
бесплатный номер телефона 8 800 по РФ
Консультация автоюриста по телефону
По Москве и московской области
8 (499) 938-41-60
Санкт-Петербург и область
8 (812) 425-63-04
Бесплатно по России
8 (800) 301-87-34
Задать вопрос юристуСоюз автостраховщиков (РСА) объединяет порядка полусотни компаний, предоставляющих услуги по страхованию автогражданской ответственности. В его компетенцию входит регулирование всех вопросов, связанных с данной сферой рынка страхования.
Для удобства автовладельцев действует телефон горячей линии РСА, по которым они могут обратиться в Союз с интересующими их вопросами.
Работа информационного центра
Возможность связаться с информационным центром имеется у всех жителей нашей страны. Горячая линия российского союза автостраховщиков РСА работает в круглосуточном режиме, без выходных дней. Специалисты центра помогут решить клиенту большинство проблем, связанных со всеми аспектами автогражданского страхования.
Многоканальный номер телефона горячей линии РСА – 8 800 200 22 75.
Сотрудники центра готовы оказать каждому автовладельцу широкий спектр правовой и информационной поддержки. Для увеличения скорости обслуживания, обращающимся гражданам рекомендуется заранее подготовить следующую документацию:
- Общегражданский паспорт.
- Водительское удостоверение.
- Полис ОСАГО.
Телефон горячей линии РСА, начинающийся на 8 800 бесплатный для всех регионов РФ, также не имеется никаких ограничений по времени продолжительности звонка.
Другие способы связи
Жители столицы и ее области, кроме единой горячей линии РСА, контакты со специалистами могут установить по дополнительному номеру 8 (495) 641-27-85. Звонки от автовладельцев принимаются также работниками главного офиса Союза, расположенного в Москве, по телефону 8 (495) 771-69-44. Сюда можно обратиться с вопросом о размере и нюансах выплат по наступившему страховому случаю. Офис работает с понедельника по пятницу, с 9:00 до 18:00.
Офис работает с понедельника по пятницу, с 9:00 до 18:00.
Для разрешения вопросов, касающихся действия международной «Зелёной карты», выделен отдельный телефон РСА 8 (495) 771-69-47. Специалисты готовы предоставить всю необходимую информацию о «Грин кард» с понедельника по пятницу, с 8:00 до 17:00. Отдельный канал бесплатного телефона горячей линии РСА выделен для службы, отвечающей за ОСАГО: 8 800 200 22 75.
Сотрудники информационного центра готовы предоставить клиентам всю информацию относительно расчёта стоимости полиса и порядка получения компенсационных выплат по страховке.
Обратиться к специалистам Союза можно воспользовавшись, помимо телефона горячей линии РСА, официальным сайтом, расположенным по адресу: www.autoins.ru.
|
Россия / Russia Российский Союз Автостраховщиков (РСА) Некоммерческая организация «Российский союз автостраховщиков» Регистрационный номер: 0 Адрес: 117049, г. Москва, ул. Мытная, дом.1, стр.1, 3-й этаж, пом. I (м. Октябрьская) Москва, ул. Мытная, дом.1, стр.1, 3-й этаж, пом. I (м. Октябрьская)
Данные получены из открытых источников, пресс-служб компаний и организаций. Редакция портала не несет ответственности за возможные ошибки или неточности в приведенных данных и всячески приветствует указания на такие случаи с сообщением более точной, корректной или актуальной информации. |
||||||||||||||||||||||||||||||||||||||||||||||||||||
 autoins.ru
autoins.ru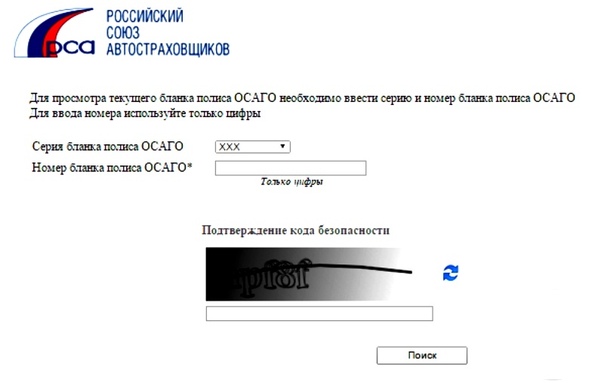 insur-info.ru/img/punctirGray.gif»>
insur-info.ru/img/punctirGray.gif»>
Телефон горячей линии 8 800 РСА по ОСАГО и общим вопросам
Получить консультацию и правовую помощь возможно по телефонам информационного центра РСА:
- 7 (495) 64-12-785 – для жителей Москвы и Подмосковья.
- 8 (800) 200-22-75 – для жителей остальных регионов страны.
Звонить можно круглосуточно.
В случае наличия претензий или обращений можно отправить запрос на официальную электронную почту РСА request@autoins. ru либо дополнительный: [email protected].
ru либо дополнительный: [email protected].
Телефон горячей линии РСА 8800
Для получения актуальной информации и помощи, касающейся сферы страхования, у вас есть возможность обратиться к специалистам по горячей линии Российского Союза Автостраховщиков.
Служба поддержки РСА доступна 24 часа и предоставляется всем жителям регионов РФ. За звонки с территории России плата не взимается.
Горячая линия РСА не ограничивает количество минут. Вы можете задать все интересующие вопросы. Для того чтобы специалист смог оперативно приступить к решению проблемы, заранее приготовьте паспорт, водительские права и договор страхования.
Информационный центр РСА по «Зеленой карте»
Если вы желаете проконсультироваться по вопросам обязательного страхования по системе «Зелёная карта», у вас есть возможность обратиться в информационно–консультационный центр по номеру 7 (495) 641-27-87.
Телефон горячей линии РСА по ОСАГО
РСА предоставляет горячую линию и по вопросам оформления, изменения и прекращения договора ОСАГО.
Позвонить в РСА по вопросам со своим страховым полисом можно по телефонам:
- 7 (495) 64-12-785 – для жителей Москвы и Подмосковья.
- 8 (800) 200-22-75 – для жителей остальных регионов страны.
Другие способы связи
Адрес головного офиса РСА: Москва, ул. Люсиновская, д. 27, стр. 3. Индекс РСА: 115093. Этот же юридический адрес РСА офиса можно использовать для корреспонденции.
Письма лучше отправлять заказные, с уведомлением о вручении. Так вы сможете проверять отправку в режиме онлайн.
В офисе также работает автоматический факс. Его номер: 7 (495) 77-16-944, доб. 133. Укажите тему обращения, так ваш запрос будет рассмотрен быстрее.
На сайте Российского Союза Автостраховщиков — www. autoins.ru, создана электронная приёмная. Попасть на страницу можно сразу при переходе с главной: вверху и внизу страницы есть соответствующие разделы на сером фоне.
autoins.ru, создана электронная приёмная. Попасть на страницу можно сразу при переходе с главной: вверху и внизу страницы есть соответствующие разделы на сером фоне.По каким вопросам специалисты могут помочь
- Оформление договора ОСАГО;
- По договору страхования «Зелёная карта»;
- По расчёту КБМ;
- Нарушение договора со стороны страховой компании;
- Информация о лицензии;
- О денежной компенсации.
По каким вопросам поддержка помочь НЕ может
Специалисты не оформляют договор страхования в электронном виде. Они не переводят компенсации и не производят денежные выплаты. Специалист не сможет проконсультировать без предоставления нужных сведений.
Время ответа и компетентность специалистов
- Электронное письмо отправляется в ту же секунду, обратную связь от РСА можно получить в течение суток.
- Ответ на обращение, высланное на почтовый адрес РСА, даётся не позднее, чем через 10 дней после регистрации.
- Время ответа на звонок занимает от нескольких минут до получаса.
 Это зависит от загруженности линии.
Это зависит от загруженности линии. - Операторы горячей линии владеют актуальной информацией и оказывают профессиональную помощь в решении вопросов. Все переговоры ведутся на русском языке.
 Это зависит от загруженности линии.
Это зависит от загруженности линии.Заключение
При возникновении спорных ситуаций или для получения нужной информации, вы всегда можете обратиться к операторам Российского союза автостраховщиков либо к авто юристу. Всё, что вам нужно — выбрать наиболее удобный для себя способ, приготовить необходимые документы и сформулировать вопрос. Специалисты окажут вам квалифицированную помощь и поддержку.
