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) results = list () # сравнить время для количества ядер n_cores = [1, 2, 3, 4, 5, 6, 7 , 8] для n в n_cores: # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n_splits = 3 , random_state = 1) # записать текущее время start = time () # оценить модель n_scores = cross_val_score (model, X, y, scoring = ‘acc uracy ‘, cv = cv, n_jobs = n) # записать текущее время end = time () # сохранить время выполнения result = end — start print (‘> cores =% d:% .3f секунд ‘% (n, результат)) results.append (результат) pyplot.plot (n_cores, results) pyplot.show () |
При запуске примера сначала отображается время выполнения в секундах для каждого количества ядер для оценки модели.
Мы видим, что по сравнению с четырьмя физическими ядрами кардинальных улучшений нет.
Мы также можем увидеть здесь разницу при тренировке с восемью ядрами из предыдущего эксперимента. В данном случае оценка производительности заняла 1.492 секунды, тогда как автономный случай занял около 2,371 секунды.
Это подчеркивает ограничение методологии оценки, которую мы используем, когда мы сообщаем о производительности одного прогона, а не повторных прогонов. Для загрузки классов в память и выполнения любой JIT-оптимизации требуется некоторое время раскрутки.
Независимо от точности нашего ненадежного профилирования, мы видим знакомое ускорение оценки модели с увеличением количества ядер, используемых в процессе.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
> ядер = 1: 6,339 секунды > cores = 2: 3,765 секунды > cores = 3: 2,404 секунды > cores = 4: 1,826 секунды > cores = 5: 1,806 секунды > cores = 6: 1,686 секунды > cores = 7: 1,587 секунды > cores = 8: 1,492 секунды
> ядра = 1: 6,339 секунды > ядра = 2: 3.765 секунд > ядер = 3: 2,404 секунды > ядер = 4: 1,826 секунды > ядер = 5: 1,806 секунды > ядер = 6: 1,686 секунды > ядер = 7: 1,587 секунды > cores = 8: 1,492 секунды |
Также создается график зависимости между количеством ядер и скоростью выполнения.
Линейный график количества ядер, использованных во время оценки, в зависимости от скорости выполнения
Мы также можем сделать процесс обучения модели параллельным во время процедуры оценки модели.
Хотя это возможно, не так ли?
Чтобы изучить этот вопрос, давайте сначала рассмотрим случай, когда при обучении модели используются все ядра, а при оценке модели используется одно ядро.
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 8) … # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 1)
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 8) … # оценить модель n_scores = cross_val_score (model, X, y, scoring = ‘precision’ , cv = cv, n_jobs = 1) |
Полный пример приведен ниже.
# пример использования нескольких ядер для обучения модели, но не оценки модели от времени импорта времени из sklearn.datasets импортировать make_classification из склеарна.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 8) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # записать текущее время начало = время () # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 1) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало Распечатать(‘%.3f секунд ‘% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 | # пример использования нескольких ядер для обучения модели, но не оценки модели из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier #define dataset_assification # define dataset_assification 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 8) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 1) # запись текущего времени start = time () # оценка модели n_scores = cross_val_score (model, X, y, scoring = ‘precision’, cv = cv, n_jobs = 1) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%.3f секунд ‘% результат) |
При выполнении примера модель оценивается с использованием одного ядра, но каждая обученная модель использует одно ядро.
В этом случае мы видим, что оценка модели занимает более 10 секунд, что намного больше, чем 1 или 2 секунды, когда мы используем одно ядро для обучения и все ядра для параллельной оценки модели.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Что, если мы разделим количество ядер между процедурами обучения и оценки?
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 4) … # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 4)
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 4) … # оценить модель n_scores = cross_val_score (model, X, y, scoring = ‘точность’, cv = cv, n_jobs = 4) |
Полный пример приведен ниже.
# пример использования нескольких ядер для обучения и оценки модели от времени импорта времени из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 8) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 4) # записать текущее время начало = время () # оценить модель n_scores = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = 4) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало Распечатать(‘%.3f секунд ‘% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 | # пример использования нескольких ядер для обучения и оценки модели из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier #define dataset_assification # define dataset_assification 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 8) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 4) # запись текущего времени start = time () # оценка модели n_scores = cross_val_score (model, X, y, scoring = ‘precision’, cv = cv, n_jobs = 4) # текущее время записи конец = время () # время выполнения отчета результат = конец — начало печать (‘%.3f секунд ‘% результат) |
При выполнении примера модель оценивается с использованием четырех ядер, и каждая модель обучается с использованием четырех разных ядер.
Мы видим улучшение по сравнению с обучением со всеми ядрами и оценкой с одним ядром, но, по крайней мере, для этой модели в этом наборе данных более эффективно использовать все ядра для оценки модели и одно ядро для обучения модели.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Настройка гиперпараметров многоядерных процессоров
Обычно гиперпараметры модели машинного обучения настраивают с помощью поиска по сетке или случайного поиска.
Библиотека scikit-learn предоставляет эти возможности через классы GridSearchCV и RandomizedSearchCV соответственно.
Обе эти процедуры поиска можно сделать параллельными, установив аргумент n_jobs , назначив каждую конфигурацию гиперпараметров ядру для оценки.
Сама оценка модели также может быть многоядерной, как мы видели в предыдущем разделе, и обучение модели для данной оценки также может быть обучением, как мы видели во втором предыдущем разделе.Таким образом, стек потенциально многоядерных процессов становится сложно настраивать.
В этой конкретной реализации мы можем сделать обучение модели параллельным, но у нас нет контроля над тем, как каждый гиперпараметр модели и как каждая оценка модели делается многоядерной. Документация не ясна на момент написания, но я предполагаю, что каждая оценка модели с использованием одной базовой конфигурации гиперпараметров разбивается на задания.
Давайте рассмотрим преимущества выполнения настройки гиперпараметров модели с использованием нескольких ядер.
Во-первых, давайте оценим сетку различных конфигураций алгоритма случайного леса с использованием одного ядра.
… # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 1, cv = cv)
… # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 1, cv = cv) |
Полный пример приведен ниже.
# пример настройки гиперпараметров модели с одним ядром от времени импорта времени из sklearn.datasets импортировать make_classification из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier из sklearn.model_selection import GridSearchCV # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # определить сетку сетка = dict () сетка [‘max_features’] = [1, 2, 3, 4, 5] # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 1, cv = cv) # записать текущее время начало = время () # выполнить поиск поиск.подходят (X, y) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало print (‘%. 3f seconds’% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 22 23 24 25 26 | # пример настройки гиперпараметров модели с одним ядром из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier из sklearn.model_selection import GridSearchCV #define dataset_ 15, n_redundant = 5, random_state = 3)# определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 1) # определить сетку grid = dict () grid [‘max_features’] = [1, 2, 3, 4, 5] # определить поиск по сетке search = GridSearchCV (модель , grid, n_jobs = 1, cv = cv) # записать текущее время start = time () # выполнить поиск search.fit (X, y) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%. 3f seconds’% result) |
При выполнении этого примера проверяются различные значения конфигурации max_features для случайного леса, где каждая конфигурация оценивается с использованием повторяющейся k-кратной перекрестной проверки.
В этом случае поиск по сетке на одном ядре занимает около 28,838 секунд.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Теперь мы можем настроить поиск по сетке для использования всех доступных ядер в системе, в данном случае восьми ядер.
… # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 8, cv = cv)
… # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 8, cv = cv) |
Затем мы можем оценить, сколько времени займет выполнение этого поиска в многоядерных сетях.Полный пример приведен ниже.