РСА отверг возможность утечки данных водителей от страховщиков
https://ria.ru/20200803/1575322871.html
РСА отверг возможность утечки данных водителей от страховщиков
РСА отверг возможность утечки данных водителей от страховщиков — РИА Новости, 03.08.2020
РСА отверг возможность утечки данных водителей от страховщиков
Российский союз автостраховщиков (РСА) опроверг возможность утечки личных данных более миллиона московских водителей от союза или страховых компаний, заявив,. .. РИА Новости, 03.08.2020
.. РИА Новости, 03.08.2020
2020-08-03T18:49
2020-08-03T18:49
2020-08-03T19:07
осаго
российский союз автостраховщиков
москва
московская область (подмосковье)
общество
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdn21.img.ria.ru/images/149907/25/1499072561_0:3:1036:586_1920x0_80_0_0_383b0d12af43c4d48eec09f9f92a64e2.jpg
МОСКВА, 3 авг — РИА Новости. Российский союз автостраховщиков (РСА) опроверг возможность утечки личных данных более миллиона московских водителей от союза или страховых компаний, заявив, что в их базах даже нет таких полей, как в выставленной на продажу.Ранее газета «Коммерсант» сообщила, что в интернете выставлена на продажу база личных данных около 1 миллиона автомобилистов Москвы и Подмосковья. База, по данным газеты, появилась 24 июля, ее стоимость составляет 1,5 тысячи долларов. В ней содержатся дата регистрации автомобиля, государственный регистрационный знак, марка, модель, год выпуска, фамилия, имя и отчество владельца, его телефон и дата рождения, регион регистрации, VIN-код, серия и номер свидетельства о регистрации и ПТС. Основатель компании DeviceLock и сервиса разведки утечек DLBI Ашот Оганесян сообщил РИА Новости, что база личных данных автомобилистов Москвы и Подмосковья продается в сети уже несколько лет и ежемесячно обновляется актуальными данными, а значит, стоять за этой утечкой может инсайдер в крупной страховой компании. Возможность утечки данных от страховых компаний предположил и источник РИА Новости в правоохранительных органах.»Так, данные о регистрации, постановке на регистрационный учет и дата снятия автомобиля с учета, это та информация, которая отсутствует у страховщиков», — говорится у сообщении.Между тем в базе союза АИС ОСАГО содержится информация или о государственном регистрационном знаке, или о VIN-номере, а в базе РСА и страховщиков содержатся данные о номере полиса и о дате заключения договора страхования, чего нет в утекших базах данных, отметил союз.Вдобавок в РСА обратили внимание на то, что страхователь и автовладелец не всегда совпадают, поскольку страхователь, заключивший договор, может быть иным лицом, не управляющим автомобилем.
Основатель компании DeviceLock и сервиса разведки утечек DLBI Ашот Оганесян сообщил РИА Новости, что база личных данных автомобилистов Москвы и Подмосковья продается в сети уже несколько лет и ежемесячно обновляется актуальными данными, а значит, стоять за этой утечкой может инсайдер в крупной страховой компании. Возможность утечки данных от страховых компаний предположил и источник РИА Новости в правоохранительных органах.»Так, данные о регистрации, постановке на регистрационный учет и дата снятия автомобиля с учета, это та информация, которая отсутствует у страховщиков», — говорится у сообщении.Между тем в базе союза АИС ОСАГО содержится информация или о государственном регистрационном знаке, или о VIN-номере, а в базе РСА и страховщиков содержатся данные о номере полиса и о дате заключения договора страхования, чего нет в утекших базах данных, отметил союз.Вдобавок в РСА обратили внимание на то, что страхователь и автовладелец не всегда совпадают, поскольку страхователь, заключивший договор, может быть иным лицом, не управляющим автомобилем.
https://ria.ru/20200803/1575307684.html
https://radiosputnik.ria.ru/20200803/1575322306.html
москва
московская область (подмосковье)
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2020
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
https://cdn22.img.ria.ru/images/149907/25/1499072561_127:0:911:588_1920x0_80_0_0_7dfa245f411fa9073a43383a05ce24ac.jpgРИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og. xn--p1ai/awards/
xn--p1ai/awards/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
осаго, российский союз автостраховщиков, москва, московская область (подмосковье), общество
МОСКВА, 3 авг — РИА Новости. Российский союз автостраховщиков (РСА) опроверг возможность утечки личных данных более миллиона московских водителей от союза или страховых компаний, заявив, что в их базах даже нет таких полей, как в выставленной на продажу.Ранее газета «Коммерсант» сообщила, что в интернете выставлена на продажу база личных данных около 1 миллиона автомобилистов Москвы и Подмосковья. База, по данным газеты, появилась 24 июля, ее стоимость составляет 1,5 тысячи долларов. В ней содержатся дата регистрации автомобиля, государственный регистрационный знак, марка, модель, год выпуска, фамилия, имя и отчество владельца, его телефон и дата рождения, регион регистрации, VIN-код, серия и номер свидетельства о регистрации и ПТС.
3 августа 2020, 14:54
Эксперт предупредил об угрозе угона машин после кражи базы данныхОснователь компании DeviceLock и сервиса разведки утечек DLBI Ашот Оганесян сообщил РИА Новости, что база личных данных автомобилистов Москвы и Подмосковья продается в сети уже несколько лет и ежемесячно обновляется актуальными данными, а значит, стоять за этой утечкой может инсайдер в крупной страховой компании. Возможность утечки данных от страховых компаний предположил и источник РИА Новости в правоохранительных органах.«РСА опровергает возможный факт утечки информации о автовладельцах из баз союза и страховщиков: выставленные на продажу поля данных отсутствуют в их информационных системах», — заявила пресс-служба объединения.
«Так, данные о регистрации, постановке на регистрационный учет и дата снятия автомобиля с учета, это та информация, которая отсутствует у страховщиков», — говорится у сообщении.
Между тем в базе союза АИС ОСАГО содержится информация или о государственном регистрационном знаке, или о VIN-номере, а в базе РСА и страховщиков содержатся данные о номере полиса и о дате заключения договора страхования, чего нет в утекших базах данных, отметил союз.
Вдобавок в РСА обратили внимание на то, что страхователь и автовладелец не всегда совпадают, поскольку страхователь, заключивший договор, может быть иным лицом, не управляющим автомобилем.
3 августа 2020, 18:37
Прокуратура начала проверку о продаже в сети данных миллиона водителейбесплатный номер телефона 8 800 в РФ
В настоящее время существует система обязательного страхования для водителей ОСАГО, которая была введена для выплаты пострадавшей стороне нанесенного в ходе ДТП ущерба. Данная услуга имеет свои преимущества, которые оценили владельцы авто.
Система достаточно проста в использовании, однако если у вас возникли вопросы, можно обратиться в РСА. Помимо официальных офисов и сайтов компании существует горячая линия РСА (Российский союз автостраховщиков), по которой вы сможете получить ответы на все возникшие вопросы.
- Для жителей всей России при обращении в РСА телефон горячей линии 8-800-200-22-57 бесплатно.
- Жителям Москвы и области горячая линия РСА телефон: (495)-641-27-85.

Адрес электронной почты для приема скан-копий жалоб и обращений: [email protected].
[expert_bq id=835]В случае, если Ваш вопрос касается страхования в рамках международной системы страхования «Зеленая карта», Вы можете обратиться по телефону Информационно–консультационного центра «Зеленая карта» (495) 641-27-87[/expert_bq].
При обращении в РСА по телефону горячей линии вы сможете получить подробную информацию по возникшей проблеме. Для этого вам понадобится подробно описать возникшую ситуацию, чтобы оператор смог правильно найти решение. Также пользователю придется ответить на несколько вопросов оператора по телефону, для этого могут понадобиться ваши персональные данные.
После обращения водителю будет оказана помощь по возникшим вопросам ОСАГО, также при желании можно оставить жалобу на страховую компанию, оформившую полис. Союз автостраховщиков поможет своим пользователям и решит проблему в короткие сроки.
Союз автостраховщиков поможет своим пользователям и решит проблему в короткие сроки.
Стоит отметить, что в РСА телефон горячей линии бесплатный, поэтому помощь может получить любой желающий по всей России. Чтобы узнать номер телефона РСА для вашего региона, можно зайти на официальный сайт и посмотреть список номеров горячей линии РСА в разделе «РСА контакты горячая линия». Также можно позвонить по универсальному бесплатному номеру.
Телефон горячей линии РСА: бесплатный номер
Если шоферы столкнулись с какой-либо проблемой, то они обращаются за помощью к РСА и горячая линия помогает им решать возникшие проблема. Для наилучшего контакта создана горячая линия, куда водитель может позвонить и проконсультироваться.
Содержание статьи
Коротко об организации
Основными задачами Союза являются:
- разного рода выплаты;
- защита потерпевших;
- взаимодействие агентств и владельцев того или иного транспорта.

Зачастую РСА добивается разрешения сложных задач, с которыми могли столкнуться водители.
У организации имеются свои специалисты, которые относятся к разным профессиям, и каждый выполняют индивидуальные задачи. Все работники обязаны пройти обязательную подготовку длиною в несколько месяцев.
Задачи РСА
В задачи сотрудников входят:
- Осуществление всех законов. Это весьма серьёзная и важная задача. Работники взаимодействуют с международными страховыми ассоциациями.
- Осуществление законов в информативном пространстве.
- Юристы оказывают свою помощь в суде.
- Обеспечение информацией Интернет-ресурсов и их формирование. Это главная задача программистов.
- Выплата компенсаций.
- Стараются создать взаимодействие.
- Контролирование правил, связанных с профессиональной деятельностью.
Бесплатная линия
Горячая линия и так подразумевает собой бесплатный телефонный звонок. Каждый водитель, столкнувшись с проблемой, которую не может решить самостоятельно, может набрать номер телефона горячей линии РСА, чтобы получить помощь специалиста. Линия создана целенаправленно для консультирования или для входящих звонков. Это удобно, выгодно и полезно.
Каждый водитель, столкнувшись с проблемой, которую не может решить самостоятельно, может набрать номер телефона горячей линии РСА, чтобы получить помощь специалиста. Линия создана целенаправленно для консультирования или для входящих звонков. Это удобно, выгодно и полезно.
Номера телефонов и контактов РСА (Российский Союз Автостраховщиков):
- для регионов: 8-800-200-22-75;
- для Москвы: (495) — 641-27-85;
- [email protected].
Адрес в Москве: ул. Люсиновская 27/3 (вт. 15:00-18:00 и чт. 09:00-12:00),
Для автостраховщиков она предназначается для решения следующих целей:
- обращения по ОСАГО;
- жалобы по ОСАГО.
Важно: линия занимается исключительно приёмом обращений и жалоб по ОСАГО от потерпевших лиц.
Для определённого региона разработаны персональные контакты (номера телефонов, e-mail и так далее), по которым владелец авто может обратиться.
Важно: каждый шофёр должен дать чёткую и подробную информацию, чтобы ему могли оказать быструю помощь. Также он должен предоставить ответы на все получаемые вопросы от оператора.
Существуют ещё единые номера для Москвы и регионов. Например, жители, проживающие в столице, будут обращаться по одному единому номеру. А жители Екатеринбурга — по другому. Все контакты прописаны на сайте РСА.
Только сам водитель может защитить себя, поэтому ему надо обязательно связаться с оператором, чтобы получить помощь. Для этого он должен предоставить информацию о себе, которая понадобится оператору.
Важно: все сведения должны соответствовать реальности.
Какие ещё права и возможности имеет РСА?
Как и любая другая организация, Союз имеет многие возможности.
К ним относятся:
- применять напор на страховое агентство, при этом не нарушая законов;
- предоставлять данные;
- защищать членов Союза;
- обеспечение технического характера;
- подготовка и использование электронных ресурсов.
Таким образом, РСА является одним из главных помощников шофёров. Союз защищает права, делает выплаты, разрешает вопросы в суде. Если у пострадавшего лица появилось обращение или возникла жалоба, то он имеет право обратиться за помощью, позвонив по горячей линии.
Оператор, получив необходимые сведения, проконсультирует владельца авто насчёт той или иной проблемы.
Следует помнить, что для региональных территорий действуют разные контакты, по которым можно связаться со специалистами. Все их можно найти на сайте.
Связавшись с оператором, шофёр должен дать правильные и истинные сведения, которые не противоречат реальности.
Интересное видео
Внимание!
В связи с частыми изменениями административных законов РФ и правил ПДД, информацию на сайте не всегда успеваем обновлять, в связи с этим
Горячие линии:
Москва: +7 (499) 653-60-72, доб. 206
Санкт-Петербург: +7 (812) 426-14-07, доб. 997
Регионы РФ: +7 (800) 500-27-29, доб. 669.
Заявки принимаются круглосуточно и каждый день. Либо воспользуйтесь онлайн формой.
телефон службы поддержки, бесплатный номер 8-800
Российский Союз Автостраховщиков (РСА) сплотил все организации, занимающиеся автомобильным страхованием в России. Совместное сотрудничество помогает принимать согласованные решения и правила работы. Статус РСА закреплен законодательством, поэтому справедливость и компетентность решений не подвергается сомнению. Организация обладает горячей линией. Любой пользователь может получить консультацию по телефону.
Телефон горячей линии союза автостраховщиков (РСА)
8 800 200 22 75 – единая горячая линия для клиентов компании. Совершение звонка всегда бесплатное, независимо от региона проживания пользователя. Дозвониться можно со стационарного или сотового телефона.
Чтобы оптимизировать работу контактного центра, жителям самых крупных городов России – Санкт-Петербурга и Москвы – доступен дополнительный номер. Обращения принимаются по телефону +7(495) 641 27 85. Совершение звонка бесплатное.
Для получения справочной информации набирайте номер центрального отделения компании – +7(495) 771 69 44.
Вопросы, связанные с использованием «Зеленой Карты» или ОСАГО решаются по номерам +7(495) 771 69 42 и +7(495) 771 69 47.
Как задать вопрос?
Российский союз автостраховщиков обладает несколькими способами связи кроме горячей линии:
- Электронная почта;
- Обратная связь.
Составьте подробное описание вопроса и приложите контактные данные. Отправьте полученное сообщение по адресу [email protected] или [email protected]. Сотрудники контактного центра гарантированно рассматривают каждое поступающее обращение, поэтому пользоваться обычной почтовой службой бессмысленно.
Дополнительный способ связи подразумевает использование формы обратной связи. Откройте раздел «Электронная приемная» на сайте и заполните предложенные строки:
- Ф. И. О.;
- Контактные данные;
- Тема;
- Обращение.
Среднестатистическое время рассмотрения обращения составляет несколько рабочих дней. Точный срок ответа варьируется от сложности проблемы.
Контакты для прессы
Представители прессы пишут на электронную почту [email protected]. В особых случаях допускается пользоваться общей горячей линией.
Функции горячей линии РСА
- Неправомерные решения страховой компании;
- Неверный расчет скидки КБ;
- Получение «Зеленой Карты», ОСАГО;
- Просмотр реестра лицензий.
Как получить консультацию через личный кабинет?
Организация разработала личный кабинет, позволяющий пользователям отправлять вопросы. После авторизации откройте раздел «Техническая поддержка» во вкладке «Обратная связь». Напишите электронное обращение согласно предложенной форме. Затем нажмите кнопку «Отправить». Сотрудники контактного центра своевременно решат вопрос и отправят ответ на ваши контактные данные.
Когда горячая линия не помогает
Некоторые вопросы рассматриваются исключительно в отделениях организации. Например, консультанты не занимаются вопросами, связанными с получением компенсаций или покупкой страхового полиса.
Как отправить жалобу в союз автостраховщиков?
Претензии принимаются несколькими способами. Вы можете позвонить на горячую линию или отправить письменное обращение через «Обратную связь».
График работы
Ввиду широких масштабов работы компании, консультации проводятся круглосуточно. Дозвониться на горячую линию можно в любой день недели. Операторы принимают вызовы практически сразу. Исключением является время высокой загруженности контактного центра – иногда требуется длительное ожидание ответа.
Официальный сайт: https://autoins.ru/
Вход в личный кабинет: https://autoins.ru/login/
PCA — как выбрать количество компонентов?
В этой статье я покажу вам, как выбрать количество главных компонентов при использовании анализа главных компонентов для уменьшения размерности.
В первом разделе я дам вам короткий ответ для тех из вас, кто спешит и хочет, чтобы что-то работало. Позже я дам более развернутое объяснение тем из вас, кто заинтересован в понимании PCA.
Не делай этого. Не выбирайте количество компонентов вручную. Вместо этого используйте опцию, которая позволяет вам установить дисперсию входных данных, которая должна объясняться сгенерированными компонентами.
Не забудьте масштабировать данные в диапазоне от 0 до 1 перед использованием PCA!
1
2
3
из sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler ()
data_rescaled = масштабатор.fit_transform (данные)
Обычно мы хотим, чтобы объясненная дисперсия составляла 95–99%. В Scikit-learn мы можем установить это так:
1
2
3
4
5
// 95% отклонения
из sklearn.decomposition import PCA
pca = PCA (n_components = 0,95)
pca.fit (data_rescaled)
уменьшенный = pca.transform (масштаб_данных)
или
1
2
3
4
5
// 99% отклонения
из склеарна.декомпозиция импорта PCA
pca = PCA (n_components = 0,99)
pca.fit (data_rescaled)
уменьшенный = pca.transform (масштаб_данных)
Как работает PCA
Во-первых, алгоритм PCA стандартизирует фрейм входных данных, вычисляет ковариационную матрицу признаков.