# пример настройки гиперпараметров модели с 8 ядрами от времени импорта времени из sklearn.datasets импортировать make_classification из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier из sklearn.model_selection import GridSearchCV # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # определить сетку сетка = dict () сетка [‘max_features’] = [1, 2, 3, 4, 5] # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 8, cv = cv) # записать текущее время начало = время () # выполнить поиск поиск.подходят (X, y) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало print (‘%. 3f seconds’% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 22 23 24 25 26 | # пример настройки гиперпараметров модели с 8 ядрами из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier из sklearn.model_selection import GridSearchCV #define dataset_ 15, n_redundant = 5, random_state = 3)# определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 1) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 1) # определить сетку grid = dict () grid [‘max_features’] = [1, 2, 3, 4, 5] # определить поиск по сетке search = GridSearchCV (модель , grid, n_jobs = 8, cv = cv) # записать текущее время start = time () # выполнить поиск search.fit (X, y) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%. 3f seconds’% result) |
Запуск примера сообщает о времени выполнения поиска по сетке.
В этом случае мы видим примерно четырехкратное ускорение с примерно 28,838 секунды до примерно 7,418 секунды.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Интуитивно можно было ожидать, что в центре внимания должно быть создание многоядерного поиска по сетке, а не обучение модели.
Тем не менее, мы можем разделить количество ядер между обучением модели и поиском по сетке, чтобы увидеть, дает ли это преимущество для этой модели в этом наборе данных.
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 4) … # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 4, cv = cv)
… # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 4) … # определить поиск по сетке search = GridSearchCV (model, grid, n_jobs = 4, cv = cv ) |
Полный пример обучения многоядерной модели и настройки многоядерных гиперпараметров приведен ниже.
# пример обучения многоядерной модели и настройки гиперпараметров от времени импорта времени из склеарна.наборы данных импорт make_classification из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble импортировать RandomForestClassifier из sklearn.model_selection import GridSearchCV # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 3) # определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 4) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # определить сетку сетка = dict () сетка [‘max_features’] = [1, 2, 3, 4, 5] # определить поиск по сетке search = GridSearchCV (модель, сетка, n_jobs = 4, cv = cv) # записать текущее время начало = время () # выполнить поиск поиск.подходят (X, y) # записать текущее время конец = время () # время выполнения отчета результат = конец — начало print (‘%. 3f seconds’% результат)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 22 23 24 25 26 | # пример обучения многоядерной модели и настройки гиперпараметров из времени импорта из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.ensemble import RandomForestClassifier из sklearn.model_selection import GridSearchCV #define dataset_ 15, n_redundant = 5, random_state = 3)# определить модель model = RandomForestClassifier (n_estimators = 100, n_jobs = 4) # определить процедуру оценки cv = RepeatedStratifiedKFoldats (n_splits = 10, n_splits = 10, n , random_state = 1) # определить сетку grid = dict () grid [‘max_features’] = [1, 2, 3, 4, 5] # определить поиск по сетке search = GridSearchCV (модель , grid, n_jobs = 4, cv = cv) # записать текущее время start = time () # выполнить поиск search.fit (X, y) # текущее время записи end = time () # время выполнения отчета result = end — start print (‘%. 3f seconds’% result) |
В этом случае мы действительно видим снижение скорости выполнения по сравнению с одноядерным случаем, но не такое большое преимущество, как назначение всех ядер процессу поиска по сетке.
Сколько времени занимает ваша система? Поделитесь своими результатами в комментариях ниже.
Рекомендации
В этом разделе перечислены некоторые общие рекомендации при использовании нескольких ядер для машинного обучения.
- Подтвердите количество ядер, доступных в вашей системе.
- Рассмотрите возможность использования экземпляра AWS EC2 с большим количеством ядер, чтобы получить немедленное ускорение.
- Проверьте документацию по API, чтобы узнать, поддерживает ли используемая вами модель многоядерного обучения.
- Подтвердите, что многоядерное обучение дает ощутимые преимущества для вашей системы.
- При использовании k-кратной перекрестной проверки, вероятно, лучше назначить ядра для процедуры повторной выборки и оставить обучение модели одним ядром.
- При использовании настройки гиперпараметров, вероятно, лучше сделать поиск многоядерным и оставить обучение и оценку модели одноядерным.
У вас есть собственные рекомендации?
Дополнительная литература
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться.
Связанные руководства
API
Статьи
Сводка
В этом руководстве вы узнали, как настроить scikit-learn для многоядерного машинного обучения.
В частности, вы выучили:
- Как обучать модели машинного обучения с использованием нескольких ядер.