Теперь давайте попробуем представить, что каждое значение из ковариационной матрицы является вектором. Этот вектор указывает направление в n-мерном пространстве (n — количество функций в исходном фрейме данных).Что такое вектор? Мы можем представить это как «стрелку», указывающую в каком-то направлении в этом n-мерном пространстве.
Эти векторы могут быть «усреднены» путем создания другого вектора, который «указывает» более или менее в том же направлении, что и все эти усредненные векторы. Мы называем это собственным вектором. Он также имеет значение (представим его как «длину» «стрелки»), которое коррелирует с количеством векторов, усредненных собственным вектором (чем больше усредненных векторов ковариации, тем больше собственное значение).
После этого мы сортируем собственные векторы по их собственным значениям. Помните, что мы уже выбрали точку отсечения (желаемое отклонение, которое должно объясняться основными компонентами). Это означает, что мы можем выбрать собственные векторы, которые в сумме дают желаемый порог объясненной дисперсии.
Теперь мы умножаем стандартизованный фрейм данных функции на матрицу главных компонентов, и в результате мы получаем сжатое представление входных данных.
Есть отличная статья, написанная Закарией Джаади, который объясняет PCA и показывает пошаговые инструкции по вычислению результата.
Как выбрать количество компонентов
Теперь мы знаем, что главные компоненты частично объясняют дисперсию. Из реализации Scikit-learn мы можем получить информацию об объясненной дисперсии и построить кумулятивную дисперсию.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 год
22
23
pca = PCA (). Fit (data_rescaled)
% matplotlib встроенный
импортировать matplotlib.pyplot как plt
plt.rcParams ["figure.figsize"] = (12,6)
fig, ax = plt.subplots ()
xi = np.arange (1, 11, шаг = 1)
y = np.cumsum (pca.explained_variance_ratio_)
plt.ylim (0,0,1.1)
plt.plot (xi, y, marker = 'o', linestyle = '-', color = 'b')
plt.xlabel ('Количество компонентов')
plt.xticks (np.arange (0, 11, step = 1)) # переход с индекса массива на основе 0 на удобочитаемую метку на основе 1
plt.ylabel ('Совокупная дисперсия (%)')
plt.title ('Количество компонентов, необходимых для объяснения дисперсии')
plt.axhline (y = 0,95, цвет = 'r', стиль линии = '-')
plt.текст (0,5; 0,85, '95% порог отсечения', цвет = 'красный', размер шрифта = 16)
ax.grid (ось = 'x')
plt.show ()
На построенном графике мы видим, какое количество основных компонентов нам нужно.
В этом случае, чтобы получить объяснение 95% дисперсии, мне нужно 9 основных компонентов.
Не забудьте поделиться в социальных сетях! Если вам нравится этот текст, поделитесь им в Facebook / Twitter / LinkedIn / Reddit или в других социальных сетях.
Если вы хотите связаться со мной, отправьте мне сообщение в LinkedIn или Twitter.
Хотите позвонить и поговорить? Пожалуйста, назначьте встречу, используя эту ссылку.
Извлечение сигналов PCA — step_pca • recipes
step_pca создает спецификацию шага рецепта, который преобразует
числовые данные в один или несколько основных компонентов.
step_pca (
рецепт приготовления,
...,
роль = "предсказатель",
обучено = ЛОЖЬ,
num_comp = 5,
порог = NA,
параметры = список (),
res = NULL,
prefix = "ПК",
keep_original_cols = ЛОЖЬ,
skip = FALSE,
id = rand_id ("pca")
) Аргументы
| рецепт | Объект рецепта. Шаг будет добавлен в последовательность операций по этому рецепту. |
|---|---|
| … | Одна или несколько функций выбора для выбора переменных, которые будут
используется для вычисления компонентов.См. |
| роль | Для модельных терминов, созданных на этом этапе, какая роль анализа должна они будут назначены ?. По умолчанию функция предполагает, что новый участник столбцы компонентов, созданные исходными переменными, будут использоваться как предикторы в модели. |
| обучено | Логично указать, если количества для предварительная обработка. |
| число_комп | Количество компонентов PCA, которые необходимо сохранить в качестве новых предикторов.
Если |
| порог | Доля общей дисперсии, которая должна быть покрыта
компоненты. Например, порог |
| варианты | Список опций метода по умолчанию для |
| рез | Статистика |
| префикс | Символьная строка, которая будет префиксом полученного новые переменные. См. Примечания ниже. |
| keep_original_cols | Логично сохранить исходные переменные в
выход. По умолчанию |
| пропустить | А логический.Следует ли пропускать шаг, когда
рецепт выпекается по |
| id | Строка символов, уникальная для этого шага для ее идентификации. |
Значение
Обновленная версия рецепта с новым шагом, добавленным в
последовательность существующих шагов (если есть).
Детали
Анализ главных компонентов (PCA) — это преобразование группа переменных, которая создает новый набор искусственных функции или компоненты. Эти компоненты предназначены для захвата максимальный объем информации (т.е. дисперсия) в исходные переменные. Кроме того, компоненты статистически независимы друг от друга.Это означает, что их можно использовать для борьбы с большими корреляциями между переменными в наборе данных.
Перед запуском рекомендуется стандартизировать переменные.
PCA. Здесь каждая переменная будет центрирована и масштабирована до
расчет PCA. Это можно изменить с помощью параметры аргумент или с помощью step_center () и step_scale () .
Аргумент num_comp управляет количеством компонентов, которые
будут сохранены (исходные переменные, которые используются для получения
компоненты удалены из данных).Новые компоненты
будут иметь имена, начинающиеся с префикса и последовательность
числа. Имена переменных дополняются нулями. Например,
если num_comp <10 , их имена будут PC1 - PC9 .
Если num_comp = 101 , имена будут PC001 - РС101 .
В качестве альтернативы, порог может использоваться для определения
количество компонентов, необходимых для захвата указанного
доля от общей дисперсии переменных.
Когда вы tidy () на этом шаге, используйте type = "coef" для переменной.
загрузок на компонент или type = "variance" для того, сколько отклонений каждый
компонент составляет.
Список литературы
Джоллифф И. Т. (2010). Главный компонент Анализ . Springer.
См. Также
Примеры
rec <- recipe (~., Data = USArrests)
pca_trans <- rec%>%
step_normalize (all_numeric ())%>%
step_pca (all_numeric (), num_comp = 3)
pca_estimates <- prepare (pca_trans, training = USArrests)
pca_data <- запекать (pca_estimates, USArrests)
rng <- расширить диапазон (c (pca_data $ PC1, pca_data $ PC2))
участок (pca_data $ PC1, pca_data $ PC2,
xlim = rng, ylim = rng)
with_thresh <- rec%>%
step_normalize (all_numeric ())%>%
step_pca (all_numeric (), threshold =.99)
with_thresh <- подготовка (with_thresh, обучение = USArrests)
запекать (with_thresh, USArrests)
#> # Стол: 50 x 4
#> ПК1 ПК2 ПК3 ПК4
#>
#> 1 -0,976 1,12 -0,440 0,155
#> 2 -1,93 1,06 2,02 -0,434
#> 3 -1,75 -0,738 0,0542 -0,826
#> 4 0,140 1,11 0,113 -0,181
#> 5 -2,50 -1,53 0,593 -0,339
#> 6 -1,50 -0,978 1,08 0,00145
#> 7 1,34 -1,08 -0.637 -0,117
#> 8 -0,0472 -0,322 -0,711 -0,873
#> 9 -2,98 0,0388 -0,571 -0,0953
#> 10 -1,62 1,27 -0,339 1,07
#> #… С еще 40 строками
приборка (pca_trans, number = 2)
#> # Стол: 1 x 4
#> термины значение идентификатор компонента
#>
#> 1 all_numeric () NA NA pca_PMvd9
аккуратный (pca_estimates, number = 2)
#> # Стол: 16 x 4
#> термины значение идентификатор компонента
#>
#> 1 убийство -0.536 PC1 pca_PMvd9
#> 2 Нападение -0.583 PC1 pca_PMvd9
#> 3 UrbanPop -0.278 PC1 pca_PMvd9
#> 4 Изнасилование -0.543 PC1 pca_PMvd9
#> 5 Убийство 0.418 PC2 pca_PMvd9
#> 6 Нападение 0.188 PC2 pca_PMvd9
#> 7 UrbanPop -0.873 PC2 pca_PMvd9
#> 8 Изнасилование -0.167 PC2 pca_PMvd9
#> 9 Убийство -0.341 PC3 pca_PMvd9
#> 10 Нападение -0.268 PC3 pca_PMvd9
#> 11 UrbanPop -0.378 PC3 pca_PMvd9
#> 12 Изнасилование 0.818 PC3 pca_PMvd9
#> 13 Убийство 0.649 PC4 pca_PMvd9
#> 14 Нападение -0.743 PC4 pca_PMvd9
#> 15 UrbanPop 0.134 PC4 pca_PMvd9
#> 16 Изнасилование 0,0890 PC4 pca_PMvd9
scikit learn - Как рассчитать оптимальное количество функций в PCA (Python)?
scikit learn - Как рассчитать оптимальное количество функций в PCA (Python)? - Переполнение стекаПрисоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено 636 раз
Я выполняю предварительную обработку PCA для набора данных из 78 переменных.Как мне рассчитать оптимальное значение переменных PCA?
- Моя первая мысль заключалась в том, чтобы начать, например, с 5, постепенно увеличивая точность вычислений. Однако по очевидным причинам это не было эффективным средством расчета по времени.
Есть ли у кого-нибудь предложения / опыт? Или даже методику расчета оптимального значения?
Создан 22 сен.
1 Сначала посмотрите на распределение наборов данных, а затем используйте saved_variance_ , чтобы найти количество компонентов.
Упрощенный код:
из sklearn.datasets import fetch_olivetti_faces
из sklearn.decomposition import PCA
импортировать matplotlib.pyplot как plt
x, _ = fetch_olivetti_faces (return_X_y = True)
pca2 = PCA (). fit (x)
plt.plot (pca2.explained_variance_, ширина линии = 2)
plt.xlabel ('Компоненты')
plt.ylabel ("Разъясненные варианты")
plt.show ()
Создан 22 сен.
AhxAhx5,59522 золотых знака1313 серебряных знаков3535 бронзовых знаков
lang-py
Stack Overflow лучше всего работает с включенным JavaScriptВаша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой использования файлов cookie.
Принимать все файлы cookie Настроить параметры
Анализ основных компонентовдля уменьшения размерности в Python
Последнее обновление 18 августа 2020 г.
Уменьшение количества входных переменных для прогнозной модели называется уменьшением размерности.
Меньшее количество входных переменных может привести к более простой модели прогнозирования, которая может иметь лучшую производительность при прогнозировании новых данных.
Возможно, самый популярный метод уменьшения размерности в машинном обучении - это анализ главных компонентов, или сокращенно PCA. Это метод, который исходит из области линейной алгебры и может использоваться в качестве метода подготовки данных для создания проекции набора данных перед подгонкой модели.
В этом руководстве вы узнаете, как использовать PCA для уменьшения размерности при разработке прогнозных моделей.
После прохождения этого руководства вы будете знать:
- Снижение размерности включает уменьшение количества входных переменных или столбцов в данных моделирования.
- PCA - это метод линейной алгебры, который можно использовать для автоматического уменьшения размерности.
- Как оценивать прогнозные модели, использующие проекцию PCA в качестве входных данных, и делать прогнозы с новыми необработанными данными.
Начните свой проект с моей новой книги «Подготовка данных для машинного обучения», включающей пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
- Обновление май / 2020 : Улучшено комментирование кода.
Анализ основных компонентов для уменьшения размерности в Python
Фото: Forest Service, USDA, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на три части; их:
- Уменьшение размерности и PCA
- PCA Scikit-Learn API
- Рабочий пример PCA для уменьшения размерности
Уменьшение размерности и PCA
Уменьшение размерности означает уменьшение количества входных переменных для набора данных.
Если ваши данные представлены в виде строк и столбцов, например, в электронной таблице, то входные переменные - это столбцы, которые передаются в качестве входных данных в модель для прогнозирования целевой переменной. Входные переменные также называются функциями.
Мы можем рассматривать столбцы данных, представляющие измерения в пространстве пространственных признаков n , и строки данных как точки в этом пространстве. Это полезная геометрическая интерпретация набора данных.
В наборе данных с k числовыми атрибутами вы можете визуализировать данные в виде облака точек в k-мерном пространстве…
- страница 305, Интеллектуальный анализ данных: практические инструменты и методы машинного обучения, 4-е издание, 2016 г.
Наличие большого количества измерений в пространстве признаков может означать, что объем этого пространства очень велик, и, в свою очередь, точки, которые у нас есть в этом пространстве (строки данных), часто представляют небольшую и нерепрезентативную выборку.
Это может резко повлиять на производительность алгоритмов машинного обучения, подходящих к данным с множеством входных функций, обычно называемых «проклятием размерности».
Поэтому часто желательно уменьшить количество входных функций.Это уменьшает количество измерений пространства признаков, отсюда и название «уменьшение размерности , ».
Популярный подход к уменьшению размерности - использование методов из области линейной алгебры. Это часто называется «проекция объекта », а используемые алгоритмы - «методы проекции ».
Методы проекции стремятся уменьшить количество измерений в пространстве признаков, сохраняя при этом наиболее важную структуру или отношения между переменными, наблюдаемыми в данных.
При работе с данными большой размерности часто бывает полезно уменьшить размерность, проецируя данные в подпространство более низкой размерности, которое отражает «сущность» данных. Это называется уменьшением размерности.
- стр. 11, Машинное обучение: вероятностная перспектива, 2012 г.
Полученный набор данных, проекция, затем можно использовать в качестве входных данных для обучения модели машинного обучения.
По сути, исходных функций больше не существует, и новые функции создаются на основе имеющихся данных, которые напрямую не сопоставимы с исходными данными, т.е.грамм. не имеют названий столбцов.
Любые новые данные, которые будут вводиться в модель в будущем при прогнозировании, такие как тестовый набор данных и новые наборы данных, также должны быть спроецированы с использованием того же метода.
Анализ главных компонентов, или PCA, может быть самым популярным методом уменьшения размерности.
Наиболее распространенный подход к снижению размерности называется анализом главных компонентов или PCA.
- стр. 11, Машинное обучение: вероятностная перспектива, 2012 г.
Его можно рассматривать как метод проецирования, при котором данные с м -колонками (характеристиками) проецируются в подпространство с m или меньшим количеством столбцов, сохраняя при этом суть исходных данных.
Метод PCA может быть описан и реализован с использованием инструментов линейной алгебры, в частности, матричного разложения, такого как собственное разложение или SVD.
PCA можно определить как ортогональную проекцию данных на линейное пространство меньшей размерности, известное как главное подпространство, так что дисперсия проецируемых данных максимальна
- страница 561, Распознавание образов и машинное обучение, 2006 г.
Для получения дополнительной информации о том, как рассчитывается PCA, см. Учебное пособие:
Теперь, когда мы знакомы с PCA для уменьшения размерности, давайте посмотрим, как мы можем использовать этот подход с библиотекой scikit-learn.
Хотите начать подготовку данных?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
PCA Scikit-Learn API
Мы можем использовать PCA для расчета проекции набора данных и выбора ряда измерений или основных компонентов проекции для использования в качестве входных данных для модели.
Библиотека scikit-learn предоставляет класс PCA, который можно разместить в наборе данных и использовать для преобразования набора данных для обучения и любого дополнительного набора данных в будущем.
Например:
... данные = ... # определить преобразование pca = PCA () # подготовить преобразование в наборе данных pca.fit (данные) # применить преобразование к набору данных transformed = pca.transform (данные)
... data = ... # определить преобразование pca = PCA () # подготовить преобразование в наборе данных pca.fit (data) # применить преобразование к набору данных transformed = pca.transform (data ) |
Выходы PCA можно использовать в качестве входных данных для обучения модели.
Возможно, лучший подход - использовать конвейер, где первым шагом является преобразование PCA, а следующим шагом является алгоритм обучения, который принимает преобразованные данные в качестве входных.
... # определить конвейер шаги = [('pca', PCA ()), ('m', LogisticRegression ())] model = Трубопровод (шаги = шаги)
... # определить конвейер шагов = [('pca', PCA ()), ('m', LogisticRegression ())] модель = конвейер (шаги = шаги) |
Также может быть хорошей идеей нормализовать данные перед выполнением преобразования PCA, если входные переменные имеют разные единицы или масштабы; например:
... # определить конвейер шаги = [('norm', MinMaxScaler ()), ('pca', PCA ()), ('m', LogisticRegression ())] model = Трубопровод (шаги = шаги)
... # определить конвейер шагов = [('norm', MinMaxScaler ()), ('pca', PCA ()), ('m', LogisticRegression ())] model = Трубопровод (шаги = шаги) |
Теперь, когда мы знакомы с API, давайте посмотрим на рабочий пример.