- Как сделать оценку моделей машинного обучения параллельной.
- Как использовать несколько ядер для настройки гиперпараметров модели машинного обучения.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Откройте для себя быстрое машинное обучение на Python!
Создавайте собственные модели за считанные минуты
…с помощью всего нескольких строк кода scikit-learn
Узнайте, как это сделать, в моей новой электронной книге:
Мастерство машинного обучения с Python
Охватывает руководств для самообучения и сквозных проектов , например:
Загрузка данных , визуализация , моделирование , настройка и многое другое …
Наконец-то внедрила машинное обучение в
Ваши собственные проекты
Пропустить академики. Только результаты.
Посмотрите, что внутриОпределение процессоров и сокетов — Обновлено!
Итак, некоторое время назад я разместил эту статью в нашей старой системе групп порталов.Это было довольно популярно и вызвало немало хороших разговоров. Я делаю репост здесь и попытался учесть некоторые из замечательных комментариев, которые мы получили от сообщества. Как и все в этом волнующем мире открытого исходного кода, есть буквально десятки способов снять шкуру с этой кошки. Так что, пожалуйста, продолжайте читать и дайте нам знать, если у вас есть другие варианты, которыми мы можем поделиться.
Мне недавно пришло электронное письмо от одного из моих клиентов. Его организация была готова пройти несколько лицензионных проверок, и он был в некотором недоумении.У него было несколько сторонних продуктов, по которым им нужно было вести учет, и каждый продукт был лицензирован с использованием другой модели. К сожалению, у них не было какой-либо CMDB, которая могла бы помочь (база данных управления конфигурацией — что-то очень удобное, когда дело доходит до просмотра инвентаря вашего сервера). Я вспомнил годы, когда руководил большой командой Enterprise * NIX, и содрогнулся; легко, примерно раз в месяц кто-то приходил и задавал мне одни и те же вопросы.
Итак, мы работали над несколькими простыми командами, которые можно использовать для получения этих данных.Сначала мы попробовали это:
$ ЛСКПУ | grep ‘socket’
Количество ядер на сокет: 2
Количество сокетов ЦП: 1
В «ядре» этой команды [ха-ха, каламбур] мы получили именно то, что хотел мой приятель Том, и еще немного. Мы не только можем увидеть, сколько сокетов он использовал (это то, о чем он сообщал), но мы также узнали, сколько ядер было в каждом сокете.
Затем мы попробовали что-то, хотя и менее красивое, но сосредоточенное на точных требованиях:
$ cat / proc / cpuinfo | grep «физический идентификатор» | sort -u | туалет -l
1
Это точно нам подсказало, сколько у нас розеток.физический / proc / cpuinfo | xargs -l2 echo | sort -u
физический идентификатор: 0 идентификатор ядра: 0
физический идентификатор: 0 идентификатор ядра: 1
Итак, Том вернулся к работе, счастливый и готовый дать своим начальникам ТОЧНО то, что им нужно (он был так счастлив, что у него появился новый проект сценария, над которым можно было поработать). Эти команды работали с RHEL6 обратно на RHEL4, поэтому почти каждый должен иметь возможность их использовать. Поэтому, если вы заинтересованы в их использовании, есть также несколько официальных решений, разработанных нашим уважаемым Райаном Сохиллом, которые вы также можете просмотреть :
Проверить, является ли сервер виртуальной машиной?
dmidecode | grep -i продукт
Название продукта: Виртуальная платформа VMware
Получить номер CPU
grep -i "физический идентификатор" / proc / cpuinfo | sort -u | wc -l
dmidecode | grep -i процессор
Обозначение разъема: CPU1
Обозначение разъема: CPU2
Обозначение разъема: CPU3
Обозначение разъема: CPU4
ПРОЦЕССОР.Socket.1
CPU.Socket.2
CPU.Socket.3
CPU.Socket.4
Чтобы проверить это несколькими способами:
Проверить, включен ли HyperThreading
# братьев и сестер = # ядер
cat / proc / cpuinfo | egrep 'sibling | cores'
grep -i "процессор" / proc / cpuinfo | sort -u | wc -l
Hyperthreading также можно найти с lscpu:
# lscpu | grep -i thread
Потоков на ядро: 2
#cat / proc / cpuinfo | grep "физический идентификатор" | sort -u | wc -l
0
Но dmidecode все еще показывает сокеты:
# dmidecode -t4 | egrep 'Обозначение | Статус'
Обозначение разъема: CPU 1
Статус: заселен, включен
Обозначение разъема: CPU 2
Статус: заселен, включен
И, безусловно, лучшим скрытым самородком из предыдущей статьи был инструмент, который я очень часто использую здесь в течение дня, помогая клиентам в поддержке: xsos
Я использую xsos, чтобы посмотреть информацию, представленную в sosreports, но у него много замечательных применений (например, наш вопрос о proc / socket здесь).Приобрести xsos можно здесь:
https://github.com/ryran/xsos
Yum repo доступно для xsos — инструмент для системных администраторов
На машине здесь, в лаборатории, я запустил xsos, поэтому вы можете увидеть типичный результат:
# xsos
Операционные системы
Имя хоста: LINUXizTHAawesome
Дистрибутив: Red Hat Enterprise Linux Workstation, выпуск 6.4 (Сантьяго)
Ядро: 2.6.32-358.18.1.el6.x86_64
Уровень выполнения: N 5 (по умолчанию: 5)
SELinux: принудительное (по умолчанию: принудительное)
Системное время: 12 сентября, четверг, 08:17:11 EDT 2013
Время загрузки: Вт, 10 сентября, 07:29:28 EDT 2013 (1378812568)
Время работы: 2 дня, 47 мин., 2 пользователя
LoadAvg: 0.13 (3%), 0,14 (4%), 0,10 (2%)
Время ЦП с момента загрузки:
us 7%, ni 0%, sys 1%, idle 91%, iowait 1%, irq 0%, sftirq 0%, steal 0%
procs_running (procs_blocked):
2 (0)
Проверка на заражение ядра: 0 (ядро не повреждено)
<снип>
Процессор
4 логических процессора (2 ядра ЦП)
1 процессор Intel Core i7-2640M @ 2,80 ГГц (флаги: aes, ht, lm, pae, vmx)
└─4 потока / по 2 ядра
<снип>
Так БАМ! Именно там именно то, что мы хотели, в красиво оформленном выводе.
Итак, у нас есть несколько официальных статей, на которые вы также можете ссылаться:
Как определить количество сокетов ЦП в системе
и
Разница между физическим процессором, ядрами процессора и логическим процессором
Так что ты думаешь? Это полезный материал? Сэкономит ли это ваше время или даже поможет ли вам начать работу над собственной CMDB? Мы хотели бы услышать от вас!
Ура,
CRob
Технический менеджер по работе с клиентами
Red Hat Inc.
Содержание и структура теста Praxis Core (для участников тестирования)
Praxis ® Основные академические навыки для преподавателей Тесты состоят из трех отдельных тестов:
- Тест по чтению: Базовый тест по чтению включает в себя наборы вопросов, которые требуют интеграции и анализа нескольких документов, а также некоторые альтернативные типы ответов, например, выбор при переходе.См. Раздел «Подготовка к экзамену по чтению».
- Письменный тест: Основной письменный тест оценивает как аргументированное письмо, так и информативное / поясняющее письмо и будет содержать одно письменное задание для каждого типа письма. Кроме того, будут добавлены вопросы с отобранными ответами, чтобы осветить важность исследовательских стратегий и оценить стратегии пересмотра и улучшения текста. См. Раздел Подготовка к письменному тесту. Тест по математике
- : основной тест по математике включает вопросы с числовым вводом и выбранными ответами, а также предлагает экранный калькулятор, который помогает убедиться, что вопросы проверяют математическое мышление, уменьшая вероятность того, что неправильный ответ экзаменуемого исходит из простой арифметики. ошибка.См. Раздел «Подготовка к экзамену по математике».