Рабочий пример PCA для уменьшения размерности
Во-первых, мы можем использовать функцию make_classification () для создания синтетической задачи двоичной классификации с 1000 примерами и 20 входными характеристиками, 15 входных данных из которых имеют смысл.
Полный пример приведен ниже.
# тестовый набор данных классификации из sklearn.datasets импортировать make_classification # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7) # резюмируем набор данных печать (X.форма, y.shape)
# набор данных тестовой классификации из sklearn.datasets import make_classification # define dataset X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7000) # = 7000 суммировать набор данныхпечать (X.shape, y.shape) |
При выполнении примера создается набор данных и резюмируется форма входных и выходных компонентов.
Затем мы можем использовать уменьшение размерности для этого набора данных при подборе модели логистической регрессии.
Мы будем использовать конвейер, в котором на первом этапе выполняется преобразование PCA и выбираются 10 наиболее важных измерений или компонентов, а затем для этих функций применяется модель логистической регрессии. Нам не нужно нормализовать переменные в этом наборе данных, так как все переменные имеют одинаковый масштаб по дизайну.
Конвейер будет оцениваться с использованием многократной стратифицированной перекрестной проверки с тремя повторениями и 10 повторениями на повтор.Производительность представлена как средняя точность классификации.
Полный пример приведен ниже.
# оценить pca с помощью алгоритма логистической регрессии для классификации из среднего значения импорта из numpy import std из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.pipeline import Pipeline из склеарна.декомпозиция импорта PCA из sklearn.linear_model import LogisticRegression # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7) # определить конвейер шаги = [('pca', PCA (n_components = 10)), ('m', LogisticRegression ())] model = Трубопровод (шаги = шаги) # оценить модель cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) n_scores = cross_val_score (модель, X, y, оценка = 'точность', cv = cv, n_jobs = -1, error_score = 'поднять') # отчет об эффективности print ('Точность:%.3f (% .3f) '% (среднее (n_scores), std (n_scores)))
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 | # оценить pca с алгоритмом логистической регрессии для классификации из numpy import mean из numpy import std из sklearn.наборы данных импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.pipeline import Pipeline из sklearn.decomposition импорт из sklearn.decomposition 9_model_data00030003 X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7) # определить конвейер шагов = [('pca', PCA (n_components = 10)), ('m', LogisticRegression ())] модель = конвейер (шаги = шаги) # оценить модель cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) n_scores (cross_val_score) , X, y, scoring = 'precision', cv = cv, n_jobs = -1, error_score = 'raise') # report performance print ('Accuracy:%.3f (% .3f) '% (среднее (n_scores), std (n_scores))) |
При выполнении примера оценивается модель и сообщается о точности классификации.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средний результат.
В этом случае мы видим, что преобразование PCA с логистической регрессией достигло производительности около 81.8 процентов.
Как мы узнаем, что сокращение 20 измерений ввода до 10 - это хорошо или лучшее, что мы можем сделать?
Мы не делаем; 10 было произвольным выбором.
Лучший подход - оценить одно и то же преобразование и модель с разным количеством входных функций и выбрать количество функций (степень уменьшения размерности), обеспечивающее наилучшую среднюю производительность.
В приведенном ниже примере выполняется этот эксперимент и обобщается средняя точность классификации для каждой конфигурации.
# сравнить количество компонентов PCA с алгоритмом логистической регрессии для классификации из среднего значения импорта из numpy import std из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.pipeline import Pipeline из sklearn.decomposition import PCA из sklearn.linear_model import LogisticRegression из matplotlib import pyplot # получить набор данных def get_dataset (): X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7) вернуть X, y # получить список моделей для оценки def get_models (): модели = dict () для i в диапазоне (1,21): шаги = [('pca', PCA (n_components = i)), ('m', LogisticRegression ())] модели [str (i)] = Конвейер (шаги = шаги) вернуть модели # оценить данную модель с помощью перекрестной проверки def оценивать_модель (модель, X, y): cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) scores = cross_val_score (модель, X, y, scoring = 'точность', cv = cv, n_jobs = -1, error_score = 'поднять') вернуть баллы # определить набор данных X, y = get_dataset () # получить модели для оценки модели = get_models () # оценить модели и сохранить результаты результаты, имена = список (), список () для имени, модели в моделях.Предметы(): оценки = оценка_модель (модель, X, y) results.append (баллы) names.append (имя) print ('>% s% .3f (% .3f)'% (имя, среднее (баллы), стандартное (баллы))) # построить график производительности модели для сравнения pyplot.boxplot (результаты, метки = имена, showmeans = True) pyplot.xticks (вращение = 45) pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 000 34 35 36 37 38 39 40 41 42 43 44 45 | # сравнить количество компонентов pca с алгоритмом логистической регрессии для классификации из numpy import mean из numpy import std из sklearn.наборы данных импорт make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection импорт RepeatedStratifiedKFold из sklearn.pipeline import Pipeline из sklearn.decomposition импорт из sklearn.decomposition Matrix 9_model # получить набор данных def get_dataset (): X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7) return return X, y # получить список моделей для оценки def get_models (): models = dict () for i in range (1,21): steps = [('pca', PCA (n_components = i)), ('m', LogisticRegression ())] models [str (i)] = Pipeline (steps = steps) return models # оценить данную модель с помощью cross-v alidation def Assessment_model (model, X, y): cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) баллов = cross_val_score (model, X, y, scoring = 'precision', cv = cv, n_jobs = -1, error_score = 'raise') вернуть оценки # определить набор данных X, y = get_dataset () # получить модели для оценки models = get_models () # оценить модели и сохранить результаты результатов, names = list (), list () для имени, модели в моделях.items (): scores = eval_model (model, X, y) results.append (scores) names.append (name) print ('>% s% .3f (% .3f)'% (name, mean (scores), std (scores))) # построить график производительности модели для сравнения pyplot.boxplot (results, labels = names, showmeans = True) pyplot.xticks (вращение = 45) pyplot.show () |
При выполнении примера сначала сообщается о точности классификации для каждого количества выбранных компонентов или функций.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средний результат.
Мы видим общую тенденцию к увеличению производительности по мере увеличения количества измерений. На этом наборе данных результаты предполагают компромисс между количеством измерений и точностью классификации модели.
Интересно, что мы не видим никаких улучшений, кроме 15 компонентов.Это соответствует нашему определению проблемы, где только первые 15 компонентов содержат информацию о классе, а остальные пять являются избыточными.
> 1 0,542 (0,048) > 2 0,713 (0,048) > 3 0,720 (0,053) > 4 0,723 (0,051) > 5 0,725 (0,052) > 6 0,730 (0,046) > 7 0,805 (0,036) > 8 0,800 (0,037) > 9 0,814 (0,036) > 10 0,816 (0,034) > 11 0,819 (0,035) > 12 0,819 (0,038) > 13 0,819 (0.035) > 14 0,853 (0,029) > 15 0,865 (0,027) > 16 0,865 (0,027) > 17 0,865 (0,027) > 18 0,865 (0,027) > 19 0,865 (0,027) > 20 0,865 (0,027)
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 | > 1 0.542 (0,048) > 2 0,713 (0,048) > 3 0,720 (0,053) > 4 0,723 (0,051) > 5 0,725 (0,052) > 6 0,730 (0,046) > 7 0,805 ( 0,036) > 8 0,800 (0,037) > 9 0,814 (0,036) > 10 0,816 (0,034) > 11 0,819 (0,035) > 12 0,819 (0,038) > 13 0,819 (0,035) > 14 0,853 (0,029) > 15 0,865 (0,027) > 16 0.865 (0,027) > 17 0,865 (0,027) > 18 0,865 (0,027) > 19 0,865 (0,027) > 20 0,865 (0,027) |
График в виде прямоугольников и усов создается для распределения оценок точности для каждого настроенного количества измерений.
Мы видим тенденцию повышения точности классификации с увеличением количества компонентов с пределом 15.
Ящичный график количества компонентов PCA в зависимости от точности классификации
В качестве окончательной модели мы можем использовать комбинацию модели преобразования PCA и модели логистической регрессии.
Это включает настройку конвейера на все доступные данные и использование конвейера для прогнозирования новых данных. Важно отметить, что такое же преобразование должно быть выполнено с этими новыми данными, которое обрабатывается автоматически через конвейер.
В приведенном ниже примере показан пример подгонки и использования окончательной модели с преобразованиями PCA для новых данных.