Тестовая структура Praxis Core
ТестыPraxis Core включают вопросы с объективным ответом, такие как вопросы с одним выбором ответов, вопросы с несколькими вариантами ответов и вопросы с числовым вводом. Тест Praxis Core Writing также включает два раздела для сочинений.
Тесты Praxis Core доставляются на компьютере и могут проводиться как три отдельных теста в отдельные дни или как один комбинированный тест. Будут сообщены индивидуальные оценки по чтению, математике и письму как в индивидуальном, так и в комбинированном тестах.
Если вы проходите тесты Praxis Core отдельно, каждое занятие длится два часа. Если пройти комбинированный тест, вся сессия длится пять часов. Каждое занятие включает время для обучающих программ и сбор справочной информации.
Фактическое время тестирования и количество вопросов для каждого теста Praxis Core показано ниже:
| Тест | Количество вопросов | Время тестирования |
|---|---|---|
| Чтение (5713) | 56 | 85 мин. |
| Математика (5733) | 56 | 90 мин. |
| Письмо (2 секции) (5723) | 40 2 эссе | 40 мин. 60 мин. |
Как создаются тестовые вопросы
Педагоги, факультеты программ подготовки учителей и специалисты по дисциплинам готовят тестовые вопросы Praxis. Разработчики и рецензенты следуют строгим стандартизированным процедурам, чтобы гарантировать, что тестовые материалы отражают проверяемые навыки и соответствуют высоким стандартам оценки качества.Каждый вопрос рассматривается экспертами ETS, а также консультативными группами по содержанию, которые также участвуют в разработке руководящих принципов и стандартов того, что должны измерять тесты.
После того, как вопросы теста были рассмотрены и исправлены, они вводятся в пробные ситуации и объединяются в тесты. Затем тесты проверяются в соответствии с процедурами ETS, чтобы убедиться, что все тесты не содержат культурных предубеждений. Статистический анализ отдельных вопросов гарантирует, что все элементы предоставляют соответствующую информацию об измерениях.
Как определить загрузку ЦП | Small Business
Повышение приоритета ЦП для программы увеличивает внимание ЦП к этой программе, повышая ее производительность. Для малого бизнеса определение использования ЦП может помочь сэкономить время. Например, увеличение приоритета для задачи с высокой загрузкой ЦП, такой как компиляция базы данных, приводит к более быстрому завершению действия, что позволяет вам сосредоточиться на других задачах. Кроме того, некоторые старые программы работают лучше, когда они используют только одно ядро, а не все количество ядер, которое предлагает ваш ЦП.Процесс определения использования ЦП различается в зависимости от того, меняете ли вы приоритет или устанавливаете количество ядер.
Настройка использования ядра ЦП
1
Нажмите клавиши «Ctrl», «Shift» и «Esc» на клавиатуре одновременно, чтобы открыть диспетчер задач.
2
Щелкните вкладку «Процессы», затем щелкните правой кнопкой мыши программу, для которой требуется изменить использование ядра ЦП, и выберите «Установить соответствие» во всплывающем меню.
3
Установите флажок рядом с «ЦП 0» или «ЦП 1», чтобы назначить этой программе только это ядро ЦП.Если у вас четырехъядерный процессор, есть два дополнительных блока «ЦП»: «ЦП 2» и «ЦП 3». Программе с четырехъядерным процессором можно назначить от одного до трех ядер. Если у вас одноядерный процессор, такой как более ранняя модель Pentium, вы не можете установить соответствие ядра.
4
Нажмите «ОК», чтобы установить привязку ядра. Вы должны делать это каждый раз, когда закрываете и снова открываете программу.
Установка приоритета ЦП
1
Нажмите клавиши «Ctrl», «Shift» и «Esc» на клавиатуре одновременно, чтобы открыть диспетчер задач.
2
Щелкните вкладку «Процессы», щелкните правой кнопкой мыши программу, для которой необходимо изменить приоритет ЦП.
3
Наведите курсор на «Установить приоритет» и выберите настройку приоритета. Ваши изменения применяются автоматически, как только вы выбираете настройку. Вы должны делать это каждый раз, когда закрываете и снова открываете программу.
Ссылки
Советы
- Эти шаги также применимы к Windows Vista.