# делать прогнозы с помощью pca с логистической регрессией из sklearn.datasets импортировать make_classification из склеарна.трубопровод импортный трубопровод из sklearn.decomposition import PCA из sklearn.linear_model import LogisticRegression # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 7) # определить модель шаги = [('pca', PCA (n_components = 15)), ('m', LogisticRegression ())] model = Трубопровод (шаги = шаги) # подогнать модель ко всему набору данных model.fit (X, y) # сделать единый прогноз row = [[0.2929949, -4,21223056, -1,288332, -2,17849815, -0,64527665,2,58097719, 0,28422388, -7,1827928, -1.
104,2.73729512,0.81395695,3.96973717, -2.66939799,3.3469232132,4998.40184188, -2.66939799, 334692332, 42.197
# делать прогнозы с использованием pca с логистической регрессией из sklearn.datasets import make_classification из sklearn.конвейерный импорт Pipeline из sklearn.decomposition import PCA из sklearn.linear_model import LogisticRegression # define dataset X, y = make_classification (n_samples = 1000, n_features = 20, n_informative_ randomstate = 5, n_informative = 15, n_informative = 5 7) # определить модель шагов = [('pca', PCA (n_components = 15)), ('m', LogisticRegression ())] model = Pipeline (steps = steps) # fit модель по всему набору данных модель.fit (X, y) # сделать одно предсказание row = [[0.2929949, -4.21223056, -1.288332, -2.17849815, -0.64527665,2.58097719,0.28422388, -7.1827928, -1. 104,2.73795179512,0.8 2.66939799,3.34692332,4.19791821,0.999 , -0.30201875, -4.43170633, -2.82646737,0.44916808]]yhat = model.predict (row) print ('Прогнозируемый класс:% d'% yhat3 [020]) |
При выполнении примера подбирается конвейер для всех доступных данных и делается прогноз на основе новых данных.
Здесь преобразование использует 15 наиболее важных компонентов преобразования PCA, как мы обнаружили в ходе тестирования выше.
Предоставляется новая строка данных с 20 столбцами, которая автоматически преобразуется в 15 компонентов и передается в модель логистической регрессии для прогнозирования метки класса.
Дополнительная литература
Этот раздел предоставляет дополнительные ресурсы по теме, если вы хотите углубиться.
Учебники
Книги
API
Статьи
Сводка
В этом руководстве вы узнали, как использовать PCA для уменьшения размерности при разработке прогнозных моделей.
В частности, вы выучили:
- Снижение размерности включает уменьшение количества входных переменных или столбцов в данных моделирования.
- PCA - это метод линейной алгебры, который можно использовать для автоматического уменьшения размерности.
- Как оценивать прогнозные модели, использующие проекцию PCA в качестве входных данных, и делать прогнозы с новыми необработанными данными.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Получите представление о современной подготовке данных!
Подготовьте данные машинного обучения за считанные минуты
... всего несколькими строками кода Python
Узнайте, как это сделать, в моей новой электронной книге:
Подготовка данных для машинного обучения
Он предоставляет руководств для самообучения с полным рабочим кодом на:
Выбор функций , RFE , Очистка данных , Преобразования данных , Масштабирование , Уменьшение размерности ,
и многое другое...
Используйте современные методы подготовки данных для
ваших проектов машинного обучения
Посмотреть, что внутри
Лицензирование опасных отходов | Агентство по контролю за загрязнением штата Миннесота
Предприятия, некоммерческие организации и правительственные подразделения, которые производят большинство видов опасных отходов на объектах в Миннесоте, должны ежегодно сообщать об этих отходах в Агентство по контролю за загрязнением штата Миннесота (MPCA) или в их столичный округ, вносить плату, и получить лицензию на следующий год.
Столичный округ
Производители опасных отходов в Аноке, Карвере, Дакоте, Хеннепине, Скотте, Рэмси и Вашингтоне лицензированы округом. Если ваш объект расположен в одном из городских округов, свяжитесь с округом для получения информации о местной процедуре лицензирования опасных отходов и требованиях.
Генераторы, не относящиеся к метрополитенам (за пределами столичных округов)
Какие виды опасных отходов подлежат отчетности, оплате и лицензированию?
Не все опасные отходы в Миннесоте подлежат отчетности, сборам или лицензированию.См. Информационный бюллетень об опасных отходах № 1.01, Шаг 1: Оценка отходов (w-hw1-01)
Как и когда мне сообщать об опасных отходах?
Во-первых, убедитесь, что вы получили бесплатный идентификационный номер опасных отходов (HWID) для вашего объекта от MPCA. Этот номер также широко известен как «Идентификационный номер EPA». HWID постоянно присваиваются вашему сайту, а не вам как компании, поэтому, если ваш бизнес переезжает, вы должны получить новый HWID для нового сайта.
Заявки принимаются только после окончания календарного года.Заявки на опасные отходы, образовавшиеся в прошлом году, можно подавать с 1 января по 15 августа. Например, заявку на лицензию производителей опасных отходов на 2020 год можно подать с 1 января по 15 августа 2021 года. Обязательно следуйте всем инструкциям по подаче заявки. Если год подачи заявки был пропущен, отправьте электронное письмо координатору лицензирования опасных отходов: [email protected]
Если на вашем объекте образуется более 100 фунтов опасных отходов, подлежащих регистрации, в течение года, но вы не получаете напоминания о заполнении заявки на лицензию от MPCA, вы все равно несете ответственность за подачу заполненной заявки в MPCA.
Если на вашем объекте образуется 100 фунтов опасных отходов, подлежащих регистрации, или меньше в течение года, или определенные типы переработанных опасных отходов, за которые не взимается ежегодная плата, вам будут реже отправляться напоминания. Генераторы, соответствующие этому описанию, известны как генераторы минимального количества (MiniQG). Заполните заявку на лицензию всякий раз, когда вы получите уведомление с напоминанием, даже если вы считаете, что являетесь MiniQG. Заполненная заявка на лицензию подтверждает ваш статус MiniQG в MPCA и обеспечивает актуальность и точность записей MPCA.
Сколько будут стоить мои лицензионные сборы?
Ваш годовой сбор за опасные отходы рассчитывается на основе количества опасных отходов, которые вы указали в предыдущем календарном году, и того, как эти отходы были обработаны. Все производители опасных отходов, которым требуется лицензия, облагаются ежегодным базовым сбором, который варьируется от года к году в соответствии с целями, установленными Законодательным собранием, который недавно составлял около 600 долларов. Если вы являетесь производителем малых количеств (SQG) или генератором крупных объемов (LQG), вам также будет начислена плата за объем, которая также варьируется от года к году, но в последнее время колеблется от 5 до 10 центов за фунт.
Если вы являетесь MiniQG, вы освобождены от ежегодных лицензионных сборов. В настоящее время MPCA не выдает лицензии на обращение с опасными отходами для MiniQG.
Как и когда мне заплатить комиссию?
Если от вас требуется оплата пошлины, вам будет отправлен счет весной того года, когда вы подадите заявку на лицензию. Вы можете оплатить комиссию онлайн путем электронного снятия с текущего счета (электронный чек), Visa ™ или MasterCard ™ с помощью инструмента онлайн-платежей MPCA или отправить чек по почте на адрес, указанный в счете.Не забудьте оплатить в срок, указанный в счете, в противном случае вам могут быть начислены штрафы за просрочку платежа.
Если у вас возникли трудности с использованием системы онлайн-платежей или у вас есть вопросы по оплате вашего взноса, свяжитесь с сотрудниками MPCA по оплате.
Как получить лицензию?
После того, как вы заплатите взнос, ваша лицензия будет доступна для печати с помощью инструмента MPCA для поиска лицензий на опасные отходы. Вы несете ответственность за посещение этой веб-страницы и распечатку лицензии. Прежде чем вы попытаетесь получить доступ и распечатать лицензию, подождите не менее двух недель, чтобы MPCA получил и обработал ваш платеж.
Разместите свою лицензию в зоне, доступной для широкой публики на лицензированном сайте, например в вестибюле, приемной или стойке обслуживания клиентов. Если на вашем сайте нет областей, открытых для публики, вы можете разместить свою лицензию в общей области для сотрудников.
Если вы не можете загрузить свою лицензию с веб-сайта MPCA, обратитесь в отдел лицензирования MPCA и попросите прислать вам копию вашей лицензии.
Как я могу убедиться, что MPCA имеет правильную информацию об отходах?
Информация о сайте доступна с помощью справочного инструмента MPCA What in My Neighborhood.Вы также можете просмотреть информацию, которую вы отправили через электронную службу MPCA.
Общие вопросы лицензирования опасных отходов
Если ваш объект был закрыт в течение последнего календарного года или позже, вы все равно должны заполнить и подать заявку на лицензию, чтобы сообщать обо всех опасных отходах, образовавшихся в течение этого года.
Чтобы гарантировать, что вы не несете ответственности за любые опасные отходы, образующиеся в будущем на этом объекте, обязательно заполните и отправьте уведомление о регулируемой деятельности с отходами с помощью наших онлайн-сервисов.
Идентификационные номера опасных отходов привязаны к конкретному адресу. Если вы переехали на новый сайт в течение последнего календарного года или позже, получите новый HWID для нового сайта. Вам также необходимо будет деактивировать ваш старый сайт. Инструкции для этого можно найти в следующем документе:
Во-первых, просмотрите информационный бюллетень об опасных отходах № 1.01, Шаг 1: Оценка отходов (w-hw1-01), чтобы убедиться, что вы не производили никаких опасных отходов, подлежащих регистрации, на своем участке. Заполните и отправьте заявку на лицензию с помощью электронной службы MPCA, чтобы убедиться, что вы не производили никаких опасных отходов, подлежащих регистрации, на своем объекте.
Вы можете ввести «0» в столбец суммы для соответствующей строки отходов в заявке на лицензию. Также есть опция флажка в верхней части информации об отходах, которую можно выбрать, если не образовывались опасные отходы.
Ваша лицензия на производство опасных отходов не ограничивает вас каким-либо конкретным размером генератора. В заявке на лицензию сообщайте обо всех опасных отходах, образовавшихся вами в течение последнего календарного года, включая разливы мусора и очистку.
Вам не нужно уведомлять MPCA, если размер вашего генератора увеличивается, хотя вы можете запросить «изменение размера» до вашего обычного размера генератора после разлива или очистки, если захотите.Заполните Уведомление о регулируемой деятельности с отходами онлайн-электронных услуг, чтобы обновить размер генератора.
Помните, что если размер вашего генератора увеличивается из-за необычного события, вы должны соответствовать всем требованиям, предъявляемым к генератору большего размера на те месяцы, которые вы генерировали сверх, даже если размер вашего предприятия может быть изменен. Вы можете получить дополнительную информацию об этих требованиях, просмотрев: Определить размер генератора (w-hw1-02)
Многие переработанные опасные отходы имеют право на освобождение от всех требований по опасным отходам, иногда включая отчетность, если вы документально подтверждаете, что ваши переработанные отходы соответствуют условиям для каждого конкретного исключения.Инструкции по определению того, как именно регулируются ваши переработанные опасные отходы, а также как об этом сообщать и документировать, можно найти в информационном бюллетене по опасным отходам № 2.42, Переработка опасных отходов (w-hw2-42).
Если вы утилизируете и повторно используете определенные опасные отходы на месте, например, в моечной машине для рециркуляции деталей, вы все равно должны сообщать об этих отходах, хотя вы имеете право на сокращение количества отходов, которые вы должны подсчитывать и сообщать.
Вы можете подать апелляцию на сумму начисленного вами сбора. Сначала вы должны оплатить полную сумму счета к установленному сроку, а затем отправить письменное объяснение того, почему вы считаете, что плата была неправильной, в MPCA по адресу, указанному в вашей заявке на лицензию, или отправить электронное письмо персоналу лицензирования MPCA.MPCA рассмотрит ваше дело и при необходимости вернет уплаченный сбор.
Если вы не оплатите взнос в установленный срок, к нему будут добавлены штрафы за просрочку платежа и проценты. Затем ваш гонорар будет отправлен в коллекторское агентство, которое может предпринять любые юридические шаги для взыскания долга. MPCA не сможет выдать вам новую лицензию, и если вы продолжите производить опасные отходы, вас могут привлечь к ответственности за производство опасных отходов без необходимой лицензии.
Ваша предыдущая лицензия будет автоматически продлена до тех пор, пока вы не сможете получить доступ и распечатать новую, если вы подали заявку на лицензию в установленный срок и оплатили сбор.
Дополнительная информация
Свяжитесь с MPCA, если у вас возникнут вопросы относительно вашего приложения, сборов или лицензии.
- Вопросы по лицензированию: [email protected]
- Вопросы о размере вознаграждения: [email protected]
- Вопросы по оплате комиссионных: [email protected]
Дополнительную информацию о выявлении и обращении с опасными отходами в Миннесоте см. На веб-странице MPCA Hazardous Waste Publications.
PCA Provider Agency Регистрация
Исправлено: 3 марта 2021 г.
Как записатьсяЗаявление на участие в программе медицинского обслуживания штата Миннесота (MHCP), входящее в вашу первоначальную организацию по оказанию персональной помощи (PCPO) или персональную помощь (PCA), должно включать все элементы, перечисленные в этом разделе.
Владельцы, управляющие сотрудники и квалифицированные специалисты должны пройти обучение агентства PCA до завершения процесса регистрации. Любые дополнительные бизнес-сайты или местоположения также должны подавать полную заявку.
Поставщики услуг PCPO и PCA Choice должны выполнить следующие действия:
** Сертифицированные Medicare агентства по уходу на дому могут подать заявление Организация - поставщик медицинских услуг (DHS-4016A) (PDF) , если они также предоставляют услуги, отличные от PCA.Если вы предоставляете услуги PCA через зарегистрированное агентство по уходу на дому, они также должны выполнить шаги 2-3 описанного выше процесса регистрации.
Мы обрабатываем формы в порядке даты получения. Независимо от того, регистрируетесь ли вы через портал MPSE или по факсу, дайте 30 дней на обработку. Если нам потребуется дополнительная информация для завершения вашей регистрации, мы отправим запрос на получение дополнительной информации по почте США (или в ваш почтовый ящик MN – ITS, если у вас есть учетная запись) с сообщением о том, что вам нужно сделать, чтобы завершить регистрацию.
ПрограммаMHCP обязана соблюдать окончательные федеральные правила проверки поставщиков медицинских услуг Центрами Medicare и Medicaid Services (CMS).
См. Revalidation в разделе Provider Screening Requirements Руководства для провайдера MHCP для получения дополнительной информации о том, как завершить повторную валидацию.
Отчет об измененияхВы должны сообщать обо всех изменениях, внесенных в записи поставщика, в отдел соответствия требованиям и критериям поставщика MHCP.См. Изменения в регистрации в разделе Регистрация с MHCP Руководства поставщика MHCP.
Текущие требования к отчетностиВы также должны соответствовать текущим требованиям других государственных агентств в отношении предприятий Миннесоты.
Кодов по умолчаниюв PCA | MyFinancial.desktop
Полезно иметь коды TOP по умолчанию, которые можно вставить в запись транзакции вместо неправильных или отсутствующих кодов.FIN дает вам возможность назначать коды TOP для всего кода организации и индивидуального номера бюджета , который будет прикреплен к транзакциям.
Примечание. TOP-коды по умолчанию применяются только тогда, когда статус PCA кода вашей организации равен «A» (активен)
Код FIN TOP по умолчанию
Если вы решите не определять коды по умолчанию, будут использоваться следующие коды по умолчанию системы PCA, которые изначально отображаются в Плане счетов для кода вашей организации:
Код проекта по умолчанию:
- Смещение закрытия проекта: 9999P
- Ограниченный фонд по умолчанию: 99999X
- Сохранение заработной платы по умолчанию: 99999Y
- Непрямые затраты по умолчанию: 99999Z
Код задачи и опции по умолчанию:
- Закрытие (задача или вариант): 99P
- По умолчанию (задача или вариант): 999
FIN Ночная обработка
- Если транзакция правильно закодирована с помощью кода TOP, FIN проверит индекс PCA кода вашей организации и применит код соответствующим образом.
- Если процесс кодирования транзакции подпадает под любую из перечисленных ниже категорий, FIN автоматически применит соответствующий TOP-код по умолчанию:
- , когда транзакция не закодирована с помощью кода TOP.
- , однако, когда транзакция закодирована с помощью кода TOP, значение статуса кода не равно «A» (активен).
- , когда транзакция закодирована с помощью кода проекта, однако код проекта не является проектом «нижнего уровня» в иерархии проектов.
- , когда транзакция закодирована кодом TOP, которого нет в индексе PCA (т.е. написано с ошибкой).
- , когда номер бюджета транзакции отмечен флажком, чтобы указать, что значения по умолчанию не должны использоваться.
- Когда используется код TOP по умолчанию, код редактирования PCA (то есть код ошибки) автоматически применяется к транзакциям.
В каком порядке применяются коды по умолчанию?
- Если значения кода PCA TOP по умолчанию установлены номером бюджета, будут применяться коды бюджета по умолчанию
- Если значения по умолчанию для кода TOP установлены для определенных категорий (трудовые ресурсы, доходы или бюджетные операции), будут применяться значения по умолчанию для этих конкретных категорий.